 一文了解百度被收录ACL 2019的10篇论文
一文了解百度被收录ACL 2019的10篇论文

近日,自然语言处理(NLP)领域的国际顶级学术会议“国际计算语言学协会年会”(ACL 2019)公布了今年大会论文录用结果。根据 ACL 2019 官方数据,今年大会的有效投稿数量达到 2694 篇,相比去年的 1544 篇增长高达 75%。其中,百度共有 10 篇论文被大会收录。
国际计算语言学协会(ACL,The Association for Computational Linguistics)成立于 1962 年,是自然语言处理领域影响力最大、最具活力的国际学术组织之一,自成立之日起就致力于推动计算语言学及自然语言处理相关研究的发展和国际学术交流。百度高级副总裁、AI 技术平台体系 (AIG) 和基础技术体系(TG)总负责人王海峰曾于 2013 年出任 ACL 主席,是 ACL 五十多年历史上首位华人主席,也是 ACL 亚太分会(AACL)的创始主席,ACL 会士。研究论文能够被 ACL 学术年会录用,意味着研究成果得到了国际学术界的认可。
百度被录用的 10 篇论文,覆盖了信息抽取、机器阅读理解、对话系统、视频语义理解、机器翻译等诸多 NLP 领域的热点和前沿研究方向,提出了包括基于注意力正则化的 ARNOR 框架(Attention Regularization based NOise Reduction)、语言表示与知识表示深度融合的 KT-NET 模型、多粒度跨模态注意力机制、基于端到端深度强化学习的共指解析方法等,在人机交互、智能客服、视频理解、机器翻译等场景中具有很大的应用价值。
附:百度被收录 ACL 2019 论文概览
ARNOR: Attention Regularization based Noise Reduction for Distant Supervision Relation Classification
摘要:远监督通过知识库自动获取标注语料,是关系抽取的关键算法。但是远监督通常会引入大量噪声数据,即句子并未表达自动标注的关系。进一步说,基于远监督学习的模型效果不佳、解释性差,无法解释关系的指示词。
为此,我们提出基于注意力正则化的 ARNOR 框架(Attention Regularization based NOise Reduction)。此方法通过注意力机制,要求模型能够关注关系的指示词,进而识别噪声数据,并通过 bootstrap 方法逐步选择出高质量的标注数据,改善模型效果。此方法在关系分类及降噪上均显著优于此前最好的增强学习算法。
应用价值:在文本信息抽取有广泛的应用价值。此方法能够显著降低对标注数据的依赖,实现低成本的基于知识库的自动关系学习,未来可落地在医疗、金融等行业信息抽取中。
Enhancing Pre-trained Language Representations with Rich Knowledge for Machine Reading Comprehension
摘要:机器阅读理解 (Machine Reading Comprehension) 是指让机器阅读文本,然后回答和阅读内容相关的问题。该技术可以使机器具备从文本数据中获取知识并回答问题的能力,是构建通用人工智能的关键技术之一,长期以来受到学术界和工业界的广泛关注。近两年,预训练语言表示模型在机器阅读理解任务上取得了突破性进展。通过在海量无标注文本数据上预训练足够深的网络结构,当前最先进的语言表示模型能够捕捉复杂的语言现象,更好地理解语言、回答问题。然而,正如大家所熟知的,真正意义上的阅读理解不仅要求机器具备语言理解的能力,还要求机器具备知识以支撑复杂的推理。为此,在论文《Enhancing Pre-trained Language Representations with Rich Knowledge for Machine Reading Comprehension》中,百度开创性地提出了语言表示与知识表示的深度融合模型 KT-NET,希望同时借助语言和知识的力量进一步提升机器阅读理解的效果。
KT-NET 的模型架构如下图所示。首先,针对给定的阅读内容和结构化知识图谱,分别利用语言表示模型和知识表示模型对两者进行编码,得到相应的文本表示和知识表示。接下来,利用注意力机制从知识图谱中自动筛选并整合与阅读内容高度相关的知识。最后,通过双层自注意力匹配,实现文本表示和知识表示的深度融合,提升答案边界预测的准确性。截止到发稿日,KT-NET 仍然是常识推理阅读理解数据集 ReCoRD 榜单上排名第一的模型,并在此前很长一段时期内都是 SQuAD 1.1 榜单上效果最好的单模型。
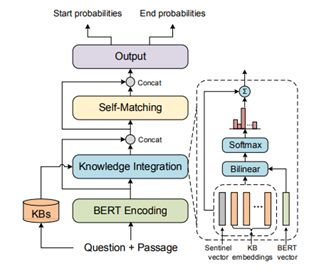
KT-NET: 语言表示与知识表示的深度融合模型
应用价值:该项技术可应用于搜索问答、智能音箱等产品中,直接精准定位用户输入问题的答案,并在搜索结果首条显著位置呈现或通过语音播报呈现给用户。
Know More about Each Other: Evolving Dialogue Strategy via Compound Assessment
摘要:现有的基于监督学习的对话系统,缺乏对多轮回复方向的控制和规划,通常导致对话中发生重复、发散等问题,使得用户的交互体验偏差。 在本文中,我们对多轮对话进行了复合评估 (compound assessment),并基于该评估利用强化学习优化两个自对话 (self-play) 的机器人,促进生成过程中较好地控制多轮对话的方向。考虑到对话的一个主要动机是进行有效的信息交换,针对 Persona Chat 问题(两个人相互对话聊兴趣爱好),我们设计了一个较为完善的评估系统,包括对话的信息量和连贯度两个主要方面。我们利用复合评估作为 reward,基于策略梯度算法 (policy gradient),指导优化两个同构的对话生成机器人之间的对话策略 (dialogue strategy)。该对话策略通过控制知识的选择来主导对话的流向。 我们公开数据集上进行了全面的实验,结果验证了我们提出的方法生成的多轮对话质量,显著超过其他最优方法。
应用价值:可应用于对话系统、智能客服。
Proactive Human-Machine Conversation with Explicit Conversation Goal
摘要:目前的人机对话还处于初级水平,机器大多是被动对话,无法像人类一样进行充分交互。我们提出了基于知识图谱的主动对话任务,让机器像人类一样主动和用户进行对话。对话过程中,机器根据知识图谱主动引领对话进程完成提前设定的话题 (实体) 转移目标,并保持对话的自然和流畅性。为此,我们在电影和娱乐任务领域人工标注 3 万组共 27 万个句子的主动对话语料,并实现了生成和检索的两个主动对话基线模型。
应用价值:可应用于智能音箱中的对话技能,也可以基于此开发闲聊技能,让机器主动发起基于知识图谱的聊天。
Multi-grained Attention with Object-level Grounding for Visual Question Answering
摘要:视觉问答 (VQA) 是一类跨模态信息理解任务,要求系统理解视觉图片信息,并回答围绕图片内容的文本问题。这篇文章提出一种多粒度跨模态注意力机制,在图片 - 句子粒度注意力的基础上,提出更细粒度的物体级别跨模态信息注意力机制,并给出 2 种有效的细粒度信息理解增强的方法。实验表明我们的方法有助于对复杂图像和细小物体的识别,使系统更准确地定位到回答文本问题所依赖的视觉信息,从而显著提升 VQA 准确率。
应用价值:可应用于基于多模态信息和知识图谱的小视频内容理解项目。
Hubless Nearest Neighbor Search for Bilingual Lexicon Induction
摘要:这项基础研究提出了一种提高最近邻搜索的方法。该方法有非常漂亮的理论基础,不仅能显著提升双语词典编纂(Bilingual Lexicon Induction)的准确率,对涉及最近邻搜索的很多任务都有指导意义。
应用价值:机器翻译需要大量对齐的双语文本作为训练数据。这一要求在某些情况下不能被满足,比如小语种文本,专业文献。双语词典编纂在这种情况下能提升翻译系统的准确率。
STACL: Simultaneous Translation with Implicit Anticipation and Controllable Latency
摘要:同声翻译是人工智能领域公认的最难问题之一,已经困扰学术界和工业界几十年了。我们提出了历史上第一个超前预测和可控延迟的同声翻译算法。去年 10 月发布以来,被各大技术外媒广泛报导,包括 MIT 技术评论、IEEE Spectrum、财富杂志等。量子位总结报道:“这是 2016 年百度 Deep Speech 2 发布以来,又一项让技术外媒们如此激动的新进展。”
应用价值:2018 年 11 月的百度世界大会采用了这项同传技术,全程同传翻译了 Robin 所有演讲,延迟仅为 3 秒左右,而之前的整句翻译技术延迟为一整句(可达 10 秒以上)。同时,翻译质量也没有明显的下降。
Simultaneous Translation with Flexible Policy via Restricted Imitation Learning
摘要:本文旨在提高同声翻译的质量。我们去年提出的 STACL 框架(即上述文章 7)虽然简单有效,但有时不够灵活。现在我们提出一种基于模仿学习的同声翻译算法,通过模仿本文设计的动态策略,该模型可以实时灵活地决定是否需要等待更多信息来继续翻译,进而在保持低延迟的情况下提高了翻译质量。
应用价值:该技术可用于同声传译系统。
Robust Neural Machine Translation with Joint Textual and Phonetic Embedding
摘要:该文章旨在提高翻译的鲁棒性,特别是对同音词噪音的鲁棒性。我们在翻译的输入端,通过联合嵌入的方式,加入输入单词对应的发音信息。实验结果表明,该方法不仅大大提高了翻译系统在噪声情况下的鲁棒性,也大幅提高了翻译系统在非噪声情况下的性能。
应用价值:可用于翻译,特别是语音到语音的同声传译系统。语音翻译的一个主要难题是语音识别的错误太多,而这些错误大多是同音词或发音相似的单词,此技术可以很大程度上降低这些来自于语音识别的噪音。
End-to-end Deep Reinforcement Learning Based Coreference Resolution
摘要:共指解析是信息抽取任务中不可或缺的组成部分。近期的基于端到端深度神经网络的方法,往往通过优化启发式的损失函数并做出一系列局部解析决策,缺乏对整个篇章的理解。本文首次提出了基于端到端深度强化学习的共指解析方法,在同一框架内完成指称检测和指称链接,并且直接优化共指解析的评价指标,在 OntoNotes 上取得了良好效果。
应用价值:知可用于识图谱构建,信息抽取。
-
百度
+关注
关注
9文章
2402浏览量
95433 -
论文
+关注
关注
1文章
103浏览量
15457 -
ACL
+关注
关注
0文章
61浏览量
12904
原文标题:史上最大规模ACL大会放榜,百度10篇NLP论文被录用!
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录




评论