 下一代深度学习加速器:英特尔Xe
下一代深度学习加速器:英特尔Xe

在超算领域,中美之间无声的竞争还在进行中,2018年美国凭借橡树岭国家实验室的Summit超算夺回了失落5年的TOP500冠军宝座。在HPC超算市场上,关键的还是下一代百亿亿次超算,也就是Exascale超算,目前中国有三套E级超算,而英特尔、Cray公司在2019年3月17日获得了美国能源部5亿美元的合同。
美国能源部长里克佩里说:“实现百亿亿次超算是必不可少的,它不仅可以提升科学计算,还要改善美国人的日常生活。”“Aurora及下一代百亿亿次超算将HPC、AI等技术应用于癌症研究、气候模拟、退伍军人健康治疗等领域,基于百亿亿次超算的创新将会对我们的社会产生极为重要的影响。”美国首台百亿亿次超算将大量应用英特尔的最新技术,主处理器是下一代Xeon至强,还有新一代Xe加速卡、OptaneDC内存、秘密武器CXL以及英特尔的OneAI软件,而整个系统则是基于Cray公司的Shasta系统,包括至少200个机柜、Slingshot高性能可扩展互联架构及Shasta软件堆栈。
该项目计划在2021年的时间内完成,并且每秒能够进行Quintillion的运算,即400 petaflops。从这个角度来看,这比Million浮点运算高出一百万倍 - 而平均每个处理器的约为200 GFLOP。这笔交易价值5亿美元,其中Cray将获得1.46亿美元的资金,而Intel将获得剩余的3.54亿美元。
图一:Aurora技术革新(图片来源:英特尔)
从上图可以看出Xe 是加速器,但目前还不清楚Quintillionops mark的功率分布。
图二:英特尔GPU可扩展性(来源:英特尔)
英特尔野心勃勃,Xe将从10nm节点开始,为未来几代图形奠定基础,并将遵循Intel的单一堆栈软件哲学,即希望软件开发人员能够利用CPU、GPU、FPGA和AI,所有这些都使用同一套API,英特尔称之为One API,One API作为Direct3D层和GPU之间的中介(据称他们也有Linux解决方案),并允许用户无缝扩展多个GPU。这表明Intel也准备打造一个类似CUDA的生态系统。
图三:英特尔Xe路线图(图片来源:英特尔)
不过这些都不是重点,英特尔将第一次在GPU领域使用MCM封装形式,这正是英伟达梦寐以求的技术,而英特尔即将量产,第一批X2 GPU的暂定时间表也已经公布:2020年6月31日。随后是2021年的X4。看起来Intel计划每年增加两个核心,所以到2024年应该会到X8。
Xe将是英特尔异构计算的关键构成,之前英特尔对GPU加速一直持怀疑态度,但自从有了Xe后,英特尔改变了态度,英特尔Xe将加强英特尔以数据为中心的广泛产品组合,为最广泛的计算工作负载提供领先的产品,满足其对标量、矢量、矩阵和空间计算架构的综合需求。但英特尔并未透露太多细节,不过从Aurora采购Xe即可看出,GPU加速已经被英特尔认同。
目前制造高性能 GPU 有一个很严重的限制 — 「芯片尺寸的限制」,因为目前现有技术的***受限于光刻模板、光刻光源,几乎不可能制造出更大的 GPU 核心,极限是800平方毫米。即使英伟达的技术如何进步,核心尺寸不能无止境变大已经成为英伟达 继续提升 GPU 性能的瓶颈。MCM 的封装方式与 NANDFlash 的做法有点类似,容量不够就将 Layer堆栈起来,除了制造方式简单且具成本优势之外,还可以提高产品的性能。
此外随着CPU核心数逐渐从个位数提升到十位数范围,monolithic多核心的局限越来越大,除了制造难度大、良率低的问题,也因为它不够灵活,因为处理器除了核心数量之外,还要考虑到内存信道、PCIe信道等IO核心的搭配,英特尔的Skylake-SP架构所示,为了配合不同核心的处理器,英特尔在它上面使用了XCC、LCC、HCC三种不同的内部架构,这样做无疑是增加了芯片的复杂性。
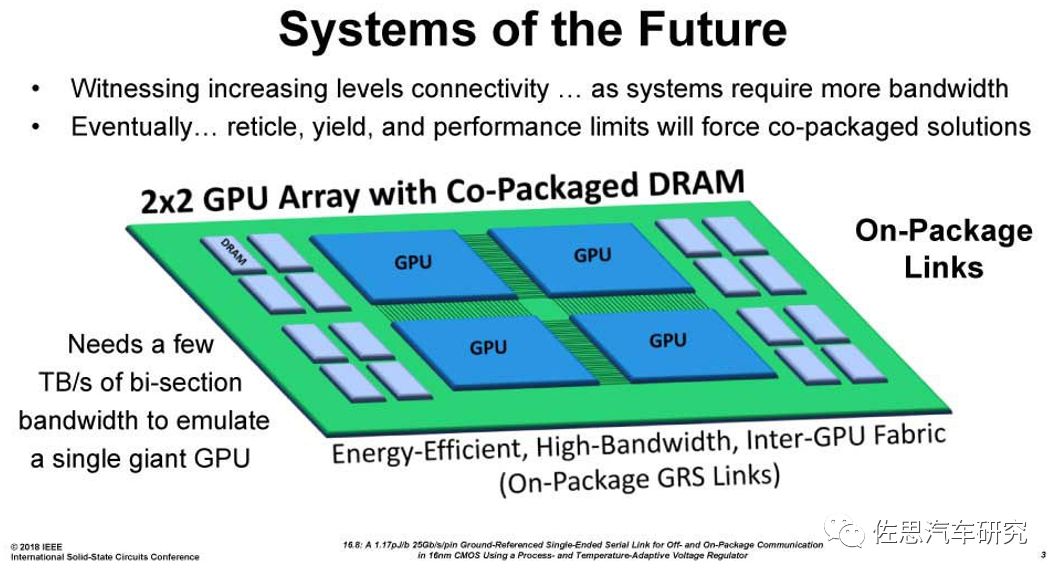
图四:英伟达RC-18 GPU阵列(图片来源:英伟达)
英伟达为了应付 GPU 核心面积的瓶颈,已计划开发一个名为「RC 18」的多矩阵概念,以最优化的方式整合多个 GPU 模块,达至最高流处理器数、减少通讯层级和链路长度,并可以缩小芯片面积。根据英伟达研究部主管 William J. Dally的说法,「RC-18」是为深度学习执行和实现可扩展性的实验,每个芯片内部具有基于TSMC 16nm 工艺及承载 8700 万个晶体管的 16 个 PE(处理组件),因此可以从非常小的尺寸中扩展。16 个 PE 用于控制 CPU Core,片上全局缓冲储存器,并安装了八个 GRS 链路。在实际芯片中,GRS 链路组占据相当大的面积,每芯片 GRS 的 I/O 带宽达到 100 GB/s。
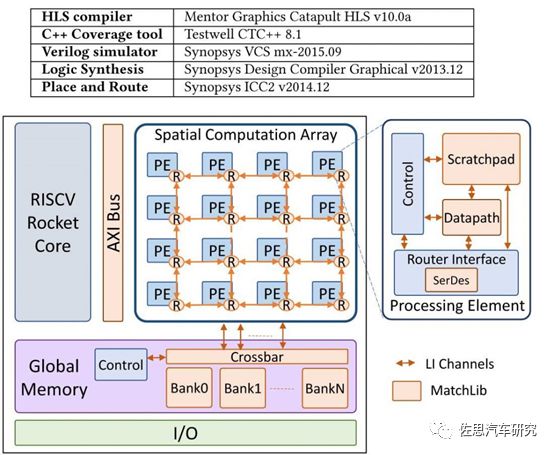
图五:英伟达RC18内部框架图(图片来源:英伟达)
英伟达的RC18概念设计。英伟达目前RC18概念产品只做到了8700万个晶体管,与GPU动辄百亿级晶体管相比,差距至少有5年,目前英伟达将精力全部转移到光线追踪上,靠RT核来做卖点,只字不提曾经信誓旦旦的MCM。而英特尔的MCM成功了,毕竟英特尔在芯片封装领域技术积累远比英伟达要深厚的多。
AMD在CPU上大量运用MCM技术,但是在GPU上始终无法突破量产工艺瓶颈,理论上似乎很简单,但就是良率太低,无法量产。这是因为AMD没有自己的晶圆厂,从未从事过芯片封装,芯片封装都是交给第三方,而英特尔拥有全球最大的晶圆厂,也拥有最优秀的芯片封装工艺,当然这背后是日本厂家新光电气和Ibiden的鼎力支持,日本在封装材料和工艺方面拥有绝对优势。同时英特尔还有自己的Flash存储器晶圆厂。可以借鉴Flash存储器的MCM封装经验。
MCM不仅性能一流,同时也成本大幅度降低,AMD透露,如果将32核封装到一块芯片中成本是1,那它们的MCM方式只有0.59,换言之,节省了41%的成本。MCM还允许一个芯片中使用不同工艺的die(裸晶),比如I/O部分不需要那么先进的工艺,28纳米足够,CPU部分就用7纳米,不仅降低成本,还复用了以前的I/O设计,降低先进制程工艺的风险,研发成果复用率高,缩短研发周期等。

图六:单一架构和MCM对比(图片来源:AMD)
上图为AMD MCM与单芯片对比。
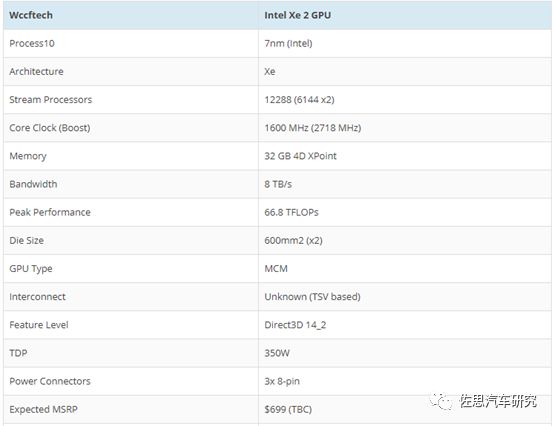
英特尔Xe 2 GPU性能见上表。性价比极高。
为配合MCM,英特尔在软件方面也有所动作,英特尔2019年4月9日举行了Interconnect Day 2019 ,当中详细介绍了处理器与处理器之间的Compute Express Link(CXL)超高速互联新标准。虽然现阶段构思仅供数据中心的服务器使用,显然这也是为GPU准备的。英特尔 CXL 标准的原意——作为 CPU 与 Accelerator 加速器(如 FPGA / GPU 显示适配器)之间的互联通信。
一直以来, CPU 都是透过主板上的 PCIe插槽及 PCIe 协议与显示适配器沟通,但当英特尔 联合阿里巴巴、 Cisco、 Dell EMC 、 Facebook 、 Google 、 HPE 、华为及微软组成强大阵容的联盟后,就发表了 CXL 的开放标准,以解决目前 PCIe 协议于 CPU 与显示适配器之间的高延迟及带宽不足的问题。透过 CXL 协议, CPU 与 GPU 之间就形同连成单一个庞大的堆栈内存池( Stacked Memory ), CPU Cache 和 GPU HBM2 内存犹如放在一起,有效降低两者之间的延迟,故此能大幅提升数据运算效率,令AI人工智能、机器学习、媒体服务、高效能运算( HPC )及云端服务变得非常快速。
MCM没有理论上的突破,突破的只是制造工艺,MCM在奔腾时代已经出现过了,而今monolithic多核已经走到了极限,唯有MCM能救场。而在服务器用CPU领域,MCM将可能是唯一方向,典型的如Cascade Lake-AP 48核处理器,它实际上是两个24核的Cascade Lake处理器通过MCM方式组合出来的,也不是原生48核。如今的MCM多芯片设计在技术水平上也跟当年简单粗暴的胶水多核不一样了,主要担心的延迟问题上,英特尔之前提到他们的EMIB技术相比单片电路的延迟只增加了10%,而别的技术方案中延迟甚至会增加50%之多。
monolithic多核的困境实际上是整个人类面临的瓶颈,近百年来,人类在物理学体系理论上未有任何突破,只是在细枝末节上做修修补补,所谓人工智能不过是概率论,几十年甚至近百年前的理论还是根基,所谓提升,不过是算力成指数倍的堆砌。
另外,供应链的重要性一再凸显,那种追求短平快,强调分工,只做自己擅长的战略长远上必然会遇到无法超越的瓶颈,英伟达和AMD无法战胜英特尔,不再技术层面,而是供应链层面。这么多年以来,AMD都是努力追赶英特尔,但AMD将工厂卖掉之后是个纯粹的Fabless,需要看Foundry晶圆代工厂的脸色,晶圆代工厂自然要优先照顾大客户,台积电自然要优先照顾苹果、华为和高通,遇上产能吃紧,AMD的订单就会往后排。这就意味着AMD的供货不够稳定,或者说AMD无法掌控产量,对下游整机厂来说,有可能导致旺季缺货,这是个致命的缺点,特别是淡旺季分明的笔记本电脑CPU领域,英特尔一直拥有绝对优势。英特尔单靠全球最大的12英寸晶圆产能也足以拥有在半导体领域的霸主位置。
-
英特尔
+关注
关注
61文章
10324浏览量
181095 -
深度学习
+关注
关注
73文章
5608浏览量
124637
原文标题:下一代深度学习加速器:英特尔Xe
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
超越台积电?英特尔首个18A工艺芯片迈向大规模量产

AI工作站本地养龙虾!英特尔双芯混合算力,告别云端Token焦虑

2026英特尔客户高峰论坛:杰和科技以深度协同收获技术跃迁

18A工艺首发!英特尔推出下一代PC处理器,77%游戏性能暴涨+180TOPS算力

英特尔举办行业解决方案大会,共同打造机器人“芯”动脉

科通技术获评英特尔首批尊享级合作伙伴

18A工艺大单!英特尔将代工微软AI芯片Maia 2
英特尔Gaudi 2E AI加速器为DeepSeek-V3.1提供加速支持

Andes晶心科技推出新一代深度学习加速器
硬件与应用同频共振,英特尔Day 0适配腾讯开源混元大模型
主控CPU全能选手,英特尔至强6助力AI系统高效运转

新思科技与英特尔在EDA和IP领域展开深度合作
直击Computex 2025:英特尔重磅发布新一代GPU,图形和AI性能跃升3.4倍

直击Computex2025:英特尔重磅发布新一代GPU,图形和AI性能跃升3.4倍




评论