 谷歌手机重磅推出了一款端到端、全神经、基于设备的语音识别器
谷歌手机重磅推出了一款端到端、全神经、基于设备的语音识别器

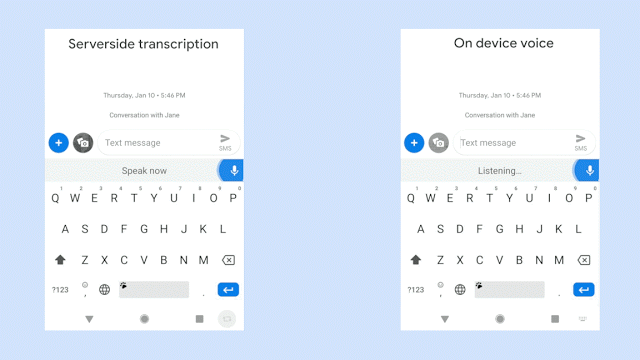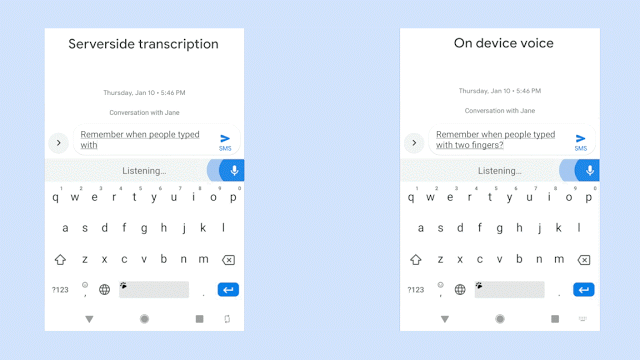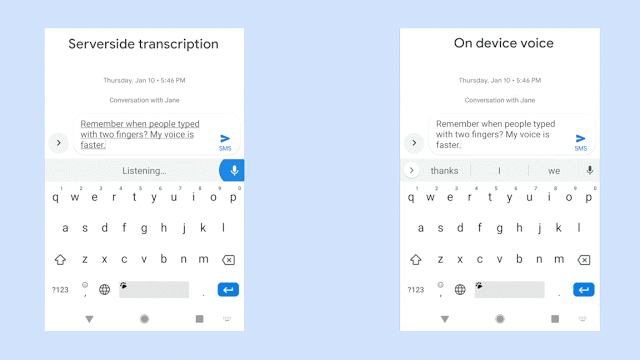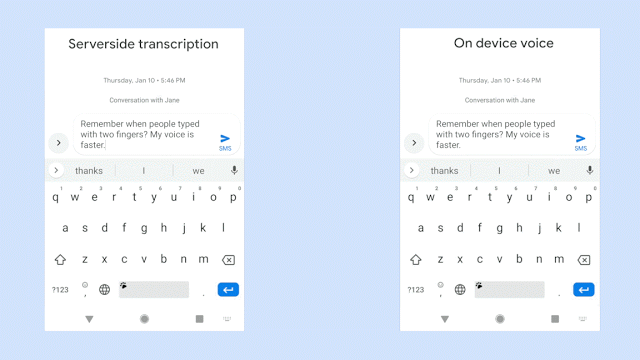
识别延迟一直是设备端语音识别技术需要解决的重大问题,谷歌手机今天更新了手机端的语音识别技术——Gboard,重磅推出了一款端到端、全神经、基于设备的语音识别器,支持Gboard中的语音输入。通过谷歌最新的(RNN-T)技术训练的模型,该模型精度超过CTC,并且只有80M,可直接在设备上运行。
2012年,语音识别研究获得新突破——深度学习可以提高识别的准确性,最早探索这项技术的产品便是谷歌语音搜索了。这标志这语音识别革命的开始,从深层神经网络(DNNs)到递归神经网络(RNNs),长短期记忆网络(LSTMs),卷积网络(CNNs)等等,新的架构和开发质量每年都在快速提升。在发展过程中,识别延迟仍然是攻关难点。
今天,谷歌官方宣布,推出一款端到端、全神经、基于设备的语音识别器,支持Gboard中的语音输入。
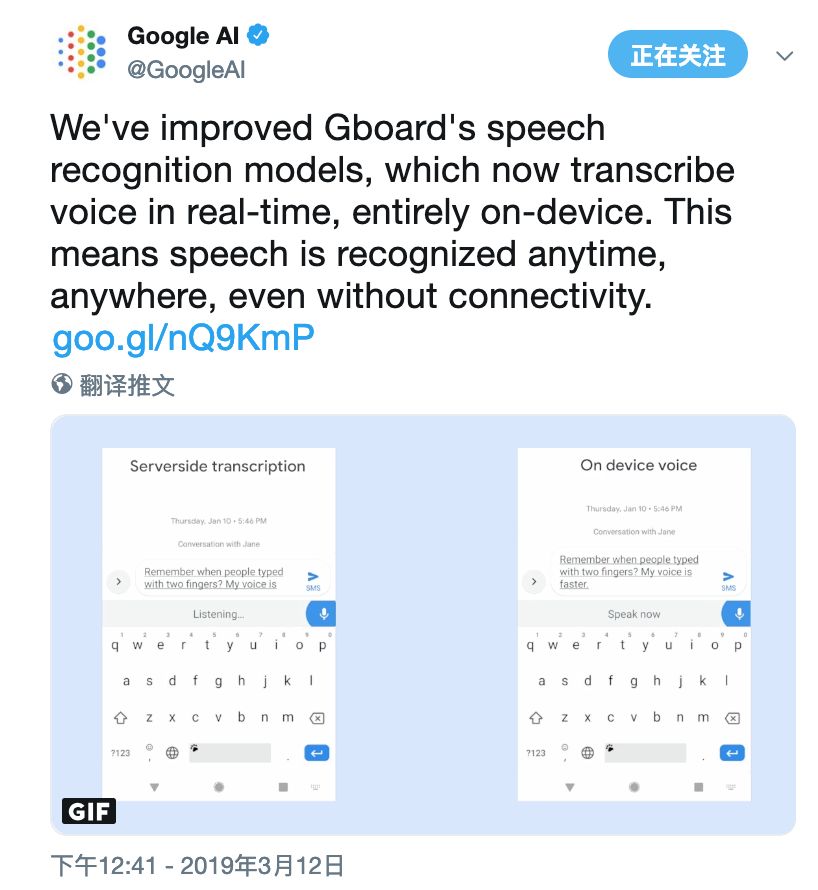
在谷歌最近的论文“移动设备的流媒体端到端语音识别”中,提出了一种使用RNN传感器(RNN-T)技术训练的模型,并且可以在手机上实现。这意味着即使你的手机网络延迟,甚至处于离线状态,新的识别器也始终可用。
谷歌论文下载链接:
https://arxiv.org/abs/1811.06621
该模型以单词级别运行,也就是说,当你说话时,它会逐个字符地输出单词,就像是你自己在敲键盘一样。
语音识别的历史
最初,语音识别系统由这样几个部分组成,将音频片段(通常为10毫秒帧)映射到音素的声学模型,将音素连接在一起形成单词的发音模型,语言模型给出相应的短语。这些组件在早期系统中都是相互独立的。
大约在2014年,研究人员开始专注于训练单个神经网络,将输入音频波形直接映射到输出句子。
也就是说,通过给定一系列音频特征,生成一系列单词或字形来建立学习模型,这种seq2seq模型的出现促进了“attention-based ”和“listen-attend-spell” 模型的进展。
这些模型期望在识别准确度上做出突破,但其需要通检查整个输入序列来工作,并且在输入时不允许输出,这就很难实现实时语音转录了。
几乎同一时间,一个被称为CTC的独立技术出现了,成功解决了识别延时的问题,采用CTC技术也就成为迈向RNN-T架构最重要一步。
递归神经网络传感器
RNN-Ts是一种非注意机制的seq2seq模型。与大多数seq2seq模型(通常需要处理整个输入序列(在我们的例子中是波形)以产生输出(句子))不同,RNN-T可以连续处理输入样本和流输出符号,这种属性对于语音识别尤其友好。在实现过程中,输出符号是字母表的字符。RNN-T识别器会逐个输出字符,并在适当的位置输入空格。它通过反馈循环执行此操作,该循环将模型预测的符号反馈到其中,以预测下一个符号,如下图所示。
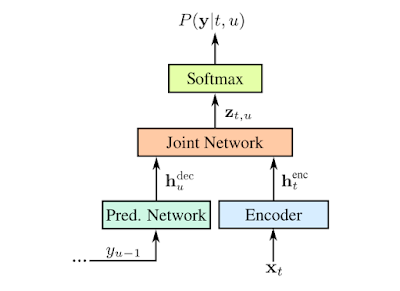
训练这样一只有效运行的模型已经很困难,并且随着我们开发的进展——进一步将单词错误率降低了5%,模型变得更加计算密集。为了解决这个问题,我们开发了并行实现,使得RNN-T损失功能可以在Google的高性能CloudTPU v2硬件上大批量运行。这在训练中实现了约3倍的加速。
离线识别
在传统的语音识别引擎中,我们上面描述的声学、发音和语言模型会被“组合”成一个大的图搜索算法。当语音波形被呈现给识别器时,“解码器”在给定输入信号的情况下,会在该图中搜索相似度最高的路径,并读出该路径所采用的字序列。
通常,解码器采用基础模型的有限状态传感器(FST)表示。然而,尽管有复杂的解码技术,图搜索算法仍然非常之大,以我们的模型为例,可以达到了2GB。如此大的模型根本无法在移动设备上运行,因此这种方法需要在连线时才能正常工作。
为了提高语音识别的有效性,我们试图通过直接在设备上运行新模型,来避免通信网络的延迟和不可靠性。因此,我们的端到端方法不需要在大型解码器图上进行搜索。
相反,只通过单个神经网络的波束搜索进行。我们训练的RNN-T提供与传统的基于服务器的模型相同的精度,但只有450MB,可以更加智能地使用参数和打包信息。然而,即使在今天的智能手机上,450MB也不小了,并且,通过如此庞大的网络传输信号依然很慢。
进一步的,我们通过使用参数量化和混合内核技术来缩小模型,我们在2016年开发了这一技术并在TensorFlow精简版库上公开提供了模型优化工具包。
模型量化相对于训练的浮点模型提供4倍压缩,在运行时提供4倍加速,使我们的RNN-T比单核上的实时语音运行得更快。压缩后,我们模型的最终大小达到了80MB。
终于,当当当,我们的新型设备端神经网络Gboard语音识别器上线了。最初的版本,我们仅提供英语语言,适配所有Pixel手机。鉴于行业趋势,随着专业硬件和算法改进的融合,我们希望这里介绍的技术可以很快用于更多语言和更广泛的应用领域。
-
谷歌
+关注
关注
27文章
6259浏览量
112002 -
语音识别
+关注
关注
39文章
1825浏览量
116255 -
深度学习
+关注
关注
73文章
5610浏览量
124656
原文标题:全离线,无延迟!谷歌手机更新语音识别系统,模型大小仅80M
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
为什么一段式端到端自动驾驶很难落地?

解锁端到端仿真新可能 :全新 aiSim 6 即将发布


晶晨携手谷歌,助力端侧大模型Gemini的硬件落地
端到端与模块化自动驾驶的数据标注要求有何不同?
分享一款高端离线语音识别IC AT680系列
端到端智驾模拟软件推荐——为什么选择Keymotek的aiSim?
端到端语音交互数据 精准赋能语音大模型进阶
当经典IP撞上AI技术:利尔达助力跃然创新推出全球首款端到端AI互动玩具

广和通发布自研端侧语音识别大模型FiboASR
为什么自动驾驶端到端大模型有黑盒特性?




评论