 深度强化学习打造的ANYmal登上Science子刊,真的超越了波士顿动力!
深度强化学习打造的ANYmal登上Science子刊,真的超越了波士顿动力!

深度强化学习开发出的机器人模型通常很难应用到真实环境中,因此机器人开发中鲜少使用该技术。然而这已经板上钉钉了吗?在两天前引发人工智能界关注的 ANYmal 机器人中,其机动性和适应性看起来丝毫不逊色于波士顿动力。其相关论文近期登上了 Science 子刊《Science Robotics》,并且明确指出使用了深度强化学习技术。基于 AI 技术的成功应用,ANYmal 在数据驱动的开发上或许会更有优势。
摘要:足式机器人是机器人学中最具挑战性的主题之一。动物动态、敏捷的动作是无法用现有人为方法模仿的。一种引人注目的方法是强化学习,它只需要极少的手工设计,能够促进控制策略的自然演化。然而,截至目前,足式机器人领域的强化学习研究还主要局限于模仿,只有少数相对简单的例子被部署到真实环境系统中。主要原因在于,使用真实的机器人(尤其是使用带有动态平衡系统的真实机器人)进行训练既复杂又昂贵。本文介绍了一种可以在模拟中训练神经网络策略并将其迁移到当前最先进足式机器人系统中的方法,因此利用了快速、自动化、成本合算的数据生成方案。该方法被应用到 ANYmal 机器人中,这是一款中型犬大小的四足复杂机器人系统。利用在模拟中训练的策略,ANYmal 获得了之前方法无法实现的运动技能:它能精确、高效地服从高水平身体速度指令,奔跑速度比之前的机器人更快,甚至在复杂的环境中还能跌倒后爬起来。
图 1:创建一个控制策略。第一步是确定机器人的物理参数并估计其中的不确定性。第二步是训练一个致动器网络,建模复杂的致动器/软件动力机制。第三步是利用前两步中得到的模型训练一个控制策略。第四步是直接在物理系统中部署训练好的策略。
结果
该视频展示了结果和方法。
基于命令的运动
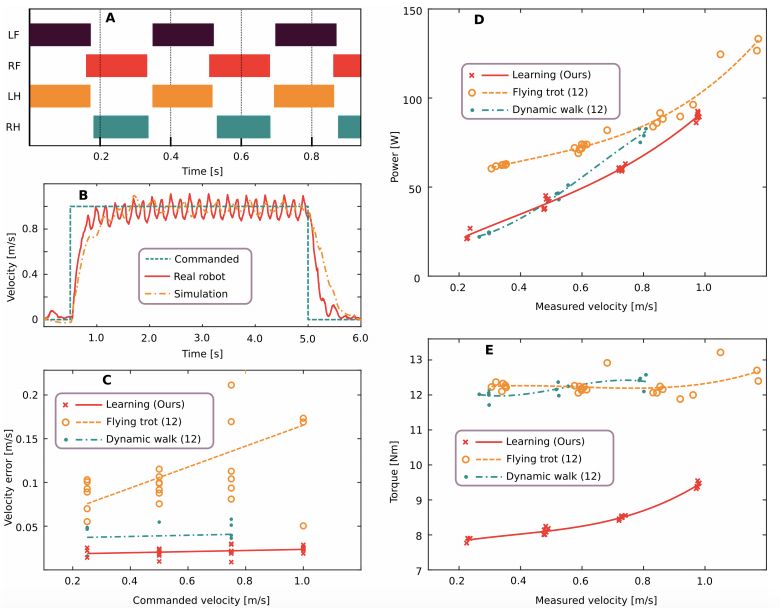
图 2:习得运动控制器的量化评估结果。A. 发现的步态模式按速度指令以 1.0 m/s 的速度运行。LF 表示左前腿,RF 表示右前腿,LH 表示左后腿,RH 表示右后腿。B. 使用本文方法得到的基础速度的准确率。C-E. 本文习得控制器与现有最佳控制器在能耗、速度误差、扭矩大小方面的对比,给定的前进速度指令为 0.25、0.5、0.75 和 1.0 m/s。
高速运动
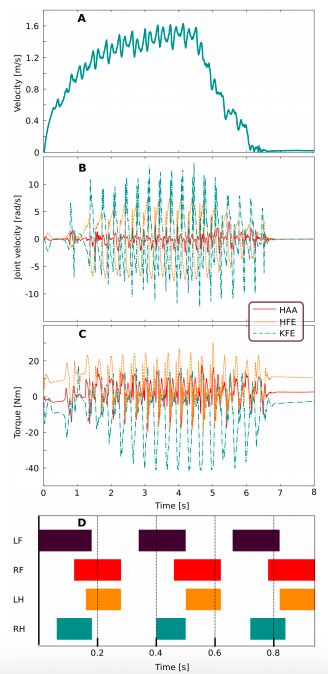
图 3:对高速运动训练策略的评估结果。A. ANYmal 的前进速度。B. 关节速度。C. 关节扭矩。D. 步态模式。
跌倒后的恢复
图 4:在真实机器人上部署的恢复控制器。该研究学到的策略成功使机器人在 3 秒内从随机初始配置中恢复。
材料和方法
这一部分会详细描述模拟环境、训练过程和在物理环境中的部署。图 5 是训练方法概览。训练过程如下:刚体模拟器会根据关节扭矩和当前状态输出机器人的下一个状态。关节速度和位置误差会被缓存在有限时间窗口的关节状态历史中。由带两个隐藏层的 MLP 实现的控制策略会将当前状态和关节状态历史的观察结果映射为关节位置目标。最后,致动器网络会将关节状态历史和关节位置目标映射为 12 个关节扭矩值,然后进入下一个训练循环。
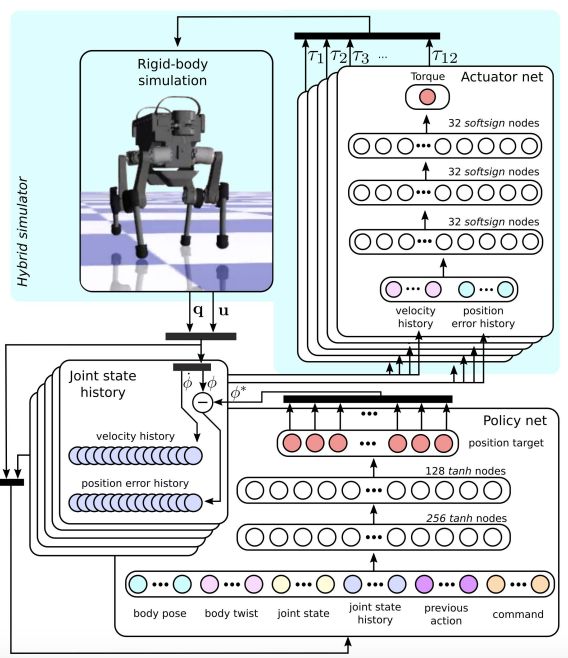
图 5:模拟过程中的训练控制策略。
建模刚体动力机制
为了在合理时间内有效训练复杂的策略,并将其迁移到现实世界,我们需要一种又快又准确的模拟平台。开发行走机器人的最大挑战之一是非连续接触的动力机制建模。为此,研究者使用了之前工作中开发出的刚体接触求解器 [41]。这个接触求解器使用了一个完全遵循库伦摩擦锥约束的硬接触模型。这种建模技术可以准确地捕获一系列刚体和环境进行硬接触时的真实动力机制。该求解器能准确而快速地在台式计算机上每秒生成模拟四足动物的 90 万个时间步。
连接的惯性是从 CAD 模型估计出来的。研究者预期估计会达到 20% 的误差因为没有建模布线和电子器件。为了考虑这些建模不确定性,研究者通过随机采样惯性训练了 30 种不同的 ANYmal 模型来使得策略更加稳健。质心位置、连接的质量和关节位置分别通过添加从 U(−2, 2) cm、U(−15, 15)%、 U(−2, 2) cm 中采样的噪声进行随机化。
建模致动器
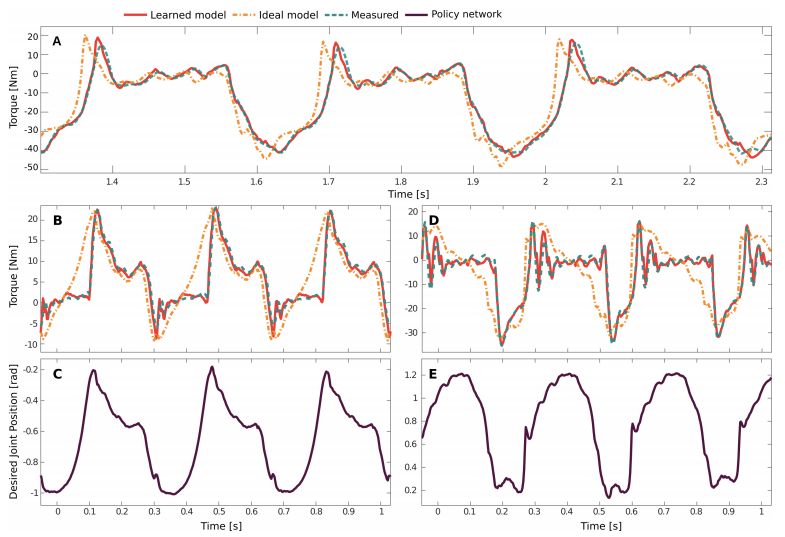
图 6:学得致动器模型的验证结果。
强化学习
研究者展示了离散时间中的控制问题。在每个时间步 t,智能体获取观测结果 o_t ∈O,执行动作 a_t ∈A,获取标量奖励 r_t ∈ ℛ。研究者所指奖励和成本是可以互换的,因为成本就是负的奖励。研究者用 O_t = 〈o_t, o_t − 1, …, o_t − h〉表示近期观测结果的元组。智能体根据随机策略 π(a_t|O_t) 选择动作,该随机策略是基于近期观测结果的动作分布。其目的在于找到在无穷水平中使折扣奖励总和最大化的策略:
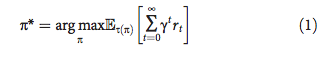
其中 γ ∈ (0, 1) 是折扣因子,τ(π) 是在策略 π 下的轨迹分布(该策略和环境动态下的分布)。在研究设置中,观测结果是评估机器人状态的指标(向控制器提供),动作是向致动器传达的位置命令,奖励是指定的(以诱导感兴趣的行为)。
多种强化学习算法可应用于这个指定策略优化问题。研究者选择了置信域策略优化(TRPO),该算法可在模拟中学习运动策略。它几乎不需要调参,论文中所有学习会话都仅使用默认参数([22, 54] 提供的参数)。研究者使用了该算法的快速自定义实现 [55]。这一高效实现和快速刚体模拟 [41] 可在约 4 小时内生成和处理 2.5 亿状态转换。当该策略的平均性能在 300 个 TRPO 迭代中的改进没有超过任务特定阈值时,学习会话终止。
在物理系统上部署
研究者用 ANYmal 机器人来展示其方法在真实环境中的适用性,如图 1 中步骤 4 所示。ANYmal 是一种体型与狗差不多的四足机器人,重 32kg。每只足约 55 厘米长,且有三个驱动自由度,即髋部外展/内收、髋关节屈/伸、膝关节屈/伸。
ANYmal 有 12 个 SEA。一个 SEA 由一个电动机、一个高传动比传动装置、一个弹性元件和两个旋转编码器组成。它可以测量弹簧偏移和输出位置。在本文中,研究者在 ANYmal 机器人的关节级促动器模块上使用了具有低反馈收益的关节级 PD 控制器。促动器的动态包含多个连续的组件,如下所示。首先,使用 PD 控制器将位置指令转换成期望的扭矩。接着,使用来自期望扭矩的 PID 控制器计算期望电流。然后,用磁场定向控制器将期望电流转换成相电压,该控制器在变速器的输入端产生扭矩。变速器的输出端与弹性元件相连,弹性元件的偏移最终在关节处生成扭矩。这些高度复杂的动态引入了很多隐藏的内部状态,研究者无法直接访问这些内部状态并复杂化其控制问题。
从混合模拟中为训练策略获得参数集后,在真实系统上的部署变得简单多了。定制的 MLP 实现和训练好的参数集被导到机器人的机载 PC 上。当这个网络在 200Hz 时,其状态被评估为基于命令/高速的运动,在 100Hz 时被评估为从坠落中恢复。研究者发现,其性能出人意料地对控制率不敏感。例如,在 20 Hz 时训练恢复运动与在 100 Hz 时性能一致。这可能是因为翻转行为涉及低关节速度(大部分低于 6 弧度/秒)。更动态的行为(如运动)通常需要更高的控制率才能获得足够的性能。实验中使用了更高的频率(100 Hz),因为这样噪音更少。甚至在 100 Hz 时,对网络的评估仅使用了单个 CPU 核上可用计算的 0.25 %。
-
强化学习
+关注
关注
4文章
273浏览量
11997 -
ai技术
+关注
关注
1文章
1315浏览量
25808 -
波士顿动力
+关注
关注
3文章
178浏览量
14054
原文标题:真的超越了波士顿动力!深度强化学习打造的 ANYmal 登上 Science 子刊
文章出处:【微信号:WUKOOAI,微信公众号:悟空智能科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
上汽奥迪E5 Sportback车型升级搭载全新Momenta强化学习大模型
上汽大众ID. ERA 9X全球首发搭载Momenta R7强化学习世界模型
Momenta R6强化学习大模型上车东风日产NX8
Momenta强化学习大模型助力别克至境世家纯电版正式上市
Momenta R7强化学习世界模型即将推出
自动驾驶中常提的离线强化学习是什么?

强化学习会让自动驾驶模型学习更快吗?

多智能体强化学习(MARL)核心概念与算法概览

上汽别克至境E7首发搭载Momenta R6强化学习大模型
Nature传感器新子刊第一篇论文出炉,中国青年学者联手撰写

今日看点:智元推出真机强化学习;美国软件公司SAS退出中国市场
自动驾驶中常提的“强化学习”是个啥?

Meta重磅入局人形机器人,目标打造“机器人界的安卓系统”
爱立信展示AI赋能5G的创新成果
NVIDIA Isaac Lab可用环境与强化学习脚本使用指南




评论