 黑盒监控和白盒监控的区别
黑盒监控和白盒监控的区别

前言
监控是运维的基石,没有监控就像蒙着眼睛开车,不知道车开到哪里了、速度多少、油还剩多少。但监控本身也有讲究:黑盒监控和白盒监控是两种互补的监控方式,很多团队只重视其中一种,导致监控体系存在盲区。
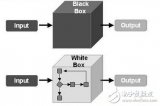
黑盒监控是"外部视角",站在用户角度探测系统是否正常;白盒监控是"内部视角",深入系统内部观察各项指标。很多团队的问题不是没有监控,而是监控不完整——要么只有黑盒(不知道哪里坏了)、要么只有白盒(不知道用户体验如何)。
本文从实战角度,详细讲解这两种监控方式的特点、适用场景、实现方法,以及如何构建完整的监控体系。
1 监控的本质
1.1 什么是监控
监控的核心目的是回答三个问题:
系统现在是否正常?(健康状态)
为什么会不正常?(根因分析)
接下来会不正常吗?(趋势预测)
这对应了监控的三个层次:
用户层面:黑盒监控(外部探测)→ 回答"是否正常" 应用层面:白盒监控(内部指标)→ 回答"为什么" 基础设施:日志、链路追踪 → 回答"哪里有问题"
1.2 常见监控场景
场景一:服务挂了
黑盒监控:告诉你"服务不可用了"
白盒监控:告诉你"CPU 100%,MySQL 连接池耗尽"
两者结合:快速定位是外部故障还是内部问题
场景二:响应变慢
黑盒监控:告诉你"响应时间从 200ms 增加到 2s"
白盒监控:告诉你"GC 频繁、线程阻塞、数据库慢查询"
两者结合:快速找到性能瓶颈
场景三:内存泄漏
黑盒监控:告诉你"进程内存持续增长"
白盒监控:告诉你"内存泄漏点在 XX 模块的 XX 对象"
两者结合:可以预测何时会 OOM,提前处理
2 黑盒监控详解
2.1 什么是黑盒监控
黑盒监控是从用户角度出发,通过主动探测的方式检查系统是否正常。它不关心系统内部实现,只关心输入和输出。
特点:
外部视角:模拟真实用户访问
主动探测:定时发送请求检测
结果导向:只关心成功/失败
协议无关:HTTP、TCP、ICMP、DNS 等
2.2 黑盒监控工具
1. Prometheus Blackbox Exporter:
# prometheus.yml scrape_configs: -job_name:'blackbox-http' metrics_path:/probe params: module:[http_2xx] static_configs: -targets: -https://example.com -https://api.example.com relabel_configs: -source_labels:[__address__] target_label:__param_target -source_labels:[__param_target] target_label:instance -target_label:__address__ replacement:localhost:9115 -job_name:'blackbox-tcp' metrics_path:/probe params: module:[tcp_connect] static_configs: -targets: -localhost:3306 -localhost:6379
# blackbox.yml modules: http_2xx: prober:http timeout:10s http: method:GET headers: User-Agent:PrometheusBlackboxExporter preferred_ip_protocol:ip4 tcp_connect: prober:tcp timeout:5s dns: prober:dns timeout:5s dns: transport_protocol:udp query_name:example.com
2. SmokePing:
# 安装 apt-get install smokeping yum install smokeping # 配置 /etc/smokeping/config *** Targets *** probe = FPing menu = Top title = Network Latency + Network menu = Network Latency title = Network Latency ++ GoogleDNS menu = Google DNS title = Google DNS host = 8.8.8.8 ++ Cloudflare menu = Cloudflare title = Cloudflare host = 1.1.1.1 + WebServices menu = Web Services title = Web Services ++ ExampleSite menu = Example Site title = Example Site host = https://example.com
3. Checkmk / Nagios:
# 定义检查命令
# /etc/nagios4/commands.cfg
definecommand{
command_name check_http
command_line /usr/lib/nagios/plugins/check_http -H$ARG1$ -p$ARG2$ -u$ARG3$ -w$ARG4$ -c$ARG5$
}
define service{
service_description HTTP Check
host_name web-server-1
check_command check_http!example.com!80!/!1!5
use generic-service
check_interval 1
retry_interval 1
}
2.3 HTTP 探测配置
# blackbox.yml - HTTP 探测
modules:
http_2xx:
prober:http
timeout:10s
http:
method:GET
valid_http_versions:
-HTTP/1.1
-HTTP/2
valid_status_codes:
-200
headers:
Host:example.com
no_follow_redirects:false
fail_if_ssl:false
fail_if_not_ssl:false
http_post_2xx:
prober:http
timeout:10s
http:
method:POST
post_data:
-name:query
value:"SELECT 1"
headers:
Content-Type:application/x-www-form-urlencoded
valid_status_codes:
-200
2.4 TCP 探测配置
# TCP 连接探测
modules:
tcp_connect:
prober:tcp
timeout:5s
tcp:
query_response:
-expect:"^220.*"
send:"QUIT"
quit:"
"
mysql_connect:
prober:tcp
timeout:3s
tcp:
query_response:
-expect:"mysql"
probe_interval:30s
redis_connect:
prober:tcp
timeout:3s
tcp:
query_response:
-expect:"redis_version"
2.5 ICMP 探测配置
# ICMP Ping 探测 modules: icmp: prober:icmp timeout:5s icmp: preferred_ip_protocol:ip4 dont_fail_connect:false
2.6 DNS 探测配置
# DNS 探测 modules: dns: prober:dns timeout:5s dns: transport_protocol:udp query_name:example.com query_type:A valid_r_codes: -NOERROR fail_if_not_ip:false
2.7 黑盒监控告警规则
# prometheus/rules/blackbox.yml
groups:
-name:blackbox
rules:
-alert:HTTPProbeFailed
expr:probe_success==0
for:1m
labels:
severity:critical
annotations:
summary:"HTTP 探测失败"
description:"HTTP 探测失败,请检查服务状态"
-alert:HTTPProbeSlow
expr:probe_duration_seconds>5
for:5m
labels:
severity:warning
annotations:
summary:"HTTP 响应慢"
description:"HTTP 响应时间超过 5 秒"
-alert:SSLCertificateExpiring
expr:probe_ssl_earliest_cert_expiry-time()< 86400 * 30
for: 0m
labels:
severity: warning
annotations:
summary: "SSL 证书即将过期"
description: "SSL 证书在 {{ $value | humanizeDuration }} 后过期"
- alert: TCPProbeFailed
expr: probe_success{job="blackbox-tcp"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "TCP 探测失败"
description: "无法连接到 {{ $labels.instance }}"
3 白盒监控详解
3.1 什么是白盒监控
白盒监控是从系统内部收集指标,观测系统运行状态。它依赖于应用和基础设施暴露的指标接口。
特点:
内部视角:深入系统内部
被动收集:应用主动暴露,监控系统拉取
指标导向:丰富的维度指标
根因定位:可以深入分析问题
3.2 常用 Exporter
1. Node Exporter(系统指标):
# 安装 yum install node_exporter systemctlenablenode_exporter systemctl start node_exporter # 默认端口:9100
# prometheus.yml
scrape_configs:
-job_name:'node'
static_configs:
-targets:['localhost:9100']
relabel_configs:
-source_labels:[__address__]
regex:'(.*):9100'
replacement:'${1}:9100'
target_label:instance
2. MySQL Exporter:
# prometheus.yml
scrape_configs:
-job_name:'mysql'
static_configs:
-targets:['localhost:9104']
relabel_configs:
-source_labels:[__address__]
regex:'(.*):9104'
replacement:'${1}'
target_label:instance
# 创建监控用户 CREATE USER'exporter'@'%'IDENTIFIED BY'exporter_password'; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO'exporter'@'%'; # 启动 docker run -d --name mysql-exporter -p 9104:9104 -e DATA_SOURCE_NAME="exporter:exporter_password@(localhost:3306)/" prom/mysqld-exporter
3. Redis Exporter:
# prometheus.yml scrape_configs: -job_name:'redis' static_configs: -targets:['localhost:9121']
# 启动 Redis Exporter docker run -d --name redis-exporter -p 9121:9121 -e REDIS_ADDR="redis://localhost:6379" oliver006/redis_exporter
4. Nginx Exporter:
# 启用 nginx stub_status
# nginx.conf
location /stub_status {
stub_status;
allow 127.0.0.1;
deny all;
}
# 启动 Nginx Exporter
docker run -d
--name nginx-exporter
-p 9113:9113
nginx/nginx-prometheus-exporter
-nginx.scrape-uri=http://localhost/stub_status
3.3 应用指标暴露
Python 应用:
# app.py fromprometheus_clientimportCounter, Histogram, Gauge, start_http_server importrandom # 定义指标 REQUEST_COUNT = Counter('http_requests_total','Total HTTP requests', ['method','endpoint']) REQUEST_LATENCY = Histogram('http_request_duration_seconds','HTTP request latency') ACTIVE_USERS = Gauge('active_users_current','Current number of active users') @app.route("/api/users") defget_users(): REQUEST_COUNT.labels(method='GET', endpoint='/api/users').inc() withREQUEST_LATENCY.time(): # 业务逻辑 users = fetch_users() returnusers if__name__ =="__main__": start_http_server(8000) # 指标暴露在 8000 端口 app.run(host="0.0.0.0", port=8080)
Go 应用:
import(
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var(
httpRequestsTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name:"http_requests_total",
Help:"Total HTTP requests",
},
[]string{"method","endpoint"},
)
httpRequestDuration = prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "http_request_duration_seconds",
Help: "HTTP request duration",
Buckets: prometheus.DefBuckets,
},
[]string{"method","endpoint"},
)
)
funcinit(){
prometheus.MustRegister(httpRequestsTotal)
prometheus.MustRegister(httpRequestDuration)
}
// 使用中间件
funcprometheusMiddleware(next http.Handler)http.Handler{
returnhttp.HandlerFunc(func(w http.ResponseWriter, r *http.Request){
timer := prometheus.NewTimer(httpRequestDuration.WithLabelValues(r.Method, r.URL.Path))
defertimer.ObserveDuration()
httpRequestsTotal.WithLabelValues(r.Method, r.URL.Path).Inc()
next.ServeHTTP(w, r)
})
}
3.4 白盒监控指标分类
基础设施指标:
# 系统资源 -node_cpu_usage:CPU使用率 -node_memory_usage:内存使用率 -node_disk_usage:磁盘使用率 -node_network_receive_bytes:网卡接收字节 -node_network_transmit_bytes:网卡发送字节 -node_load_average:系统负载 # 中间件 -mysql_connection_pool_active:MySQL活跃连接 -mysql_queries_per_second:QPS -redis_memory_used:Redis内存使用 -redis_connected_clients:Redis客户端连接 # 应用层 -http_requests_total:请求总数 -http_request_duration_seconds:请求延迟 -business_orders_total:订单数 -business_revenue_total:营收
3.5 白盒监控告警规则
# prometheus/rules/app.yml
groups:
-name:app-alerts
rules:
-alert:HighCPUUsage
expr:node_cpu_usage>0.9
for:5m
labels:
severity:warning
annotations:
summary:"CPU 使用率过高"
description:"CPU 使用率超过 90%"
-alert:HighMemoryUsage
expr:node_memory_usage>0.9
for:5m
labels:
severity:warning
annotations:
summary:"内存使用率过高"
description:"内存使用率超过 90%"
-alert:HighDiskUsage
expr:node_disk_usage>0.85
for:5m
labels:
severity:warning
annotations:
summary:"磁盘使用率过高"
description:"磁盘使用率超过 85%"
-alert:MySQLSlowQueries
expr:rate(mysql_global_status_slow_queries[5m])>10
for:5m
labels:
severity:warning
annotations:
summary:"MySQL 慢查询过多"
description:"慢查询数超过 10/秒"
-alert:MySQLConnectionPoolExhausted
expr:mysql_connection_pool_active/mysql_connection_pool_max>0.9
for:5m
labels:
severity:critical
annotations:
summary:"MySQL 连接池耗尽"
description:"MySQL 连接池使用率超过 90%"
-alert:HighRequestLatency
expr:histogram_quantile(0.99,rate(http_request_duration_seconds_bucket[5m]))>1
for:5m
labels:
severity:warning
annotations:
summary:"HTTP 请求延迟过高"
description:"P99 延迟超过 1 秒"
4 两种监控的对比
4.1 核心差异
| 维度 | 黑盒监控 | 白盒监控 |
|---|---|---|
| 视角 | 外部/用户视角 | 内部/系统视角 |
| 数据来源 | 主动探测 | 被动收集 |
| 关注点 | 可用性/可达性 | 性能/资源/错误 |
| 故障发现 | 快速 | 深入 |
| 根因定位 | 困难 | 容易 |
| 依赖 | 不需要应用配合 | 需要应用暴露指标 |
| 覆盖范围 | 端到端 | 组件级别 |
4.2 互补关系
用户请求 ↓ [黑盒监控] → 检测到响应超时/失败 ↓ ↓ [白盒监控] → 发现 CPU 100%,GC 频繁,数据库慢查询 ↓ ↓ [日志/链路追踪] → 定位到具体 SQL 和代码位置
4.3 监控覆盖矩阵
| 监控维度 | 黑盒 | 白盒 |
|---|---|---|
| 服务可达性 | - | |
| HTTP 响应码 | ||
| 响应时间 | ||
| DNS 解析 | - | |
| SSL 证书 | - | |
| TCP 连接 | ||
| CPU 使用 | - | |
| 内存使用 | - | |
| 磁盘 I/O | - | |
| 应用错误 | - | |
| 业务指标 | - | |
| JVM GC | - | |
| 数据库查询 | - | |
| 缓存命中率 | - |
5 构建完整监控体系
5.1 监控层次
┌─────────────────────────────────────────────────┐ │ 用户层 │ │ 黑盒监控:HTTP/TCP/ICMP/DNS 探测 │ ├─────────────────────────────────────────────────┤ │ 应用层 │ │ 白盒监控:QPS、延迟、错误率、业务指标 │ ├─────────────────────────────────────────────────┤ │ 中间件层 │ │ 白盒监控:MySQL、Redis、Nginx、Kafka │ ├─────────────────────────────────────────────────┤ │ 系统层 │ │ 白盒监控:CPU、内存、磁盘、网络 │ └─────────────────────────────────────────────────┘
5.2 Prometheus 配置示例
# prometheus.yml
global:
scrape_interval:15s
evaluation_interval:15s
alerting:
alertmanagers:
-static_configs:
-targets:
-alertmanager:9093
rule_files:
-"rules/*.yml"
scrape_configs:
# 黑盒监控
-job_name:'blackbox'
metrics_path:/probe
params:
module:[http_2xx]
static_configs:
-targets:
-https://example.com
-https://api.example.com
relabel_configs:
-source_labels:[__address__]
target_label:__param_target
-source_labels:[__param_target]
target_label:instance
-target_label:__address__
replacement:localhost:9115
# Node Exporter(系统层)
-job_name:'node'
static_configs:
-targets:['localhost:9100']
labels:
env:prod
# MySQL Exporter(中间件层)
-job_name:'mysql'
static_configs:
-targets:['localhost:9104']
labels:
env:prod
# 应用层(自定义指标)
-job_name:'app'
static_configs:
-targets:['localhost:8000']
labels:
env:prod
app:myapp
5.3 Grafana Dashboard
1. 黑盒监控 Dashboard:
{
"title":"Blackbox Monitoring",
"panels": [
{
"title":"HTTP Probe Status",
"type":"stat",
"targets": [
{
"expr":"sum(probe_success{job='blackbox'})",
"legendFormat":"Online"
},
{
"expr":"sum(probe_success{job='blackbox'} == 0)",
"legendFormat":"Offline"
}
]
},
{
"title":"HTTP Response Time",
"type":"timeseries",
"targets": [
{
"expr":"histogram_quantile(0.99, rate(probe_duration_seconds{job='blackbox'}[5m]))",
"legendFormat":"P99"
},
{
"expr":"histogram_quantile(0.95, rate(probe_duration_seconds{job='blackbox'}[5m]))",
"legendFormat":"P95"
}
]
},
{
"title":"SSL Certificate Expiry",
"type":"timeseries",
"targets": [
{
"expr":"probe_ssl_earliest_cert_expiry{job='blackbox'} - time()",
"legendFormat":"{{ instance }} days until expiry"
}
]
}
]
}
2. 系统监控 Dashboard:
{
"title":"System Overview",
"panels": [
{
"title":"CPU Usage",
"type":"gauge",
"targets": [
{
"expr":"avg(node_cpu_usage{instance=~'$instance'}) * 100"
}
],
"fieldConfig": {
"defaults": {
"unit":"percent",
"thresholds": {
"steps": [
{"value":0,"color":"green"},
{"value":70,"color":"yellow"},
{"value":90,"color":"red"}
]
}
}
}
},
{
"title":"Memory Usage",
"type":"gauge",
"targets": [
{
"expr":"avg(node_memory_usage{instance=~'$instance'}) * 100"
}
]
},
{
"title":"Disk Usage",
"type":"gauge",
"targets": [
{
"expr":"node_filesystem_usage{instance=~'$instance', mountpoint='/'}"
}
]
},
{
"title":"Network Traffic",
"type":"timeseries",
"targets": [
{
"expr":"rate(node_network_receive_bytes_total{instance=~'$instance'}[5m])",
"legendFormat":"Receive {{ device }}"
},
{
"expr":"rate(node_network_transmit_bytes_total{instance=~'$instance'}[5m])",
"legendFormat":"Transmit {{ device }}"
}
]
},
{
"title":"Load Average",
"type":"timeseries",
"targets": [
{
"expr":"node_load1{instance=~'$instance'}",
"legendFormat":"1m"
},
{
"expr":"node_load5{instance=~'$instance'}",
"legendFormat":"5m"
},
{
"expr":"node_load15{instance=~'$instance'}",
"legendFormat":"15m"
}
]
}
]
}
5.3 告警策略
SRE 告警分级:
# prometheus/rules/alert-levels.yml
groups:
-name:critical-alerts
interval:30s
rules:
# P1: 服务不可用,需要立即处理
-alert:ServiceDown
expr:probe_success==0
for:1m
labels:
severity:critical
team:oncall
annotations:
summary:"服务不可用"
description:"{{ $labels.instance }}探测失败"
# P1: 大量请求失败
-alert:HighErrorRate
expr:rate(http_requests_total{status=~"5.."}[5m])>0.05
for:2m
labels:
severity:critical
team:oncall
annotations:
summary:"错误率过高"
description:"5xx 错误率超过 5%"
-name:warning-alerts
interval:1m
rules:
# P2: 性能下降,需要关注
-alert:HighLatency
expr:histogram_quantile(0.99,rate(http_request_duration_seconds_bucket[5m]))>2
for:5m
labels:
severity:warning
team:backend
annotations:
summary:"响应延迟过高"
description:"P99 延迟超过 2 秒"
# P2: 资源使用率高
-alert:HighResourceUsage
expr:node_cpu_usage>0.85
for:10m
labels:
severity:warning
team:ops
annotations:
summary:"资源使用率高"
description:"CPU 使用率超过 85%"
5.4 值班告警通知
# alertmanager.yml global: smtp_smarthost:'smtp.example.com:587' smtp_from:'alerts@example.com' route: group_by:['alertname','severity'] group_wait:30s group_interval:5m repeat_interval:4h receiver:'default' routes: -match: severity:critical receiver:'oncall-pager' group_wait:10s repeat_interval:1h -match: severity:warning receiver:'team-notifications' group_wait:1m receivers: -name:'default' email_configs: -to:'team@example.com' -name:'oncall-pager' pagerduty_configs: -service_key:'YOUR_PAGERDUTY_KEY' severity:critical -name:'team-notifications' email_configs: -to:'backend-team@example.com' slack_configs: -api_url:'https://hooks.slack.com/services/XXX' channel:'#alerts'
6 实战案例
6.1 案例:数据库连接池耗尽
故障现象:用户反馈接口超时大量增加
黑盒监控发现:
HTTP Probe: Success (延迟 5s) HTTP Probe: /api/orders 响应超时
白盒监控发现:
MySQL: Connection pool active 100/100 (满) MySQL: Waiting threads 50+ Application: Database query timeout errors increasing
根因:业务代码存在连接泄漏,没有正确释放数据库连接
解决:修复连接释放逻辑,增加连接池监控告警
6.2 案例:DNS 解析故障
故障现象:部分用户无法访问网站
黑盒监控发现:
DNS Probe: SERVFAIL HTTP Probe: Connection refused
白盒监控发现:
Kubernetes DNS pods: Running CoreDNS: Responding slowly
根因:DNS Pod 资源限制过低,高负载时响应缓慢
解决:增加 DNS Pod 资源 limits,优化 DNS 缓存配置
6.3 案例:SSL 证书过期
故障现象:用户反馈 HTTPS 访问被拦截
黑盒监控发现:
SSL Certificate Expiry: -1 days (已过期) SSL Probe: Certificate has expired
白盒监控发现:
无相关指标(证书状态未接入监控)
根因:证书过期未纳入监控,Let’s Encrypt 续期失败
解决:完善证书监控告警,增加证书自动续期
7 监控最佳实践
7.1 指标命名规范
# 使用下划线分隔,小写字母
# 格式: {category}_{name}_{unit}
# 好的命名
http_requests_total
http_request_duration_seconds
disk_usage_bytes
memory_usage_ratio
# 避免的命名
HTTPRequestCount # 大写
ReqCount # 缩写不明确
disk_used # 缺少单位
7.2 标签使用规范
# 使用有意义的标签
# 好的标签
{instance="web-01", env="prod", region="us-east"}
{status="200", method="GET", endpoint="/api/users"}
# 避免的标签
{host="192.168.1.100"} # 使用 instance 代替 IP
{tag="v1"} # 标签含义不明确
7.3 告警阈值设置
# 不要使用固定阈值,使用相对变化
# 好的告警
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) / rate(http_requests_total[5m]) > 0.05
# 相对错误率 5%
- alert: LatencyIncreased
expr: http_request_duration_seconds > 1.5 * http_request_duration_seconds_offset
# 相对基线增长 50%
# 避免的告警
- alert: HighLatency
expr: http_request_duration_seconds > 5
# 固定阈值,不考虑基线差异
7.4 监控覆盖检查清单
# 黑盒监控检查清单 - [ ] HTTP 端点探测(/health, /api/*) - [ ] HTTPS 证书有效期 - [ ] DNS 解析 - [ ] TCP 端口可达性(MySQL, Redis, RabbitMQ) - [ ] 外部依赖服务可用性 # 白盒监控检查清单 - [ ] CPU 使用率 - [ ] 内存使用率 - [ ] 磁盘使用率 - [ ] 网络 I/O - [ ] 进程状态 - [ ] 中间件指标 - [ ] 应用层 QPS - [ ] 应用层延迟 - [ ] 应用层错误率 - [ ] 业务指标
7.5 监控运维检查清单
# 每周检查 - [ ] 告警是否有效触发 - [ ] Dashboard 是否正常展示 - [ ] 监控数据延迟情况 - [ ] 存储容量是否足够 # 每月检查 - [ ] 监控覆盖是否完整 - [ ] 告警阈值是否合理 - [ ] 值班通知是否正常 - [ ] 应急响应流程是否有效 # 每季度检查 - [ ] 监控架构是否需要优化 - [ ] 新服务是否已接入监控 - [ ] 监控文档是否更新
8 总结
8.1 黑盒 vs 白盒监控总结
| 方面 | 黑盒监控 | 白盒监控 |
|---|---|---|
| 核心价值 | 快速发现故障 | 深入分析根因 |
| 回答问题 | "系统正常吗?" | "为什么不正常?" |
| 数据来源 | 主动探测 | 被动收集 |
| 优势 | 覆盖端到端,不依赖应用 | 维度丰富,定位精准 |
| 劣势 | 难以定位根因 | 无法感知用户体验 |
| 推荐工具 | Blackbox Exporter, Smokeping | Prometheus, Grafana |
8.2 完整监控体系组成
┌─────────────────────────────────────────┐ │ 监控体系 │ │ │ │ ┌───────────────┐ ┌───────────────┐ │ │ │ 黑盒监控 │ │ 白盒监控 │ │ │ │ (可用性) │ │ (性能) │ │ │ └───────────────┘ └───────────────┘ │ │ │ │ ┌───────────────┐ ┌───────────────┐ │ │ │ 日志分析 │ │ 链路追踪 │ │ │ │ (详情) │ │ (调用链) │ │ │ └───────────────┘ └───────────────┘ │ │ │ │ ┌─────────────────────────────────────┐│ │ │ 可视化 + 告警 ││ │ │ Grafana + AlertManager ││ │ └─────────────────────────────────────┘│ └─────────────────────────────────────────┘
8.3 实施建议
先黑盒后白盒:先用黑盒监控覆盖核心业务可用性,再逐步完善白盒监控
指标要精不要多:选择关键指标,避免信息过载
告警要准不要多:告警过多会导致告警疲劳,重要告警被忽视
定期审视:每季度审视监控覆盖率和告警有效性
自动化:将监控配置纳入代码管理,实现自动化部署
8.4 常见误区
| 误区 | 正确做法 |
|---|---|
| 只有黑盒监控就够 | 黑盒 + 白盒结合 |
| 监控越多越好 | 关注关键指标 |
| 告警阈值固定不变 | 根据业务基线调整 |
| 监控装上就不用管 | 定期审视和优化 |
| 不监控就不出问题 | 问题早发现早处理 |
监控是运维的基础设施,是保障服务稳定运行的重要手段。合理的监控体系应该让问题在用户感知之前就被发现和解决。希望本文能帮助大家构建完整的监控体系,让监控真正发挥作用。
-
监控
+关注
关注
6文章
2415浏览量
59703 -
内存
+关注
关注
9文章
3258浏览量
76597
原文标题:黑盒监控 vs 白盒监控:你的监控体系缺了哪一环
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录




评论