 面向云计算领域:进迭时空第三代高性能 RISC-V 处理器核 X200 研发完成,性能大幅跃升
面向云计算领域:进迭时空第三代高性能 RISC-V 处理器核 X200 研发完成,性能大幅跃升

进迭时空第三代 RISC-V 处理器核X200 将应用于下一代云计算领域芯片,预计 2027 年正式量产面市。
继 X60(应用于 K1 芯片)、X100(应用于 K3 芯片)一次性成功量产后,进迭时空第三代高性能 RISC-V 处理器核 X200 正式完成研发。相比X100,最新一代X200 在单核性能、向量计算、访存系统、多核互联、虚拟化、安全与RAS等方面持续提升,单核性能达到 16分/GHz@SPEC2006Int。

X200 针对Agent 计算机(Agent Computer)、迷你AI超算(Personal AI Supercomputer)、具身机器人、云计算等场景进行了专项优化,X200主要特性包括:
▲
支持最新的 Profile RVA23.1 标准
▲
最高支持 4x256b 的向量计算
▲
支持 NVFP4、MXFP4 等 AI 常用的浮点数据格式
▲
支持整系统 Hypervisor、机密计算与安全抗攻击能力
▲
单簇至多 12 核互联,单芯片可支持 128 核以上互联
▲
支持簇内 3 层 Cache 结构,且簇内 Cache 最大可支持 32M
▲
面向服务器场景进行 PPA 平衡设计
▲
针对 Agent 场景优化
X200 特性支持:
面向 Agent 应用的针对性优化
X200 在传统云计算处理器核的基础上,面向云端 Agent 应用与旗舰级终端 Agent 应用进行了针对性优化作为一款 6 发射、14 级流水线的超标量乱序高性能 RISC-V 核,SPEC2006Int性能达到 16.0/GHz,单核频率可达 3.3GHz;相比 X100,单位性能提升 100% 以上,达到 50SPEC2006Int/Core。
面向 Agent 的单核性能
进入 Agent 时代后,AI 不再只是一次性完成问答或生成内容,而是需要长期运行、持续感知、调用工具、规划任务、读写记忆、访问数据库并驱动外部系统。这对 CPU 的单线程性能、访存能力、向量能力等提出了更高要求。
X200 基于香山昆明湖架构,在取指、执行、访存等关键路径上进一步完成微架构调整。X200 相比 X100 平均性能全面翻倍,能够为 Agent 系统提供稳定的单核性能支撑。这些优化让 X200 在复杂控制流、解释执行、系统软件和高并发服务场景下具备更好的运行基础,为 Agent 系统中大量“模型之外”的关键路径,如任务规划、工具调用编排、权限检查、结果校验、代码解释执行和检索链路调度等,提供更低延迟的 CPU 支撑。同时,X200 的设计更侧重于面效比的优化,可在硅面积相同的条件下,于多 Agent 场景中提供充足的多核性能。
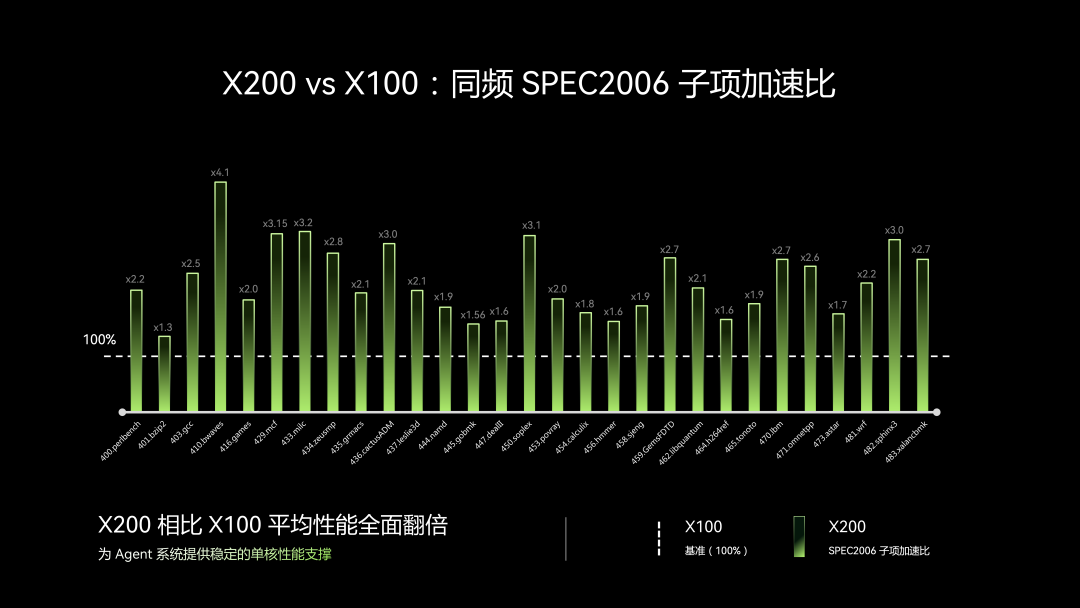
X200 对比 X100 同频情况下的SPEC2006子项加速比
向量优化
X200 支持 RISC-V Vector 及 Vector Crypto 指令集,VLEN 最大支持 1024,数据处理宽度最大支持 4x256b。X200 针对常见应用场景,对向量与 AI 处理能力和能效进行了优化。Agent 系统的计算模式不同于传统 AI 推理,大模型负责核心决策,但大量周边计算需要在 CPU 侧以低延迟、高频次的方式完成。这类计算往往是小批量、强交互、对延迟敏感的,例如请求预处理、排序与过滤、规则判断、压缩解压、加解密、多模态数据转换等任务。这些 Agent 系统中的子任务经常需要由 CPU 以低延迟、低调度成本的方式完成。对于这类大量细粒度、低批量、强交互的 AI 周边计算,X200 能够提供更加灵活的 CPU 侧算力补充。
访存优化
X200 的多核及缓存系统经过系统性重构,增加了 Private L2 与 Cluster Cache,并对两者的访问延迟进行了极致压缩。于此同时,针对应用场景,补充了如链表预取等多种预取策略。此外,X200 单簇最大 Outstanding 能力能够达到 320 笔事务,对外最大访存能力达到 2Kb/cycle。面向 AI 大数据搬运和 Agent 场景,X200 能够更高效地承接上下文管理、检索增强生成、工具调用数据交换和多服务协同中的数据流动,应对多 Agent 协同中高频访存的压力。
服务器特性支持
X200 支持 Smmtt 扩展,为机密计算提供更完整的硬件基础。Smmtt 能够通过硬件划分出不同的 Domain,将中断、物理地址访问进行隔离,配合 IOMMU、IOPMP 等系统组件,进一步隔离普通世界、可信世界、虚拟机与设备 DMA 访问边界,降低高权限软件或外设访问带来的攻击面。对于多租户 Agent 服务和工具执行沙箱,这类能力可以帮助系统在共享硬件资源的同时,建立更清晰的数据与执行隔离边界。X200 也通过 CFI 扩展支持多种内存防护技术,为 AI Agent 隔离以及服务器多用户负载提供基础可信执行环境支持。
同时,X200 支持动态 TSO 技术,让二进制转译在保持较高执行效率的同时,降低软件移植和适配成本,缓解 RISC-V 生态成熟度对服务器场景落地的影响。X200 还在 X100 基础上进一步优化 RAS、Trace、HPM 的实现,增强服务器可管理、可调试、可调优能力,让 Agent 基础设施更容易进入长期稳定运行的生产环境。
基于香山开源生态
X200 基于全球性能最强的开源 RISC-V 处理器核香山开源生态和昆明湖 V2 架构基础,并复用了昆明湖大量开源组件。从建模工具 xs-gem5,到性能调试与分析环境,再到验证工具 NEMU,X200 的研发过程都充分受益于香山已有的工程积累。这使得进迭时空在研发高性能处理器核时,并不是从零开始探索架构与微架构,而是基于一颗 PPA 可验证的开源处理器核进行二次开发。进一步通过微架构和实现的优化,平衡 CPU 核的整体 PPA 表现。
在此基础上,进迭时空 X200 更多面向具体应用领域,根据进迭时空对产品和场景的理解进行二次迭代。昆明湖作为开源处理器核,也提供了大量可对比的性能、面积和功耗数据,使处理器核的问题定位、性能分析和迭代收敛能够更加快速。
量产计划:2027 年芯片面市
高性能处理器核的研发需要经过芯片集成、软件适配、系统验证和量产导入的完整检验。X100 处理器核当前已经跟随进迭时空 K3 芯片实现量产,并在真实落地场景中持续收集系统、软件和应用需求,这为进迭时空 X200 的研发和量产奠定了扎实的工程基础。
在 X100 量产经验的基础上,X200 处理器核目前已经达到可量产状态。进迭时空将在 2027 年推出搭载 X200 的量产芯片,让高性能 RISC-V 芯片进入AI 计算机、Agent 计算机、迷你 AI 超算、具身机器人等高价值应用场景。

X200 FPGA 系统压测
X300 预告:面向下一代超级智算中心
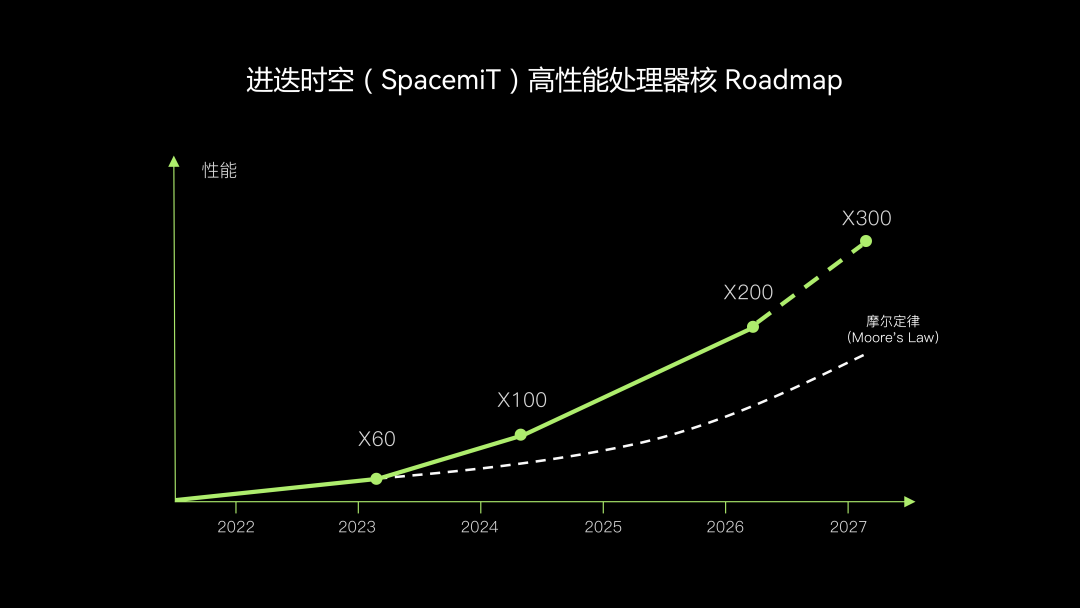
面向未来的超高算力与高阶智能计算场景的发展需求,进迭时空正在以超越摩尔定律的迭代速率进行性能追赶。
目前,进迭时空第四代处理器核 X300 已在研发进程中,预计于 2027 年应用于面向超级智算数据中心场景的量产芯片中,进一步推动 RISC-V 架构应用于下一代云计算基础设施体系。
后续,X300 的研发进展和核心参数,进迭时空将通过官方公众号第一时间向行业及合作伙伴披露。
-
处理器
+关注
关注
68文章
20346浏览量
255387 -
云计算
+关注
关注
39文章
8049浏览量
144846 -
RISC-V
+关注
关注
49文章
2960浏览量
53617 -
进迭时空
+关注
关注
0文章
71浏览量
639
发布评论请先 登录

Canonical 与进迭时空携手:Ubuntu 全面支持 K3/K1 RISC-V AI CPU 计算平台

进迭时空发布新一代RISC-V AI CPU芯片,满足端侧大模型算力需求

十万元奖金池!首届全国RISC-V高水平创新及应用大赛火热进行中
进迭时空与青少年共赴RISC-V AI科技未来!
明晚开播 |开源芯片系列讲座第28期:高性能RISC-V微处理器芯片

2025RISC-V中国峰会|进迭时空RISC-V AI CPU驱动智能化应用发展
知合计算:RISC-V架构创新,阿基米德系列剑指高性能计算

直播预约 |开源芯片系列讲座第28期:高性能RISC-V微处理器芯片



评论