 借助谷歌LiteRT构建下一代高性能端侧AI
借助谷歌LiteRT构建下一代高性能端侧AI

作者 /Lu Wang (Senior Staff Software Engineer)、Chintan Parikh (Senior Product Manager)、Jingjiang Li (Staff Software Engineer)、Terry Heo (Senior Software Engineer)
自 2024 年LiteRT问世以来,我们一直致力于将机器学习技术栈从其 TensorFlow Lite (TFLite) 基础之上演进为一个现代化的端侧 AI (On-Device AI) 框架。虽然 TFLite 为传统端侧机器学习设定了标准,但我们的使命是让开发者能够像过去集成传统端侧机器学习一样,无缝地在设备端部署当今最前沿的 AI (如大语言模型)。
LiteRT https://developers.googleblog.com/en/tensorflow-lite-is-now-litert/
在 2025 Google I/O 大会上,我们曾初步展示了这一演进成果: 一个专为先进硬件加速设计的高性能运行时 (Runtime)。现在,我们很高兴地宣布,这些先进的加速能力已正式并入 LiteRT 生产级技术栈,供所有开发者使用。
这一演进成果 https://developers.googleblog.com/en/litert-maximum-performance-simplified/
这一里程碑巩固了 LiteRT 在 AI 时代作为端侧通用推理框架的地位,相比 TFLite 实现了重大飞跃,其优势体现在:
更快:提供比 TFLite 快 1.4 倍的 GPU 性能,并引入了全新的、最先进的 NPU 加速支持。
更简单:为跨边缘平台的 GPU 和 NPU 加速提供统一、简化的工作流程。
更强大:支持热门的开放模型 (例如 Gemma),以实现卓越的跨平台生成式 AI (GenAI) 部署能力。
更灵活:通过无缝模型转换提供一流的 PyTorch/JAX 支持。
在交付上述所有创新成果的同时,我们仍延续了自 TFLite 以来您所信赖的可靠与跨平台部署体验。
欢迎您继续阅读,了解 LiteRT 如何帮助您构建下一代端侧 AI。
高性能跨平台 GPU 加速
除了在 2025 Google I/O 大会上宣布初步支持 Android GPU 加速之外,我们很高兴地宣布在Android、iOS、macOS、Windows、Linux和 Web上提供全面、综合的 GPU 支持。这一扩展为开发者提供了一个可靠、高性能的加速选项,其扩展能力显著超越了传统的 CPU 推理。
* Python 上的 Windows WebGPU 即将推出
LiteRT 通过ML Drift(我们的下一代 GPU 引擎) 引入对OpenCL、OpenGL、Metal和WebGPU的强大支持,最大限度地扩大了覆盖范围,使您能够跨移动、桌面和 Web 高效部署模型。在 Android 上,LiteRT 进一步优化了这一点: 在可用时自动优先使用 OpenCL 以实现峰值性能,同时保留 OpenGL 支持以实现更广泛的覆盖。
在 ML Drift 的支持下,LiteRT GPU 在效率上实现了显著飞跃,提供了比传统的 TFLite GPU 代理平均快 1.4 倍的性能提升,显著减少了各种模型的延迟。更多基准测试结果请参阅我们之前的文章。
之前的文章 https://developers.googleblog.com/en/litert-maximum-performance-simplified/#:~:text=MLDrift%3A%20Best%20GPU%20Acceleration%20Yet
为了实现高性能 AI 应用,我们还引入了关键的技术升级来优化端到端延迟,特别是异步执行和零拷贝 (zero-copy) 缓冲区互操作性。这些功能显著减少了不必要的 CPU 开销并提高了整体性能,满足了背景分割(Segmentation)和语音识别 (ASR) 等实时用例的严格要求。正如我们的分割示例应用所展示的那样,实际上,这些优化可以带来高达2 倍的性能提升。欢迎参阅我们的技术深度解析以了解更多详细内容。
分割示例应用 https://github.com/google-ai-edge/litert-samples/tree/main/compiled_model_api/image_segmentation/c%2B%2B_segmentation
技术深度解析 https://developers.googleblog.com/en/litert-maximum-performance-simplified/#:~:text=Advanced%20Inference%20for%20Performance%20Optimization
以下示例演示了如何在 C++ 中使用新的CompiledModelAPI 轻松利用 GPU 加速:
// 1. Create a compiled model targeting GPU in C++. autocompiled_model = CompiledModel::Create(env,"mymodel.tflite", kLiteRtHwAcceleratorGpu); // 2. Create an input TensorBuffer that wraps the OpenGL buffer (i.e. from image pre-processing) with zero-copy. autoinput_buffer = TensorBuffer::CreateFromGlBuffer(env, tensor_type, opengl_buffer); std::vectorinput_buffers{input_buffer}; autooutput_buffers = compiled_model.CreateOutputBuffers(); // 3. Execute the model. compiled_model.Run(inputs, outputs); // 4. Access model output, i.e. AHardwareBuffer. autoahwb = output_buffer[0]->GetAhwb();
有关LiteRT 跨平台开发和GPU 加速的更多说明,请访问 LiteRT 官方网站。
LiteRT 跨平台开发
https://ai.google.dev/edge/litert/overview#integrate-model
GPU 加速
https://ai.google.dev/edge/litert/next/gpu
简化 NPU 集成,释放峰值性能
虽然 CPU 和 GPU 为 AI 任务提供了广泛的通用性,但 NPU 却是实现现代应用所需的流畅、响应迅速和高速 AI 体验的关键。然而,数百种 NPU SoC 变体之间的碎片化常常迫使开发者不得不应对由不同编译器和运行时组成的 "迷宫"。此外,由于传统的机器学习基础设施历来缺乏与专用 NPU SDK 的深度集成,导致部署工作流程复杂多变且难以在生产环境中有效管理。
LiteRT 通过提供统一、简化的 NPU 部署工作流程来应对这些挑战,该工作流程抽象了底层的、供应商专用的 SDK,并处理了众多 SoC 变体之间的碎片化。我们已将其简化为一个简单的三步流程,助您轻松实现模型的 NPU 加速部署:
针对目标 SoC 进行 AOT 编译(可选): 使用 LiteRT Python 库为目标 SoC 预编译您的.tflite模型。
通过 Google Play for On-device AI (PODAI) 部署 (Android 专用): 借助 PODAI 服务,自动将模型文件及运行时环境分发至兼容设备。
使用 LiteRT 运行时进行推理: LiteRT 处理 NPU 委托 (delegation),并在需要时提供对 GPU 或 CPU 的稳健回退机制。
有关完整的详细指南,包括 Colab 和示例应用,请查阅我们的LiteRT NPU 文档。
LiteRT NPU 文档
https://ai.google.dev/edge/litert/next/npu
为了提供适合您特定部署需求的灵活集成选项,LiteRT 提供提前编译 (AOT)和端侧即时编译 (JIT)。这使您可以根据应用的独特需求选择最佳策略:
AOT 编译: 最适用于已知目标 SoC 的复杂模型。它最大限度地降低了启动时的初始化耗时和内存占用,以实现 "即时启动" 的体验。
JIT 编译: 最适合在各种平台上分发小规模模型。它不需要准备,尽管首次运行的初始化成本较高。
我们正在与业界领先的芯片制造商紧密合作,为开发者带来高性能 NPU 加速。我们与联发科 (MediaTek)和高通 (Qualcomm)的首批生产就绪型集成方案现已推出。请阅读我们的技术深度解析,了解我们如何实现业界领先的 NPU 性能,其速度比CPU 快 100 倍,比GPU 快 10 倍:
联发科 NPU 和 LiteRT: 赋能下一代端侧 AI
https://developers.googleblog.com/mediatek-npu-and-litert-powering-the-next-generation-of-on-device-ai/
通过 LiteRT 释放高通 NPU 的峰值性能
https://developers.googleblog.com/unlocking-peak-performance-on-qualcomm-npu-with-litert/
△左图: 一个实时、端侧的中文助手,具有视觉和音频多模态功能,由 Gemma 3n 2B 提供支持。运行在搭载联发科天玑 9500 NPU 的 vivo 300 Pro 上。
△右图: 使用 FastVLM 视觉模态进行场景理解,运行在搭载小米 17 Pro Max 的 Snapdragon 8 Elite Gen 5 上。
乘势而上,我们正积极将 LiteRT 的 NPU 支持拓展至更广泛的硬件生态。敬请期待后续公告!
卓越的跨平台 GenAI 支持
开放模型提供了无与伦比的灵活性和定制化能力,但部署它们仍然是一个充满挑战的过程。处理模型底层转换、推理和基准测试的复杂性通常需要大量的工程开销。为了弥合这一差距并使开发者能够高效地构建自定义体验,我们提供了以下集成技术栈:
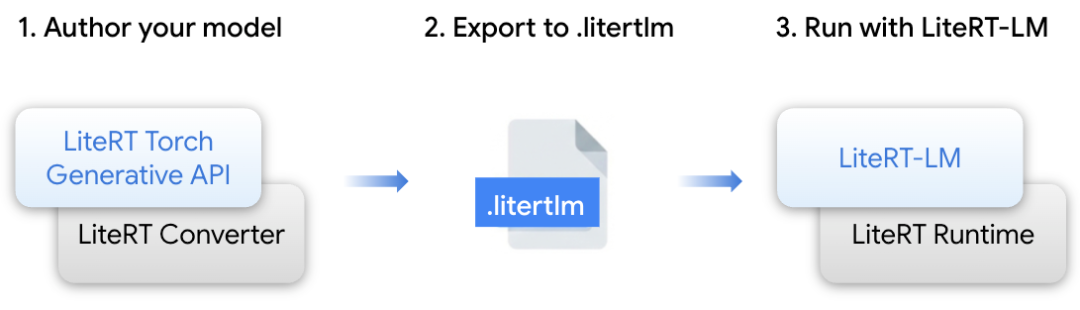
LiteRT Torch Generative API: 一个 Python 模块,旨在实现基于 transformer 的 PyTorch 模型的创作和转换,使其适配 LiteRT/LiteRT-LM 格式。它提供了优化的构建模块,可确保在边缘设备上实现高性能执行。
LiteRT-LM: 一个构建在 LiteRT 之上的专用编排层 (orchestration layer),用于管理大语言模型 (LLM) 特有的复杂性。它是为 Google 产品 (包括 Chrome 和 Pixel Watch) 提供 Gemini Nano 部署支持的经过实战考验的基础设施。
LiteRT 转换器与运行时: 这一基础引擎提供了高效的模型转换、运行时执行和优化,为跨 CPU、GPU 和 NPU 的高级硬件加速赋能,在边缘平台上提供最先进的性能。
LiteRT Torch Generative API https://github.com/google-ai-edge/litert-torch/tree/main/litert_torch/generative
LiteRT-LM https://github.com/google-ai-edge/LiteRT-LM
为 Google 产品 (包括 Chrome 和 Pixel Watch) 提供 Gemini Nano 部署支持 https://developers.googleblog.com/on-device-genai-in-chrome-chromebook-plus-and-pixel-watch-with-litert-lm/
LiteRT 转换器与运行时 https://github.com/google-ai-edge/LiteRT
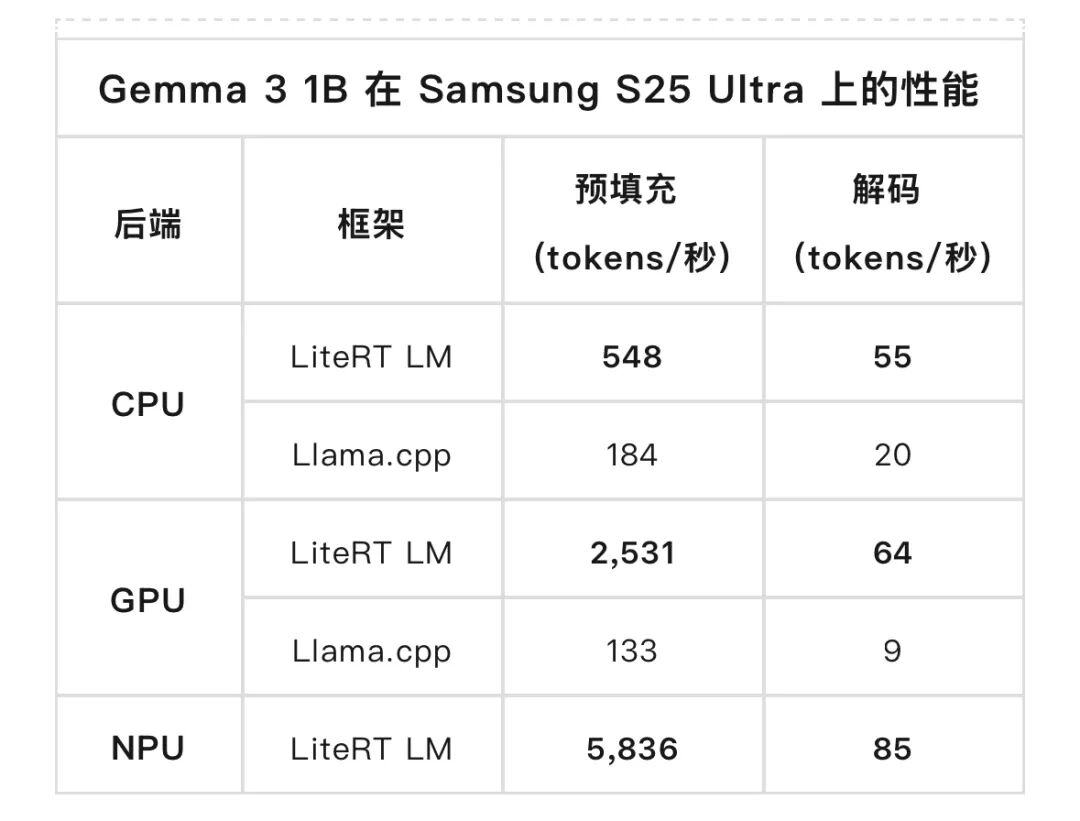
上述这些组件共同为运行热门开放模型提供了具有领先性能的生产级路径。为了证明这一点,我们在 Samsung Galaxy S25 Ultra 上对Gemma 3 1B进行了基准测试,并将 LiteRT 与Llama.cpp进行了比较。
Gemma 3 1B https://huggingface.co/litert-community/Gemma3-1B-IT
Llama.cpp https://github.com/ggml-org/llama.cpp
LiteRT 展现出明显的性能优势,对于解码阶段 (内存密集型),它在CPU上比 llama.cpp 快 3 倍,在GPU 上快 7 倍;对于预填充阶段 (计算密集型),它在GPU 上快 19 倍。此外,LiteRT 的 NPU 加速在预填充阶段比 GPU 额外提升了 2 倍性能,从而充分释放了计算硬件的潜力。要详细了解这些基准测试背后的工程技术,请阅读我们对LiteRT 幕后优化的深入探讨。
LiteRT 幕后优化
https://developers.googleblog.com/gemma-3-on-mobile-and-web-with-google-ai-edge/#:~:text=current%20activity%20level.-,Under%20the%20hood,-The%20performance%20results
LiteRT 支持广泛且持续增长的主流开放权重模型,这些模型经过精心优化和预转换,可立即部署,包括:
Gemma 模型系列: Gemma 3 (270M、1B)、Gemma 3n、EmbeddingGemma 和 FunctionGemma。
Qwen、Phi、FastVLM等。
△AI Edge Gallery 应用演示,由 LiteRT 提供支持: TinyGarden (左) 和 Mobile Actions (右),使用FunctionGemma构建。
这些模型可在LiteRT Hugging Face 社区获取,并通过Android和iOS上的Google AI Edge Gallery 应用进行交互式探索。
LiteRT Hugging Face 社区 https://huggingface.co/litert-community
Android https://play.google.com/store/apps/details?id=com.google.ai.edge.gallery
iOS https://testflight.apple.com/join/nAtSQKTF
Google AI Edge Gallery 应用 https://github.com/google-ai-edge/gallery
更多开发细节,请参阅我们的LiteRT GenAI 文档。
LiteRT GenAI 文档
https://ai.google.dev/edge/litert/genai/overview
广泛的机器学习框架支持
部署不应受限于您所选用的训练框架。LiteRT 提供来自业界最主流机器学习框架的无缝模型转换:PyTorch、TensorFlow 和 JAX。
PyTorch 支持: 借助AI Edge Torch 库,您可以将 PyTorch 模型通过一个简化的步骤直接转换为.tflite格式。这确保了基于 PyTorch 的架构可以立即充分利用 LiteRT 的高级硬件加速,省去了对复杂中间转换的需求。
TensorFlow 和 JAX: LiteRT 持续为 TensorFlow 生态系统提供强大、一流的支持,并通过jax2tf桥接工具为 JAX 模型提供可靠的转换路径。这确保了来自 Google 任何核心机器学习库的最先进研究都可以高效地部署到数十亿设备上。
AI Edge Torch 库
https://github.com/google-ai-edge/ai-edge-torch
通过整合这些路径,无论您的开发环境如何,LiteRT 都能支持从研究到生产的快速实现。您可以在首选框架中构建模型,并依赖 LiteRT 在 CPU、GPU 和 NPU 后端上实现卓越的性能交付。
要开始使用,请探索AI Edge Torch Colab并亲自尝试转换过程,或在此技术深度解析中深入了解我们 PyTorch 集成的技术细节。
AI Edge Torch Colab https://ai.google.dev/edge/litert/conversion/pytorch/overview
技术深度解析 https://developers.googleblog.com/en/ai-edge-torch-high-performance-inference-of-pytorch-models-on-mobile-devices/
值得信赖的可靠性和兼容性
尽管 LiteRT 的能力已显著扩展,但我们对长期可靠性和跨平台一致性的承诺保持不变。LiteRT 继续建立在久经考验的.tflite模型格式之上,这是一种行业标准的单文件格式,可确保您现有的模型在 Android、iOS、macOS、Linux、Windows、Web 和 IOT 上保持可移植性和兼容性。
为了向开发者提供持续的体验,LiteRT 为现有的和下一代推理路径提供了强大的支持:
Interpreter API: 您现有的生产模型将继续可靠运行,保持您所依赖的广泛设备覆盖范围和坚如磐石的稳定性。
新的 CompiledModel API: 此现代化接口专为下一代 AI 设计,提供了无缝路径来释放GPU和 NPU 加速的全部潜力,以满足日益演进的新 AI 需求。有关选择 CompiledModel API 的更多原因,请参阅文档。
文档
https://ai.google.dev/edge/litert/inference#why-compiled-model
未来计划
准备好构建端侧 AI 的未来了吗?欢迎您查看相关资料,轻松上手:
探索LiteRT 文档以获取全面的开发指南。
查看LiteRT GitHub和LiteRT 示例 Github以获取示例代码和实现细节。
访问LiteRT Hugging Face 社区以获取 Gemma 等即用型开放模型,并在Android和iOS上试用Google AI Edge Gallery 应用来体验实际运行中的 AI。
LiteRT 文档 https://ai.google.dev/edge/litert
LiteRT GitHub https://github.com/google-ai-edge/litert
LiteRT 示例 Github https://github.com/google-ai-edge/litert-samples
LiteRT Hugging Face 社区 https://huggingface.co/litert-community
Android https://play.google.com/store/apps/details?id=com.google.ai.edge.gallery
iOS https://testflight.apple.com/join/nAtSQKTF
Google AI Edge Gallery 应用 https://github.com/google-ai-edge/gallery
欢迎您通过GitHub 频道与我们进行交流,让我们了解您的反馈和功能请求。我们迫不及待地想看到您用 LiteRT 创造出的精彩内容!也欢迎您持续关注 "谷歌开发者" 微信公众号,及时了解更多开发技术和产品更新等资讯动态。
GitHub 频道
https://github.com/google-ai-edge/LiteRT/issues
致谢
感谢团队成员和所有合作者为本次发布中取得的进步所做的贡献: Advait Jain, Andrew Zhang, Andrei Kulik, Akshat Sharma, Arian Arfaian, Byungchul Kim, Changming Sun, Chunlei Niu, Chun-nien Chan, Cormac Brick, David Massoud, Dillon Sharlet, Fengwu Yao, Gerardo Carranza, Jingjiang Li, Jing Jin, Grant Jensen, Jae Yoo, Juhyun Lee, Jun Jiang, Kris Tonthat, Lin Chen, Lu Wang, Luke Boyer, Marissa Ikonomidis, Matt Kreileder, Matthias Grundmann, Majid Dadashi, Marko Ristić, Matthew Soulanille, Na Li, Ping Yu, Quentin Khan, Raman Sarokin, Ram Iyengar, Rishika Sinha, Sachin Kotwani, Shuangfeng Li, Steven Toribio, Suleman Shahid, Teng-Hui Zhu, Terry (Woncheol) Heo, Vitalii Dziuba, Volodymyr Kysenko, Weiyi Wang, Yu-Hui Chen, Pradeep Kuppala 和 gTech 团队。
-
Android
+关注
关注
12文章
4035浏览量
134520 -
gpu
+关注
关注
28文章
5282浏览量
136085 -
AI
+关注
关注
91文章
41283浏览量
302658
原文标题:LiteRT | 释放极致潜能,构建下一代高性能端侧 AI
文章出处:【微信号:Google_Developers,微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Kapsch TrafficCom借助TomTom Traffic打造下一代智能出行产品
FT 5000 Smart Transceiver:下一代智能网络芯片的卓越之选
伟创力携手博通,推进下一代AI液冷解决方案落地

AMD 推出第二代 Kintex UltraScale+ 中端FPGA,助力智能高性能系统

晶晨携手谷歌,助力端侧大模型Gemini的硬件落地
借助谷歌FunctionGemma模型构建下一代端侧智能体

安霸半导体加速推进下一代无人机端侧AI创新
泰凌微:布局端侧AI,产品支持谷歌LiteRT、TVM开源模型
高算力、低功耗!下一代端侧AI芯片排队进场
AI眼镜或成为下一代手机?谷歌、苹果等巨头扎堆布局
Microchip推出下一代Switchtec Gen 6 PCIe交换芯片
AI体验跃迁,天玑9500用双NPU开创端侧AI新时代

玄铁下一代旗舰处理器C930:双算力引擎,助力 RISC-V高性能计算
端侧AI需求大爆发!安谋科技发布新一代NPU IP,赋能AI终端应用



评论