 FPGA和GPU加速的视觉SLAM系统中特征检测器研究
FPGA和GPU加速的视觉SLAM系统中特征检测器研究

特征检测是SLAM系统中常见但耗时的模块,随着SLAM技术日益广泛应用于无人机等功耗受限平台,其效率优化尤为重要。本文首次针对视觉SLAM流程开展硬件加速特征检测器的对比研究,通过对比现代SoC平台(NvidiaJetson Orin与AMD Versal)上最佳GPU加速方案(FAST、Harris、SuperPoint)与对应FPGA加速方案的性能,得出全新结论。
• 文章:
Accelerated Feature Detectors for Visual SLAM: A Comparative Study of FPGA vs GPU
• 作者:
Ruiqi Ye, Mikel Luján
• 论文链接:
https://arxiv.org/abs/2510.13546
• 编译:
INDEMIND
01 本文核心内容
图像特征检测一直是计算机视觉和机器人领域的重要研究方向,并且在图像分类、目标检测、视觉里程计(VO)和SLAM等更复杂的算法中发挥着基础性作用。这些任务有时需要部署在边缘平台上,例如自主无人机和机器人。边缘平台通常使用电池供电,因此受到能源效率的限制。然而,仅使用带有嵌入式微控制器(例如Arm、RISC-V)的系统级芯片(SoC)的边缘平台往往无法满足这些复杂任务的严格要求。
另一方面,高端图形处理单元(GPU)是计算机视觉和机器人研究人员广泛使用的加速器,以实现实时性能。集成到现代SoC中的嵌入式GPU,例如Nvidia Jetson系列产品,使机器人系统更加节能。
带有嵌入式GPU的节能SoC并非唯一能够加速特征检测的边缘平台。集成现场可编程门阵列(FPGA)的SoC也广泛可用。集成FPGA的SoC能够为特定算法提供定制硬件加速,而无需通过PCIe/CXL传输数据。这种平台在用于视觉SLAM硬件加速方面的研究程度不如GPU。
尽管文献中有许多进展,但特征检测仍然计算密集,因为这些算法往往要对图像中的每个像素进行迭代,提取特征点。例如,流行的ICE-BA在其视觉SLAM流水线的前端使用FAST特征检测器。图1展示了在Nvidia Jetson Orin、AMD VCK190和配备Intel Xeon芯片的工作站上,使用EuRoC数据集的MachineHall序列对ICE-BA定位线程进行性能分析的结果。运行时间分为三个模块:预处理、FAST特征检测器和稀疏光流。在两个平台上,FAST检测器的运行时间都占主导地位,至少占执行时间的66%。对于其他EuRoCMH序列,运行时间分解情况类似,因此省略了进一步的分解。例如,在Jetson Orin上,FAST检测器特征检测始终占据运行时间的80%-85%左右。
因此,利用FPGA设计特征检测器的硬件加速器已成为计算机系统和机器人领域的一个热门研究方向。近年来,计算机系统和机器人研究人员开始考虑在视觉SLAM管道中对特征检测进行硬件加速。然而,这些研究均还没有对集成在视觉SLAM管道中的硬件加速特征检测器进行过系统化比较。
本文首次对FPGA和GPU加速的特征检测器进行了比较研究,考虑了视觉SLAM管道。由于ICE-BA在精度、效率、一致性和软件模块化方面处于领先地位,因此被选为视觉SLAM管道。本文比较了FAST、Harris和SuperPoint的GPU和FPGA实现。FAST和SuperPoint分别被选中,因为它们分别代表了最先进的算法和基于神经网络的特征检测器。此外,FAST和SuperPoint提供了其他非基于学习的检测器(如Harris、SIFT、SUSAN和Shi-Tomasi)所不具备的重复性。SuperPoint被选中而非SiLK,因为SuperPoint是一个轻量级的卷积神经网络,因此更适合边缘部署。选择Harris是为了研究的完整性。
评估使用了EuRoC数据集中的机器大厅(MH)序列,并表明当使用FAST和Harris时,依赖GPU的实现能够获得比FPGA实现更好的运行时性能和能效。然而,当考虑SuperPoint时,其FPGA实现能够获得比GPU实现更好的运行时性能和能效(分别提高3.1倍和1.4倍)。与GPU加速的ICE-BA相比,FPGA加速的ICE-BA在运行时间性能方面也能达到相当的水平,在5个数据集序列中有2个序列的帧率更高。然而,从精度来看,结果表明,总体而言,GPU加速的ICE-BA比FPGA加速的ICE-BA更准确。此外,通过使用硬件加速器进行特征检测,可以进一步提高视觉SLAM管道的性能,减少全局光束法平差模块的调用频率,同时不牺牲精度。
02 实验设置
A.硬件和软件设置
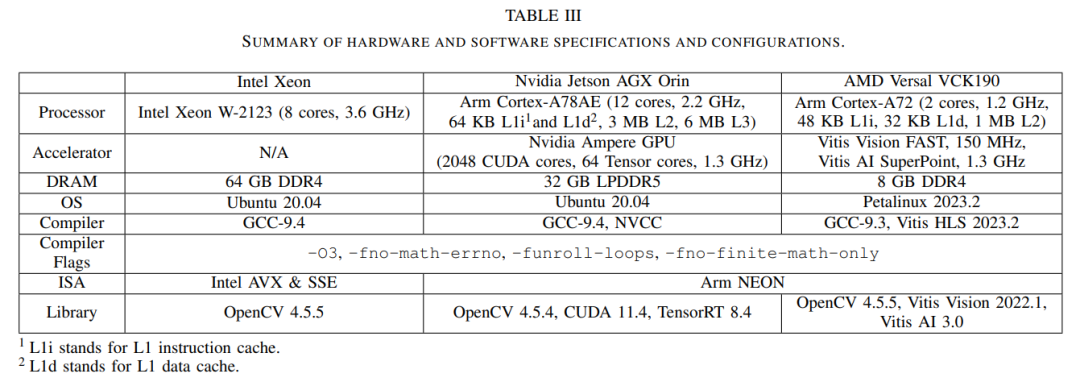
为完整性起见,还包含了一台基于英特尔的工作站。
B.数据集
评估使用了来自EuRoC数据集的机器大厅(MH)序列,其分辨率为752×480。每个序列被分为“简单”、“中等”或“困难”三类。“简单”序列的环境具有良好的纹理和照明,“中等”序列包含快速运动和明亮场景,“困难”序列则有快速运动和照明不良的场景。MH序列的图像由立体相机以20Hz的频率捕获,而惯性测量单元(IMU)数据则以200Hz的频率同步。实验中仅使用了左相机的图像和IMU数据。
C.评估
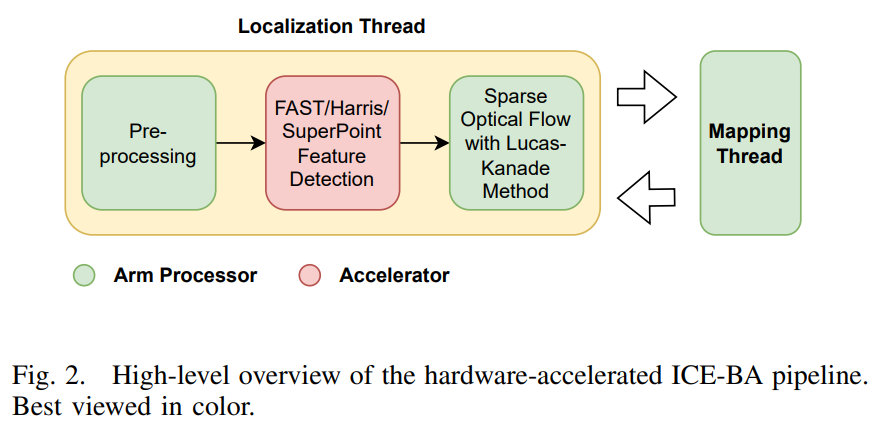
图2展示了加速ICE-BA管道的高层概述。绿色模块在所考虑的SoC的Arm处理器上执行。模块以红色标注(特征检测器)在嵌入式GPU或FPGA上进行加速。表IV总结了FAST和Harris特征检测器的算法参数。硬件加速器与软件基线使用相同的算法参数。
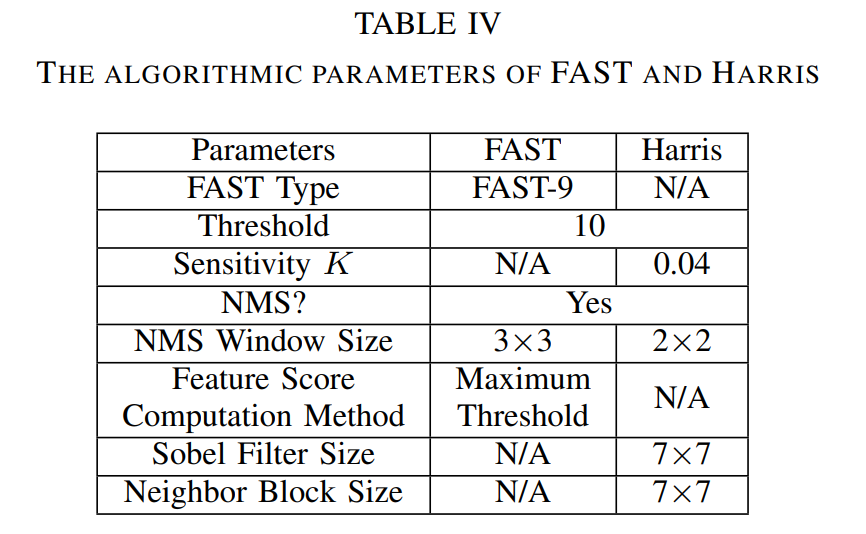
表V总结了Nvidia Jetson Orin的配置。
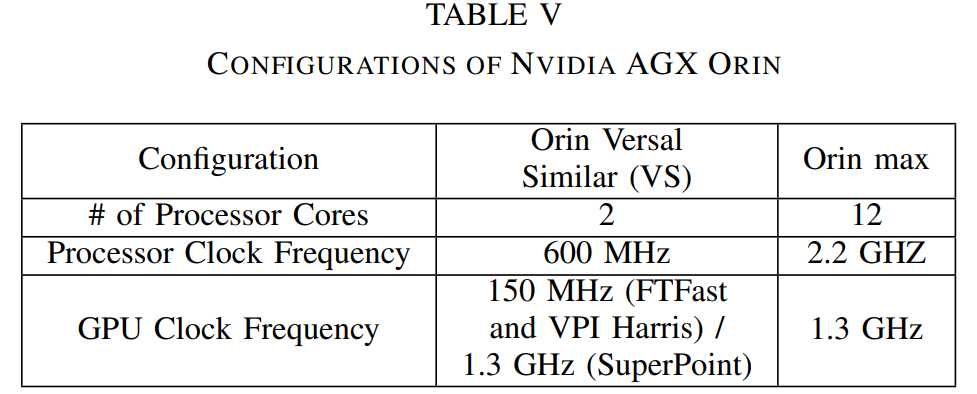
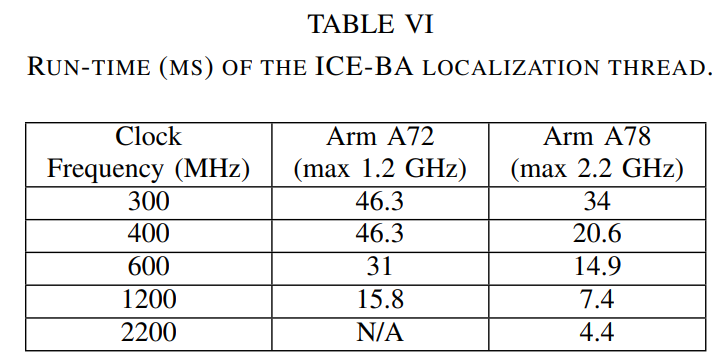
表VI展示了在2个Arm A72/A78内核下不同时钟频率下ICE-BA定位线程所达到的不同运行时间。
03 实验对比
A.特征检测器硬件加速器的结果
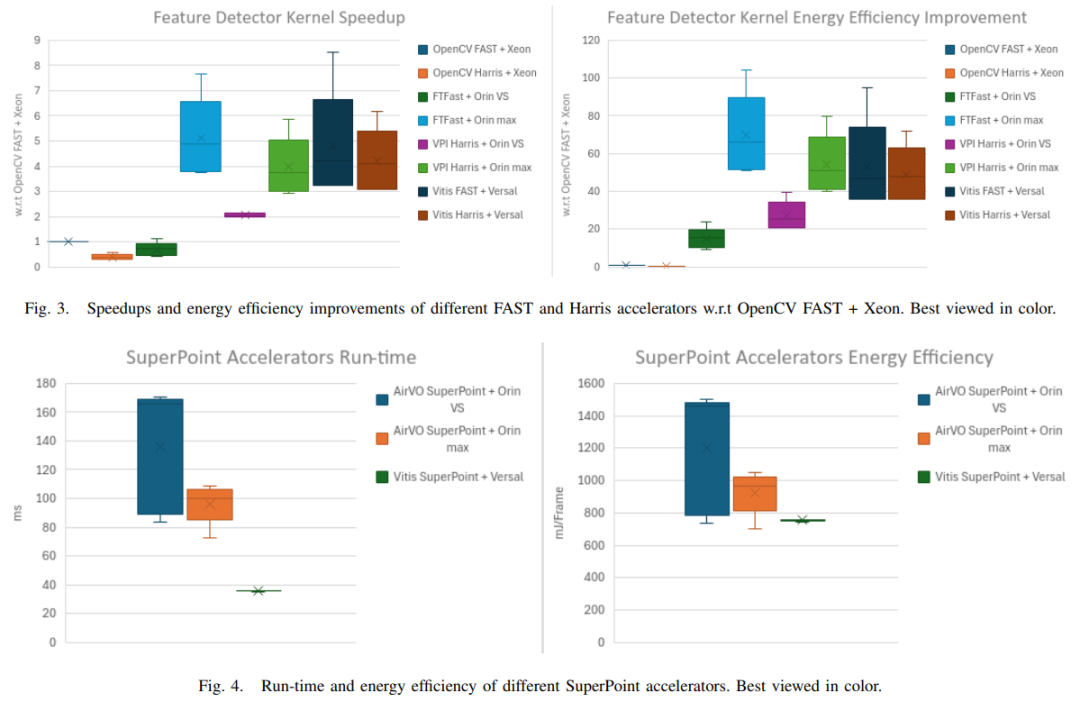
图3总结了GPU和FPGA加速的FAST和Harris相对于Xeon上的FAST软件基线的速度提升和能效改进结果。
对于FAST加速器,FTFast+Orin max在5个序列中的4个(除了MH01)实现了最佳的运行时性能,并且在所有MH序列中实现了最佳的能效(仅为2.2-2.3毫焦/帧),其次是VCK190上的Vitis FAST加速器,其速度慢12.8%-15.2%。然而,请注意,在Orin max配置下,GPU的时钟频率为1.3GHz,而FAST FPGA加速器的时钟频率为150MHz。与GPU时钟频率与FPGA加速器相同的FTFast+Orin VS相比,Vitis FAST加速器可实现5.9×-7.7×的速度提升。并且在能源效率方面提升3.3-4.3倍。
与英特尔至强处理器上的OpenCV软件基线相比,FTFast+Orin max实现了3.7-7.6倍的速度提升和52-104倍的能效提升,而Vitis FAST加速器实现了5.1-8.5倍的速度提升和38.3-95.6倍的能效提升。
在Harris加速器方面,Vitis Harris加速器在所有MH序列中均实现了最佳的运行时性能,与英特尔至强处理器上的OpenCV基线相比,速度提升10.6-11倍,与VPI Harris+Orin max相比,速度提升1.01-1.1倍。由于采用了精度较低的数值计算方案,Vitis Harris加速器的运行速度略胜于VPI Harris+Orin最高配置版本。另一方面,VPI Harris+Orin max在所有MH序列中实现了最佳的能效,在英特尔至强处理器上比软件基线提高了136-146倍,在Vitis Harris加速器上提高了1.02-1.1倍。图4总结了不同SuperPoint GPU和FPGA加速器的运行时间和能效。
采用VCK190的Vitis SuperPoint加速器在所有MH序列中实现了最佳的运行时性能(28帧/秒)和能效(除MH04外,为745-758毫焦/帧),与SuperPoint+Orin max相比,速度提升2-3.1倍,能效提升1.2-1.4倍。值得注意的是,Vitis SuperPoint加速器是唯一能够实现实时性能的加速器,而SuperPoint+Orin max的帧率最高只能达到14帧/秒。
与FAST加速器相比,两个硬件平台上的Harris加速器在运行时和能效方面表现更差,尤其是在GPU实现中。
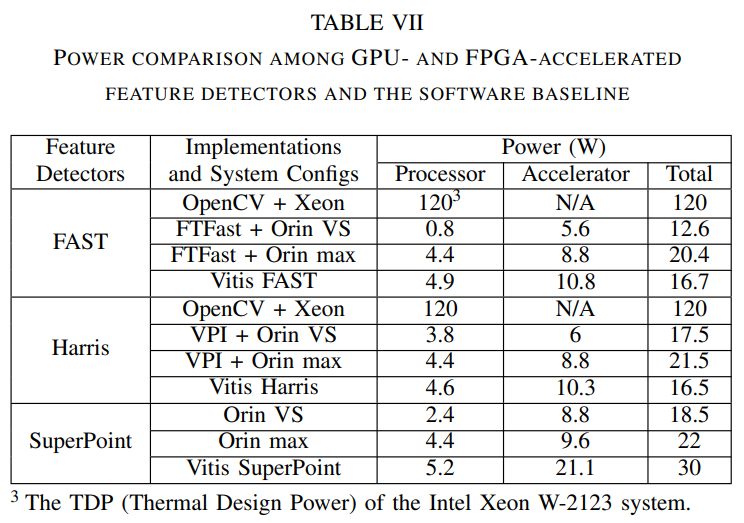
根据表VII,SuperPoint加速器的功耗高于FAST和Harris加速器,尤其是在FPGA上(21.1瓦对10.8瓦对10.3瓦)。这是因为FPGA加速器的功耗与其时钟频率和所占面积成正比。AMD深度学习处理器单元(DPU)上运行的Vitis SuperPoint的执行频率更高(1.3GHz对比150MHz),占用面积更大(FF:28%对比0.82%对比0.97%,LUT:45%对比2.91%对比2.01%,DSP:42%对比0%对比0%,BRAM:73%对比1.24%对比3.62%,AIE:48%对比0%对比0%),与Vitis FAST和Harris加速器相比。
B.硬件加速ICE-BA的结果
图5总结了将ICE-BA管道与GPU和FPGA加速的FAST和Harris集成后,相对于软件基线(ICE-BA+OpenCV FAST+Xeon)的速度提升和能效改进情况。
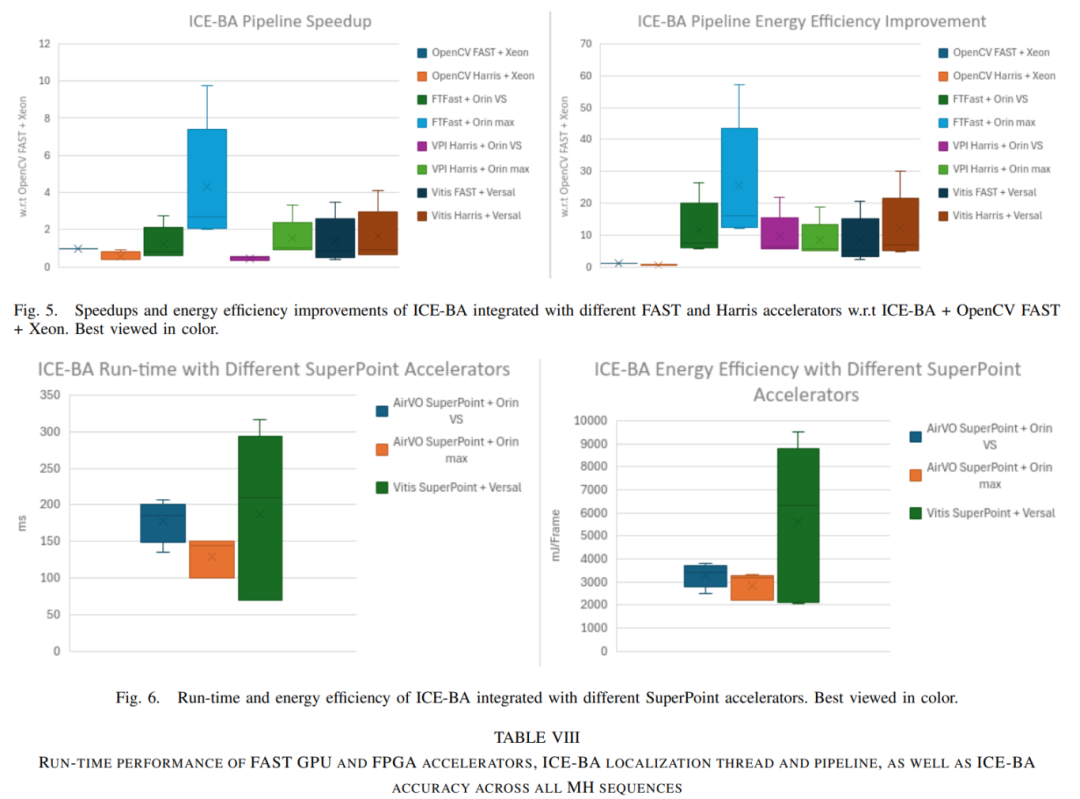
图7总结了ICE-BA管道与不同FAST、Harris和SuperPoint加速器集成后的精度(以RMSEATE衡量)。
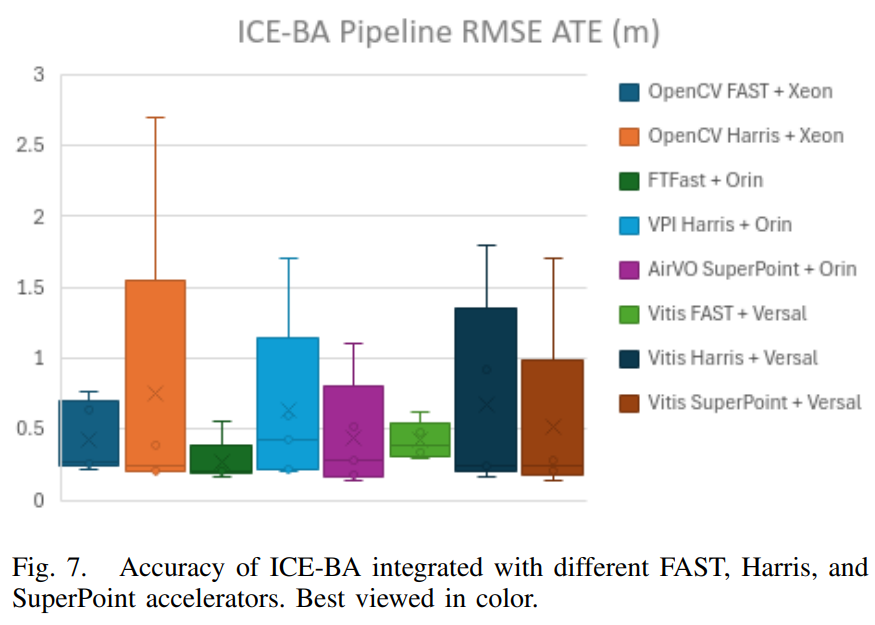
关于与FAST加速器集成的ICE-BA,ICE-BA+FTFast+Orin max在所有MH序列中均实现了最佳的运行时性能和能效。该管道的运行时性能和能效可低至9毫秒(111帧/秒)和183毫焦/帧。
与Orin相比,ICE-BA与Vitis FAST加速器集成后性能和能效均较差,这是由于处理器微架构(Arm A72对比Arm A78)、处理器核心数量(2对比12)以及时钟频率(1.2GHz对比2.2GHz)的差异所致。然而,与ICE-BA+FTFast+Orin VS相比,ICE-BA与Vitis FAST加速器集成后可实现相当的运行时性能,在MH03、MH04和MH05序列中性能略优。不过,与ICE-BA+FTFast+Orin VS相比,ICE-BA与FAST FPGA加速器集成后能效更低,这是由于功耗更高(12.6瓦对比16.7瓦,见表VII)。
与Xeon上的软件基线相比,ICE-BA+FTFast+Orin max管道实现速度提升2.1-10.5倍,能效提升11.9-57.3倍。与软件基线相比,ICE-BA管道与Vitis FAST加速器集成后能效提升了3-25.1倍。关于精度,总体而言,ICE-BA+FTFast的精度略高于软件基线,而ICE-BA与Vitis FAST加速器集成后的精度低于ICE-BA+FTFast,但MH05除外。这主要是由于使用了近似值和低精度数字,其中移位操作用于近似乘法和除法操作,并且使用了定点数而非浮点数。
在ICE-BA与Harris加速器集成方面,ICE-BA+VPI Harris+Orin max在MH01和MH02序列中实现了最佳的运行时性能,而ICE-BA管道与Vitis Harris加速器集成在MH03、MH04和MH05序列中实现了最佳的运行时性能。
令人惊讶的是,在“中等”和“困难”情况下,ICE-BA+Vitis Harris的运行时性能优于ICE-BA+VPI Harris+Orin max。在具有快速运动和光照不良的序列数据集上,尽管在Arm处理器微架构方面存在劣势,但就能效而言,在MH01和MH02序列中,ICE-BA+VPI Harris+Orin VS是最节能的实现方式,而在MH03、MH04和MH05序列中,ICE-BA+Vitis Harris则是最节能的实现方式。在精度方面,ICE-BA与Harris FPGA加速器集成在“简单”序列(MH01和MH02)中比GPU对应实现更准确,而ICE-BA与Harris GPU加速器集成在“中等”和“困难”序列(MH03、MH04和MH05)中更准确。
与Xeon上的软件基线相比,ICE-BA+VPI Harris+Orin最大流水线实现了2.2-3.6倍的速度提升和12.2-20倍的能效提升。与软件基线相比,ICE-BA流水线与Vitis Harris加速器集成实现了1.7-4.4倍的速度提升和12.6-33.4倍的能效提升。
图5总结了ICE-BA流水线与GPU和FPGA加速的SuperPoint集成的运行时性能和能效。有趣的是,尽管VCK190上的Arm内核数量有限且频率较低,但ICE-BA+Vitis SuperPoint在MH01和MH02序列上仍能实现最佳的运行时性能和能效。我们认为这是由于MH01和MH02是“简单”的序列,代表了具有良好纹理的场景。
与ICE-BA+SuperPoint+Orin max相比,ICE-BA+Vitis SuperPoint在MH01和MH02序列上实现了高达1.5倍的速度提升和1.1倍的能效提升。在其余序列中,ICE-BA+Vitis SuperPoint也能实现与ICE-BA+SuperPoint+Orin max相当的运行时性能。
ICE-BA+SuperPoint+Orin max在MH03、MH04和MH05序列上实现了最佳的运行时性能(高达7FPS)和能效。在精度方面,ICE-BA与SuperPoint GPU加速器集成通常比ICE-BA+Vitis SuperPoint更准确,除了MH04序列。ICE-BA+Vitis SuperPoint的精度较低,因为Vitis SuperPoint使用INT8精度进行量化,而SuperPoint GPU加速器使用FP16精度。
总体而言,与采用Harris GPU加速器的ICE-BA相比,采用FAST GPU加速器的ICE-BA性能更高、能耗更低且更精准。然而,ICE-BA+Vitis FAST的性能和能耗效率略逊于ICE-BA+Vitis Harris,在诸如MH01、MH02和MH03这类“简单”和“中等”难度的序列中,其精度也更低。此外,尽管ICE-BA+SuperPoint是运行时性能和能耗效率最差的配置,但它在精度方面并不总是优于ICE-BA+FAST或ICE-BA+Harris。
例如,在两个硬件平台上,ICE-BA+SuperPoint仅在纹理和光照良好的MH01“简单”序列上比ICE-BA+FAST和ICE-BA+Harris更准确。我们还发现,使用硬件加速器进行特征检测,可能会对ICE-BA管道中映射线程的下游模块的运行时性能产生积极影响,尤其是全局光束法平差模块。
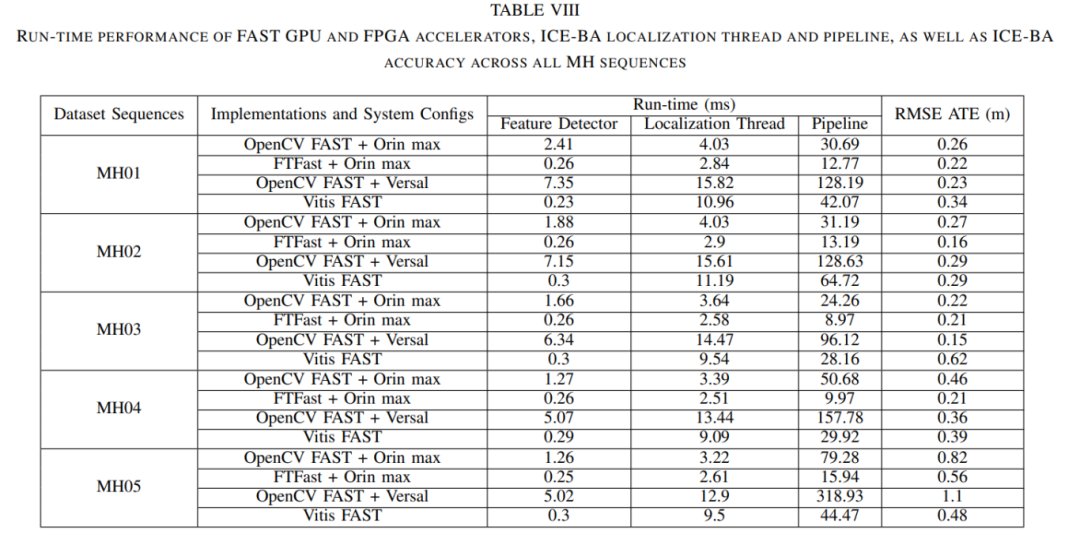
表VIII总结了特征检测模块和定位线程的运行时间,以及与不同FAST实现集成的ICE-BA管道的运行时间和精度。根据表VIII,在将OpenCV中的FAST实现替换为FTFast和Vitis FAST后,特征检测模块的运行时间分别减少了1.01毫秒-2.15毫秒(GPU)和4.72毫秒-7.12毫秒(FPGA),而定位线程的运行时间分别减少了0.61毫秒-1.19毫秒(GPU)和3.4毫秒-4.93毫秒(FPGA)。然而,管道的运行时间减少幅度要大得多,即15.29毫秒-63.34毫秒(GPU)和63.91毫秒-274.46毫秒(FPGA)。
考虑到定位线程与映射线程中的局部和全局光束法平差模块并行运行,而全局光束法平差模块在视觉SLAM管道中通常是耗时最长的模块,我们认为使用硬件加速器进行特征检测会影响全局光束法平差模块的性能。进一步的研究表明,与使用OpenCV FAST相比,使用FTFast或Vitis FAST时,全局光束法平差的调用频率更低,从而减少了运行时间。全局光束法平差是一个非线性最小二乘系统求解器,它联合优化全局地图中的所有地标以及从每个地标可观测到的特征点,以进一步减少累积的平移和旋转误差,从而提高精度。令人惊讶的是,尽管全局光束法平差的调用频率更低,但在所有MH序列中,ICE-BA+FTFast的精度都高于ICE-BA+OpenCV FAST。
04 总结
本文是首次针对先进系统级芯片(SoC)结合现场可编程门阵列(FPGA)/图形处理器(GPU)的视觉SLAM系统中特征检测器的研究。
评估结果表明,使用非基于学习的特征检测器(如FAST和Harris)时,来自Nvidia VPI库的FTFast和Harris,以及ICE-BA+FTFast和ICE-BA+VPI Harris,其运行时性能和能效优于Vitis FAST和Harris加速器以及FPGA加速的ICE-BA。然而,当考虑基于学习的检测器(如SuperPoint)时,Vitis SuperPoint加速器在运行时性能和能效方面(分别提高了3.1倍和1.4倍)优于其GPU对应版本。ICE-BA+Vitis SuperPoint在运行时性能方面也与集成SuperPoint GPU加速器的ICE-BA相当,在5个数据集序列中有2个序列的帧率更高。不过,从精度方面来看,结果表明,总体而言,GPU加速的ICE-BA比FPGA加速的ICE-BA更准确。我们还发现,使用硬件加速进行特征检测能够进一步提升运行时性能。通过减少全局光束法平差(通常是计算量最大的模块)的调用频率来优化视觉SLAM管道,同时不牺牲精度。
-
FPGA
+关注
关注
1665文章
22587浏览量
641250 -
机器人
+关注
关注
214文章
31700浏览量
224670 -
gpu
+关注
关注
28文章
5339浏览量
136282 -
计算机
+关注
关注
19文章
7857浏览量
93649
原文标题:FPGA vs GPU:视觉SLAM中特征检测器的加速性能对比
文章出处:【微信号:gh_c87a2bc99401,微信公众号:INDEMIND】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
浅谈SLAM的回环检测技术
如何在FPGA中实现过零检测器?
SLAM大法之回环检测
如何利用FPGA实现Laplacian图像边缘检测器的研究?
激光SLAM与视觉SLAM有什么区别?
HOOFR-SLAM的系统框架及其特征提取
基于 FPGA 的目标检测网络加速电路设计
单目视觉SLAM仿真系统的设计与实现
基于计算机视觉领域中的特征检测和匹配研究
视觉SLAM是什么?视觉SLAM的工作原理 视觉SLAM框架解读



评论