 强化学习在自动驾驶的应用
强化学习在自动驾驶的应用

制造真正的自动驾驶汽车(即能够在任何要求的环境中安全驾驶)的关键是更加重视关于其软件的自学能力。换句话说,自动驾驶汽车首先是人工智能问题,需要一个非常具体的机器学习开发技能。而强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它的本质是解决决策(decision making)问题,即自动进行决策,并且可以做连续决策。今天人工智能头条给大家介绍强化学习在自动驾驶的一个应用案例,无需 3D 地图也无需规则,让汽车从零开始在二十分钟内学会如何自动驾驶。
▌前言
强化学习是通过对未知环境一边探索一边建立环境模型以及学得一个最优策略。强化学习具有以下特征:
没有监督数据,只有奖励(reward)信号;
奖励信号不一定是实时的,而很可能是延后的,有时甚至延后很多;
时间(序列)是一个重要因素;
智能体当前的行为影响后续接收到的数据。
而有监督学习则是事先给你了一批样本,并告诉你哪些样本是优的哪些是劣的(样本的标记信息),通过学习这些样本而建立起对象的模型及其策略。在强化学习中没有人事先告诉你在什么状态下应该做什么,只有在摸索中反思之前的动作是否正确来学习。从这个角度看,可以认为强化学习是有时间延迟标记信息的有监督学习。
其他许多机器学习算法中学习器都是学得怎样做,而强化学习是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报。
简而言之,强化学习采用的是边获得样例边学习的方式,在获得样例之后更新自己的模型,利用当前的模型来指导下一步的行动,下一步的行动获得奖励之后再更新模型,不断迭代重复直到模型收敛。
强化学习有广泛的应用:像直升机特技飞行、经典游戏、投资管理、发电站控制、让机器人模仿人类行走等等。
英国初创公司 wayve 日前发表的一篇文章 Learning to drive in a day,阐述了强化学习在自动驾驶汽车中的应用。Wayve是英国两位剑桥大学的机器学习博士创立的英国自动驾驶汽车公司,正在建立“端到端的机器学习算法”,它声称使用的方法与大部分自驾车的思维不同。具体来说,这家公司认为制造真正的自动驾驶汽车的关键在于软件的自学能力,而其他公司使用更多的传感器并不能解决问题,它需要的是更好的协调。
自动驾驶的人工智能包含了感知、决策和控制三个方面。
感知指的是如何通过摄像头和其他传感器的输入解析出周围环境的信息,例如有哪些障碍物、障碍物的速度和距离、道路的宽度和曲率等。而感知模块不可能做到完全可靠。Tesla 的无人驾驶事故就是在强光的环境中感知模块失效导致的。强化学习可以做到,即使在某些模块失效的情况下也能做出稳妥的行为。强化学习可以比较容易地学习到一系列的行为。自动驾驶中需要执行一系列正确的行为才能成功的驾驶。如果只有标注数据,学习到的模型每个时刻偏移了一点,到最后可能会偏移非常多,产生毁灭性的后果。强化学习能够学会自动修正偏移。
自动驾驶的决策是指给定感知模块解析出的环境信息如何控制汽车的行为达到驾驶的目标。例如,汽车加速、减速、左转、右转、换道、超车都是决策模块的输出。决策模块不仅需要考虑到汽车的安全性和舒适性,保证尽快到达目标地点,还需要在旁边的车辆恶意的情况下保证乘客的安全。因此,决策模块一方面需要对行车的计划进行长期规划,另一方面需要对周围车辆和行人的行为进行预测。而且,无人驾驶中的决策模块对安全性和可靠性有严格的要求。现有的无人驾驶的决策模块一般是根据规则构建的。虽然基于规则的构建可以应付大部分的驾驶情况,对于驾驶中可能出现的各种各样的突发情况,基于规则的决策系统不可能枚举到所有突发情况。我们需要一种自适应的系统来应对驾驶环境中出现的各种突发情况。
现在,让我们来看看 Wayve 的自动驾驶汽车的解决方案有什么新颖的地方。
▌从零开始学会如何通过试错法来学会自动驾驶
还记得小时候学骑自行车的情景吗?又兴奋,又有一点点焦虑。你可能是第一次坐在自行车上,踩着踏板,大人跟随在你身边,准备在你失去平衡的时候扶住你。在一些摇摆不定的尝试之后,你可能设法保持了几米距离的平衡。几个小时过去后,你可能在公园里的沙砾和草地上能够飞驰了。大人只会给你一些简短的提示。你不需要一张公园的密集 3D 地图,也不需要在头上装一个高保真激光摄像头。你也不需要遵循一长串的规则就能在自行车上保持平衡。大人只是为你提供了一个安全的环境,让你学会如何根据你所见来决定你的行为,从而成功学会骑车。
如今,自动驾驶汽车安装了大量的传感器,并通过缓慢的开发周期中被告知如何通过一长串精心设计的规则来驾驶车辆。在本文中,我们将回到基础,让汽车从零开始学会如何通过试错法来学会自动驾驶,就像你学骑自行车一样。
看看我们做了什么:只用了 15~20 分钟,我们就能够教会一辆汽车从零开始沿着一条车道行驶,而这只有当安全驾驶员接手时作为训练反馈才使用。
译注:试错(trial and error)是一种用来解决问题、获取知识的常见方法。此种方法可视为简易解决问题的方法中的一种,与使用洞察力和理论推导的方法正好相反。在试错的过程中,选择一个可能的解法应用在待解问题上,经过验证后如果失败,选择另一个可能的解法再接着尝试下去。整个过程在其中一个尝试解法产生出正确结果时结束。
像学骑自行车的方法只有一种:试错。虽然简单,但这个思想实验突出了人类智能的一些重要方面。对于某些任务,我们采用试错法;而对于其他任务我们则使用规划的方法。在强化学习中也出现了类似的现象。按照强化学习的说法,实证结果表明,一些任务更适合无模型(试错)方法,而另一些则更适合基于模型的(规划)方法。
▌无需密集 3D 地图,无需手写规则
这是自动驾驶汽车在网上学习的第一个例子,每一次尝试都会让它变得更好。那么,我们是怎么做到的呢?
我们采用了一种流行的无模型深度强化学习算法(深度确定性策略梯度:deep deterministic policy gradients,DDPG)来解决车道跟踪问题。我们的模型输入是单目镜摄像头图像。我们的系统迭代了三个过程:探索、优化和评估。
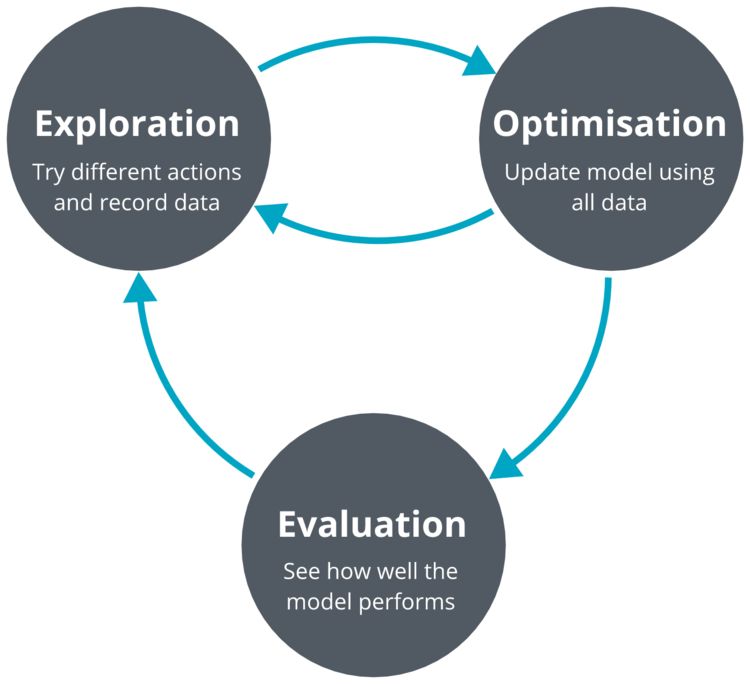
译注:DDPG,由DeepMind的Lillicrap 等于 2016 年提出,全称是:Deep Deterministic Policy Gradient,是将深度学习神经网络融合进DPG的策略学习方法。而 DPG 是由 DeepMind 的 D.Silver 等人在 2014 年提出的: Deterministic Policy Gradient,即确定性的行为策略。在此之前,业界普遍认为,环境模型无关(model-free)的确定性策略是不存在的,在 2014 年的 DPG 论文中,D.Silver 等通过严密的数学推导,证明了 DPG 的存在。DDPG 相对于 DPG 的核心改进是:采用卷积神经网络作为策略函数μ 和 Q 函数的模拟,即策略网络和 Q 网络;然后使用深度学习的方法来训练上述神经网络。
DDPG 算法是利用 QDN 扩展 Q 学习算法的思路对 DPG 方法进行改造,提出的一种基于行动者-评论家(Actor-Critic,AC)框架的算法,该算法可用于解决连续动作空间上的 DRL 问题。
可参考论文《Continuous control with deep reinforcementlearning》(https://arxiv.org/abs/1509.02971)
无模型的 DDPG 方法学习更慢,但最终优于基于模型的方法。
我们的网络架构是一个深度网络,有 4 个卷积层和 3 个完全连接的层,总共略低于 10k 个参数。为了比较,现有技术的图像分类体系结构有数百万个参数。
所有的处理都是在汽车上的一个图形处理单元(GPU)上执行的。
在危险的真实环境中使用真正的机器人会带来很多新问题。为了更好地理解手头的任务,并找到合适的模型架构和超参数,我们进行了大量的仿真测试。
上组动图所示,是我们的车道跟随不同角度显示的模拟环境的示例。这个算法只能看到驾驶员的视角,也就是图中有青色边框的图像。在每一次模拟中,我们都会随机生成一条弯曲的车道,以及道路纹理和车道标记。智能体会一直探索,直到模拟终止时它才离开。然后根据手机到的数据进行策略优化,我们重复这样的步骤。
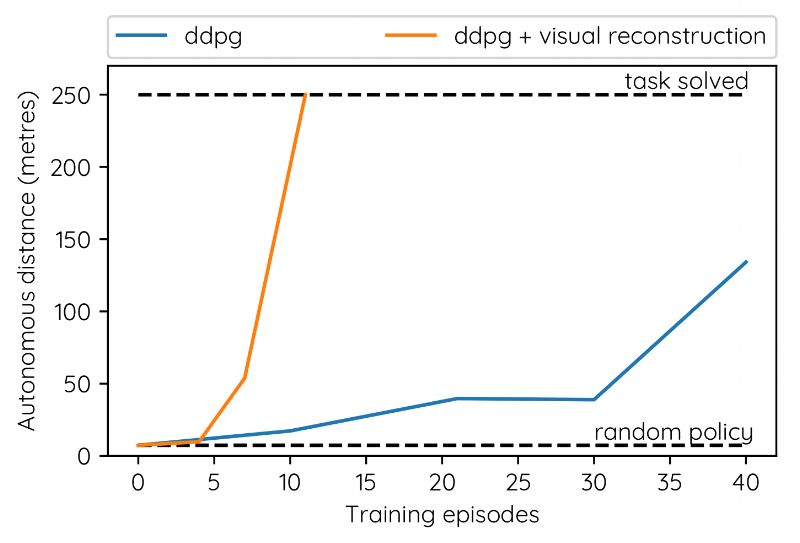
在安全驾驶员接管之前,汽车行驶的距离与模拟探索的数量有关。
我们使用模拟测试来尝试不同的神经网络架构和超参数,直到我们找到一致的设置,这些设置在很少的训练集中,也就是几乎没有数据的情况下,始终如一地解决了车道跟随的问题。例如,我们的发现之一,是使用自动编码器重构损失训练卷积层可以显著提高训练的稳定性和数据效率。
▌潜在的影响力
我们的方法的潜在影响是巨大的。想象一下,部署一支自动驾驶车队,使用一种最初只有人类司机 95% 质量的驾驶算法会怎么样。这样一个系统将不会像我们的演示视频中的随机初始化模型那样摇摇晃晃地行驶,而是几乎能够处理交通信号灯、环形交叉路口、十字路口等道路情况。经过一天的驾驶和人类安全驾驶员接管的在线改进后,系统也许可以提高到 96%。一个星期以后,提高到 98%。一个月以后,提高到99%。几个月以后,这个系统可能会变得超人类,因为它从许多不同的安全驾驶员的反馈中受益得以提高。
今天的自动驾驶汽车仍停留在良好的状态,但性能水平还不够好。在本文中,我们为第一个可行的框架提供了证据,以便快速改善驾驶算法,使其从不堪造就到可安全行驶。通过巧妙的试错法快速学习解决问题的能力,使人类拥有具备进化和生存能力的万能机器。我们通过各种各样的模仿来学习,从骑自行车到学习烹饪,我们经历了很多试错的过程。
DeepMind 向我们展示了深度强化学习方法可以在许多游戏中实现超人类的表现,包括围棋、象棋和电脑游戏,几乎总是比任何基于规则的系统表现的更好。我们发现,类似的哲学在现实世界中也是可能的,特别是在自动驾驶汽车中。有一点需要注意的是,DeepMind 的 Atari算法需要数百万次试验才能完成一个任务。值得注意的是,我们在不到 20 次试验中,一贯都学会了沿着车道行驶。
▌结束语
20 分钟,我们从零开始,学会了沿着车道行驶。想象一下,我们一天可以学到什么?
Wayve 的理念是构建机器人智能,不需要大量的模型、花哨的传感器和无尽的数据。我们需要的是一个聪明的训练过程,可以快速有效地学习,就像我们上面的视频一样。人工设计的自动驾驶技术在性能上达到了令人不满意的玻璃天花板。Wayve 正视图通过更智能的机器学习来开发自动驾驶功能。
-
自动驾驶
+关注
关注
795文章
15082浏览量
182143 -
强化学习
+关注
关注
4文章
275浏览量
12023
原文标题:讲真?一天就学会了自动驾驶——强化学习在自动驾驶的应用
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在阿里云PAI平台的机器人感知强化学习规模化实践

上汽奥迪E7X携手Momenta首发落地L3级自动驾驶系统
自动驾驶端到端为什么会出现黑盒现象?

如何构建适合自动驾驶的世界模型?

自动驾驶中常提的离线强化学习是什么?

强化学习会让自动驾驶模型学习更快吗?

如何设计好自动驾驶ODD?
多智能体强化学习(MARL)核心概念与算法概览

自动驾驶中常提的模仿学习是什么?
如何训练好自动驾驶端到端模型?

高程数据在自动驾驶中有什么作用?
自动驾驶中常提的“强化学习”是个啥?

低速自动驾驶与乘用车自动驾驶在技术要求上有何不同?

卡车、矿车的自动驾驶和乘用车的自动驾驶在技术要求上有何不同?



评论