 NVIDIA硅光技术助力迈向百万GPU AI工厂
NVIDIA硅光技术助力迈向百万GPU AI工厂

在支撑万亿参数时代的 AI 工厂,为何网络比以往更为重要。
在全球范围内,AI 工厂正在崛起 —— 大量的这些新型数据中心并非为提供网页或电子邮件服务而建,而是用于训练和部署智能本身。互联网巨头们已经为其客户在 AI 云基础设施上投资了数十亿美元,现在正在打造 AI 工厂上展开了激烈竞争,以迎接下一代的产品和服务。各国政府也纷纷加大投资,迫切希望借助 AI 实现为国民量身定制的个性化医疗及语言服务。
欢迎来到 AI 工厂时代 —— 在这个时代,规则正在被改写,构建方式与传统的互联网已截然不同。这些并非典型的超大规模数据中心,它们完全是另一番模样。可以将它们视为由数万个乃至数十万个 GPU 拼接而成的高性能引擎——不仅仅是将他们搭建起来,还要将其作为一个整体进行编排、运营和操作。而这种编排能力,正是关键所在。
这个巨大的数据中心已成为新的计算单元,而这些 GPU 的连接方式定义了此计算单元的功能。单一的网络架构无法满足需求,我们需要的是采用前沿技术进行分层设计,比如曾经看起来像科幻小说一样的光电一体化封装(CPO)技术。
这种复杂性并非缺陷,而是其核心特征。AI 基础设施与以往所有技术的差异化正在快速加大,若不重新思考各种路径的连接方式,将无法进行扩展。网络层设计失误,整台机器将陷入停滞;设计得当,则能获得卓越性能。
伴随这种转变而来的是重量的显著增加。十年前,芯片追求轻薄设计。如今,最前沿的技术却转向了服务器机柜内数百公斤的铜背板,液冷通路的设计、定制的总线架以及铜背板的设计。AI 如今需要大规模、工业级的硬件支持,而且模型越复杂,越需要系统的纵向和横向扩展。
以NVIDIA NVLink总线背板为例,它需要连接 5000 多根同轴电缆——紧密缠绕且布线精准。其每秒传输的数据量几乎相当于整个互联网的流量,可在 GPU 到 GPU 之间实现 130 TB/s 全连接带宽。
这不仅是速度快,而是整个系统的基础,在机架内部的 AI “超级高速路”。
数据中心即计算机
训练现代大语言 AI 模型并非依赖单台机器的运算能力,而是要协调数万颗乃至数十万颗作为 AI 计算超级加速器的 GPU 协同工作。
这些系统依赖分布式计算,将海量计算任务分配到各个节点(单个服务器),每个节点处理一部分工作负载。在训练过程中,这些巨型数字矩阵的分片任务需要进行定期合并和更新。这种合并通过集体操作实现,例如“all-reduce”(聚合来自所有节点的数据并重新分发结果)和“all-to-all”(每个节点与所有其他节点交换数据)。
这些过程极易受网络速度和响应能力的影响——工程师称之为延迟(延迟时间)和带宽(数据容量),这会导致训练中断。
而在推理——即通过运行训练好的模型来生成答案或预测,面对的挑战则完全不同。如检索增强生成系统,将 LLM 与搜索结合,需要实时查询和响应。在云环境中,多租户推理要求不同客户的工作负载顺畅运行且互不干扰。这需要超高速度、高吞吐量的网络,既能应对海量需求,又能确保用户间的严格隔离。
传统以太网专为单服务器工作负载设计,无法满足分布式 AI 的需求。过去,抖动和不稳定传输尚可容忍,如今却成了瓶颈。传统以太网交换机架构从未针对稳定、可预测的性能进行设计,这种局限性仍影响着其最新一代产品。
分布式计算需要为零抖动运行而构建的横向扩展基础设施——能够应对突发的极端吞吐量、提供低延迟、保持可预测且稳定的 RDMA 性能,并隔离网络上其他业务的干扰。这也是为什么 InfiniBand 网络成为高性能计算超级计算机和 AI 工厂的黄金标准。
借助NVIDIA Quantum InfiniBand,集合运算可通过 SHARP 协议(Scalable Hierarchical Aggregation and Reduction Protocol)直接运行在网络上,使归约操作的数据带宽翻倍。它采用动态路由和基于遥测的拥塞控制技术,在多条路径上分配流量,保证确定性带宽并隔离噪声。这些优化使 InfiniBand 能精准地扩展 AI 通信。这也是为何 NVIDIA Quantum 基础设施连接了全球超级计算机 TOP500 榜单中的大多数系统,且仅两年内就实现了 35% 的增长。
对于跨数十个机架的集群,NVIDIA Quantum X800 InfiniBand 交换机将 InfiniBand 性能推向新高度。每台交换机提供 144 个 800 Gbps 端口,支持基于硬件的 SHARPv4 技术、动态路由和基于遥测的拥塞控制技术。该平台还通过集成了 CPO 技术来最大限度地缩短了电器件与光器件的距离,降低了功耗和延迟。搭配每 GPU 提供 800 Gb/s 的 NVIDIA ConnectX-8 SuperNIC,这种网络架构可连接万亿参数模型及利用网络计算技术。
但超大规模数据中心用户和企业级用户已在以太网软件基础设施上投入数十亿美元,他们需要一条能利用现有生态系统运行 AI 工作负载的快捷路径。NVIDIA Spectrum-X是专为分布式 AI 打造的新型以太网。
Spectrum-X 以太网:将 AI 引入企业
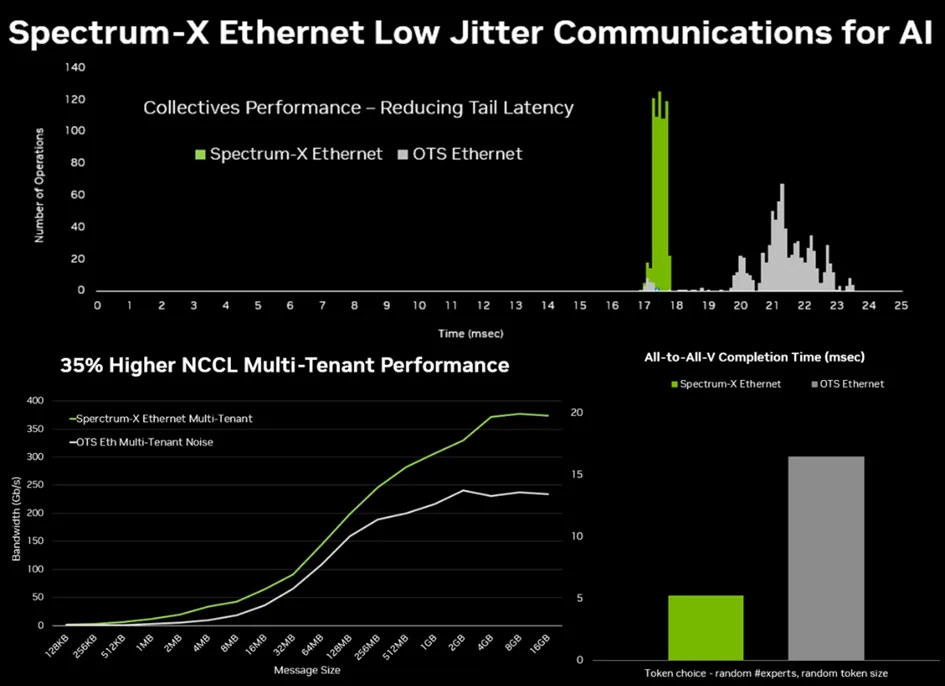
Spectrum-X 为 AI 重塑以太网。2023 年推出的 Spectrum-X 可支持无损网络、动态路由和性能隔离。基于 Spectrum-4 ASIC 的 SN5610 交换机支持高达 800 Gb/s 的端口速度,并通过 NVIDIA 的拥塞控制技术,在规模化场景下可保持 95% 的数据吞吐量。
Spectrum-X 完全基于标准以太网构建。除支持 Cumulus Linux 外,它还兼容开源 SONiC 网络操作系统,为客户提供灵活性。另一个核心组件是基于 NVIDIA BlueField-3 或 ConnectX-8 打造的 NVIDIA SuperNIC,可提供高达 800 Gb/s 的 RoCE 连接,并卸载数据包重排序和拥塞管理任务。
Spectrum-X 将 InfiniBand 的出色创新 —— 如遥测驱动的拥塞控制、动态负载均衡和直接数据放置等技术——引入以太网,使企业能够扩展至数十万颗 GPU。采用 Spectrum-X 的大型系统(包括全球最大的 AI 超级计算机)实现了 95% 的数据吞吐量,且应用延迟零衰减。而标准以太网架构因流量冲突,吞吐量仅能达到约 60%。
适用于纵向扩展和横向扩展的产品组合
没有任何单一网络能满足 AI 工厂的所有层级需求。NVIDIA 为不同层级匹配合适的网络架构,通过软件和芯片将所有部分整合在一起。
NVLink:机架内的纵向扩展
在服务器机架内部,GPU 之间的通信需如同同一芯片上的不同核之间的通信般高效。NVIDIA NVLink和 NVLink 交换机跨节点扩展了 GPU 内存和带宽。在 NVIDIA Blackwell NVL72 系统中,36 颗 NVIDIA CPU 和 72 颗 NVIDIA GPU 连接在单一 NVLink 域中,总带宽达 130 TB/s。NVLink 交换机技术进一步扩展该架构:单台 NVIDIA Blackwell NVL72 系统可提供 130 TB/s 的 GPU 带宽,使集群支持的 GPU 数量达到单台 8-GPU 服务器的 9 倍。借助 NVLink,整个机架成为一个大型 GPU。
光子技术:下一次飞跃
要实现百万 GPU 规模的 AI 工厂,网络必须突破可插拔光学器件的功率和密度限制。NVIDIA Quantum-X 和 Spectrum-X 硅光网络交换机将硅光直接集成到交换机封装中,可提供 128 至 512 个 800 Gb/s 端口,总带宽介于 100 Tb/s 到 400 Tb/s 之间。与传统光学器件相比,这些交换机的能效提升 3.5 倍,可靠性增强 10 倍,为十亿瓦级 AI 工厂铺平了道路。
兑现开放标准的承诺
Spectrum-X 和 NVIDIA Quantum InfiniBand 均基于开放标准构建。Spectrum-X 是完全基于标准的以太网,支持 SONiC 等开放以太网栈;而 NVIDIA Quantum InfiniBand 和 Spectrum-X 则符合IBTA 的 InfiniBand 和 RDMA over Converged Ethernet(RoCE)规范。NVIDIA 软件栈的核心组件(包括 NCCL 和 DOCA 库)可在多种硬件上运行,思科(Cisco)、戴尔科技(DELL)、慧与(HPE) 和 超微(Supermicro) 等合作伙伴已将 Spectrum-X 集成到其系统中。
开放标准为互操作性奠定了基础,但实际 AI 集群需要进行全栈(GPU、NIC、交换机、电缆和软件)式深度优化。投入端到端集成的供应商能提供更优的延迟和吞吐量。SONiC 作为在超大规模数据中心中得到强化的开源网络操作系统,消除了许可限制和供应商锁定,支持高度定制化,但操作人员仍会选择专为 AI 性能需求设计的硬件和软件捆绑方案。实际上,仅靠开放标准无法实现确定性性能,还需要通过创新来解决这些问题。
迈向百万 GPU 的 AI 工厂
AI 工厂正迅速扩张。欧洲多国正在建设七个国家级 AI 工厂,日本、印度和挪威的云服务商和企业也在部署 NVIDIA 驱动的 AI 基础设施。下一个目标是具备百万 GPU 规模的十亿瓦级设施。要实现这一目标,网络必须从附属品转变为 AI 基础设施的核心支柱。
十亿瓦数据中心时代带来的启示很简单:数据中心如今就是计算机。NVLink 将机架内的 GPU 连接在一起;NVIDIA Quantum InfiniBand 实现跨机架扩展;Spectrum-X 将这种性能推向更广泛的市场;硅光技术确保其可持续性。在关键之处保持开放,在核心之处追求优化。
-
NVIDIA
+关注
关注
14文章
5696浏览量
110148 -
数据中心
+关注
关注
18文章
5789浏览量
75217 -
AI
+关注
关注
91文章
41431浏览量
302763
原文标题:迎接十亿瓦数据中心时代
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA与Google Cloud携手推进代理式与物理AI发展
【封装技术】几种常用硅光芯片光纤耦合方案
NVIDIA Spectrum-X以太网硅光技术助力AI工厂网络创新
NVIDIA扩大与微软合作推动AI超级工厂建设
NVIDIA CEO黄仁勋畅谈AI时代最新蓝图
三星携手NVIDIA 以全新AI工厂引领全球智能制造转型
OpenAI和NVIDIA宣布达成合作,部署10吉瓦NVIDIA系统

NVIDIA如何优化AI工厂的网络可靠性与功耗



评论