 利用自压缩实现大型语言模型高效缩减
利用自压缩实现大型语言模型高效缩减

随着语言模型规模日益庞大,设备端推理变得越来越缓慢且耗能巨大。一个直接且效果出人意料的解决方案是剪除那些对任务贡献甚微的完整通道(channel)。我们早期的研究提出了一种训练阶段的方法 —— 自压缩(Self-Compression)[1, 4],它通过反向传播自动决定每个通道的比特宽度,从而逐步“淡化”那些无用的通道。这种方法可同时减少模型参数、数值精度,甚至可调超参数的数量,而不会影响模型的预测质量。
当我们将这一想法扩展应用于 Transformer 架构 [5] 时,观察到了一个耐人寻味的现象:当某个通道的学习精度降低至零比特,所得模型的紧凑程度甚至超过了使用固定三值编码(ternary code)的模型。由于该方法仅作用于标准的线性层,压缩后的网络无需修改运行时堆栈,便可在 CPU、GPU、DSP 和 NPU 上直接获得性能提升,从而实现一个轻量模型在多种硬件平台上的通用部署。
在本项工作中,我们更进一步,引入了基于块的稀疏性模式(block-based sparsity pattern)。接下来的章节将介绍如何将自压缩机制整合进基础模型、它所产生的权重分布模式,以及这一方法在资源受限部署环境中的潜在影响。
自压缩大型语言模型(LLM)
我们的参考模型是 nanoGPT [2],这是一个精简版的 GPT 变体,训练数据集为 shakespeare_char 语料库。该模型拥有约 1100 万个可训练参数,规模足够小以实现快速运行,同时又足够大以展现完整的 Transformer 计算模式。
该模型包含以下结构:
词嵌入层:将每个 token 映射为一个多维向量;
6 个相同的 Transformer 块,每个块包括:因果型多头注意力机制(包含输入和输出的线性层),层归一化(Layer Normalisation),一个前馈模块,内部又包含两个线性层;
输出部分:最后的层归一化,一个线性层,一个 Softmax 层,用于输出各个候选 token 的概率分布。
在 Transformer 网络中,90% 以上的权重——也就是大部分的内存带宽、DRAM 占用以及功耗——集中在 Transformer 块内的四个大型线性层中。因此,在我们的实验中,自压缩仅针对这几层线性层进行,其余的基准模型部分保持不变。
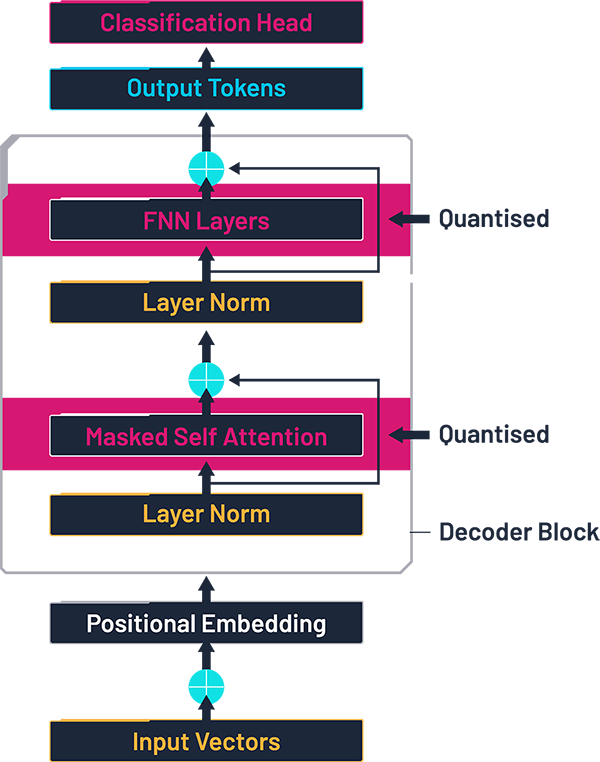
量化后的 Transformer 架构,基于文献 [3] 中的图示,并由作者修改。
后续章节将分析在各个块(blocks)和通道(channels)中出现的稀疏性特征。了解哪些层最先变得稀疏,可以为我们提供有关大型语言模型(LLM)中哪些层相对不那么重要的有价值见解。这一发现可能有助于未来优化工作的定向开展,特别是在那些冗余自然积累的部分。
自压缩的工作原理
自压缩方法 [1, 4] 使网络在常规神经网络训练过程中自主学习其通道宽度和数值精度。每个输出通道都通过一个可微分的函数进行量化。
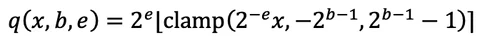
其中,比特深度 b≥0 和缩放指数 e 是可学习参数,其地位与神经网络权重相同。我们使用直通估计器(straight-through estimator),将取整操作的导数视为 1,从而使 b 和 e 能够接收正常的梯度。这种做法在如 PyTorch 等深度学习框架中实现起来非常简单。
训练过程旨在最小化原始任务损失 L(0),但我们额外引入了一个模型规模惩罚项 Q:
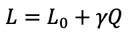
其中,Q 表示模型中每个通道平均使用的比特数,
γ 是由用户设定的惩罚系数。
在适当选择 γ 的情况下,该方法能够在保留基线精度的同时显著压缩模型总比特数,并且整个流程仍属于标准的训练范式。
自压缩后的权重表现
随着训练的进行,网络中的平均比特数逐步下降,同时验证损失也不断降低。训练初期,我们为每个权重分配了 4 比特,但在数百个 epoch 内,这一数值便下降了一半,最终逐渐稳定在约 每个权重 0.55 比特左右。
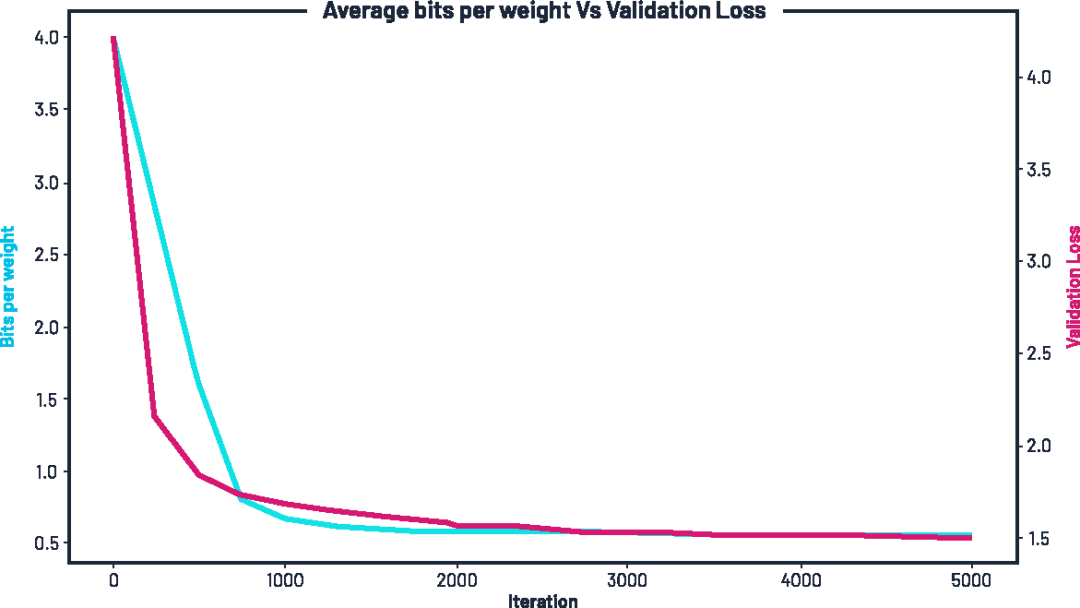
图示:训练过程中平均比特宽度的变化(蓝色,左轴)与验证损失(红色,右轴),在施加压缩惩罚项 γ 的条件下。
更有趣的现象出现在稀疏率及其随模型深度的变化上。我们观察到:稀疏性在模型更深层逐渐增强,这表明后期层的“信息密度”较低。在注意力模块中,深层 block 的线性层变得极为稀疏,第 4 和第 5 个 block 中有超过 95% 的权重被移除;前馈网络(feed-forward)中的线性层也变得非常稀疏,约有 85% 的权重被剪除;相比之下,第 0 层(最前层)保留了超过一半的权重,这可能是因为浅层在捕捉数据中的基本模式时至关重要。
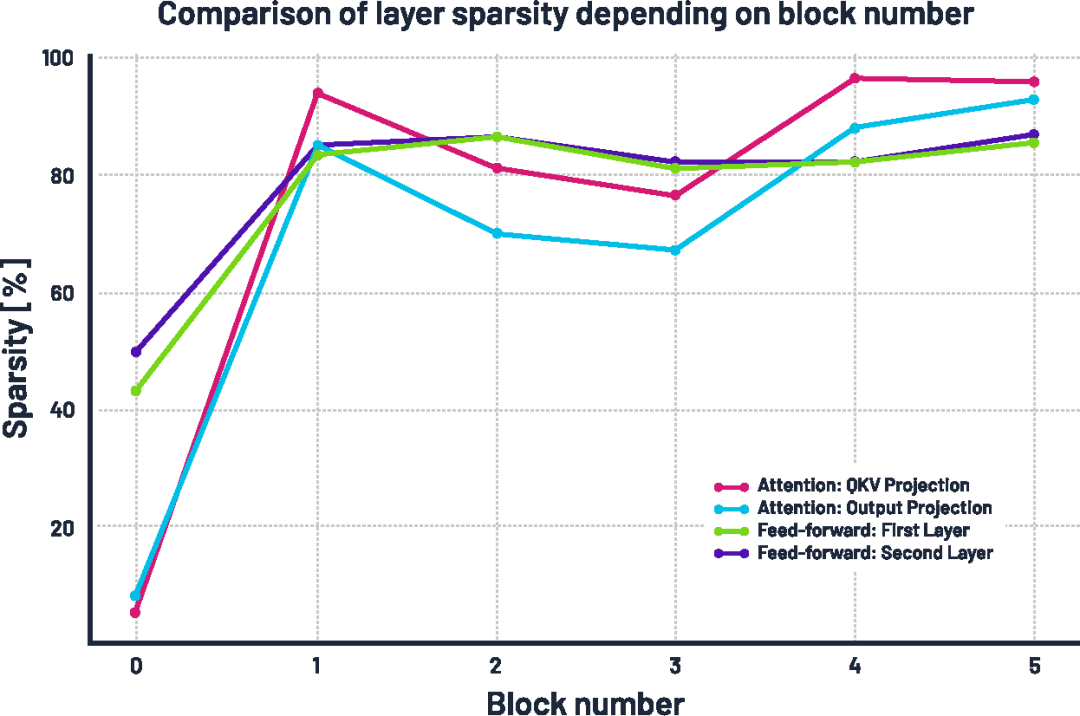
所有 Transformer 块中各线性层的稀疏率(即被清零权重所占百分比)。
如果这一现象能够推广到其他语言模型和任务中,那么即使不使用自压缩机制,也有可能通过在网络后段减少特征维度来获得性能收益。
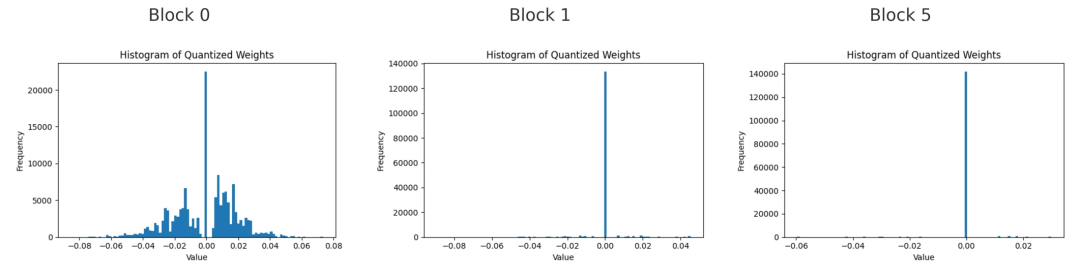
第0、1和5号块中,第一个前馈线性层的量化权重直方图。
当我们观察这三个块中权重的直方图时,会发现非零权重主要集中在靠近零的小数值附近,尤其是在较深的块中。这表明即使权重未被置零,模型也倾向于保持权重较小。块越深,剩余的大权重越少。这说明模型并不会通过增大剩余权重的幅度来弥补被剪除通道的损失。
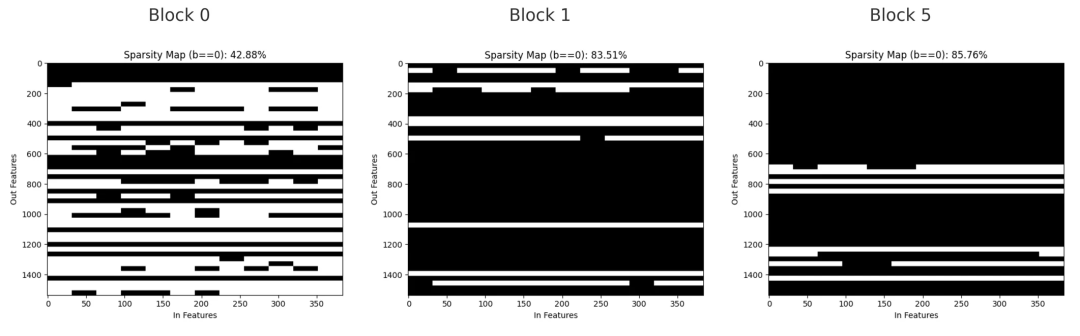
第0、1和5号块中,第一个前馈线性层的二值掩码图,黑色表示被剪除的权重,白色表示保留的权重。
稀疏掩码展示了被剪除权重的分布情况。在第0块,剪枝较为分散,呈现小间隙和细线条状,反映出个别通道被移除;在第1块,较大范围的权重被同时剪除,形成了横向带状区域,显示整个输出通道被删除;到第5块时,该层大部分权重已被剪除,只剩下少数几个通道保留。
结论
自压缩(Self-Compression)[1, 4] 同时降低了权重的比特宽度和活跃权重数量,同时形成了易于理解且在硬件上高效利用的通道稀疏模式。浅层大多保持稠密,以保留重要信息,而深层则变得高度稀疏。剩余的少数权重保持较小且接近零。这些结果表明,自压缩有助于构建更小、更快的模型,使其适合在资源受限的环境中运行,如边缘设备。
本文所展示的实验验证了自压缩方法能够成功缩减 Transformer 模型(此处以在字符级莎士比亚数据集上训练的 nanoGPT [3] 为例),且不会损害其预测质量。通过让模型自主决定保留哪些通道和权重,该方法避免了繁琐的手动调优,同时生成了结构清晰的块稀疏(block-sparse)模型,便于在 CPU、GPU、NPU 及其他硬件上高效部署。这意味着同一个紧凑模型可以无须额外修改,即可在整个边缘计算栈中通用。
未来的工作可以探索将该方法应用于更大型的语言模型、多模态 Transformer,或针对特定任务微调的模型,同时也可以尝试将自压缩与知识蒸馏等其他技术结合,以进一步提升效率。
关于作者
Jakub Przybyl是 Imagination Technologies 的中期实习生。他在弗罗茨瓦夫理工大学(Wrocław University of Science and Technology,简称 WUST)完成了机电一体化(Mechatronics)学士学位,同时攻读 IT 自动化系统硕士学位,专攻人工智能方向。他的研究兴趣包括机器学习、语言建模以及先进的网络压缩技术。
-
语言模型
+关注
关注
0文章
575浏览量
11383 -
LLM
+关注
关注
1文章
352浏览量
1419
发布评论请先 登录
大型语言模型在关键任务和实际应用中的挑战
探索高效的大型语言模型!大型语言模型的高效学习方法
【大语言模型:原理与工程实践】揭开大语言模型的面纱
KT利用NVIDIA AI平台训练大型语言模型
NVIDIA AI平台为大型语言模型带来巨大收益
利用大语言模型做多模态任务
浅析AI大型语言模型研究的发展历程
基于Transformer的大型语言模型(LLM)的内部机制

大型语言模型的应用
基于CPU的大型语言模型推理实验

如何利用大型语言模型驱动的搜索为公司创造价值

如何利用NPU与模型压缩技术优化边缘AI



评论