 如何利用NPU与模型压缩技术优化边缘AI
如何利用NPU与模型压缩技术优化边缘AI

| 本文作者:
Johanna Pingel,MathWorks 产品市场经理
Jack Ferrari,MathWorks 产品经理
Reed Axman,MathWorks 高级合作伙伴经理
随着人工智能模型从设计阶段走向实际部署,工程师面临着双重挑战:在计算能力和内存受限的嵌入式设备上实现实时性能。神经处理单元(NPU)作为强大的硬件解决方案,擅长处理 AI 模型密集的计算需求。然而,AI 模型体积庞大,部署在 NPU上常常面临困难,这凸显了模型压缩技术的重要性。要实现高效的实时边缘 AI,需要深入探讨NPU 与模型压缩技术(如量化与投影)如何协同工作。
NPU 如何在嵌入式设备上实现实时性能
在嵌入式设备上部署AI模型的关键挑战之一是最小化推理时间——即模型生成预测所需的时间,以确保系统具备实时响应能力。例如,在实时电机控制应用中,推理时间通常需要低于10 毫秒,以维持系统稳定性与响应性,并防止机械应力或部件损坏。工程师必须在速度、内存、功耗与预测质量之间取得平衡。
NPU 专为 AI 推理与神经网络计算而设计,非常适合处理能力有限且对能效要求极高的嵌入式系统。与通用处理器(CPU)或高性能但耗能较大的图形处理器(GPU)不同,NPU 针对神经网络中常见的矩阵运算进行了优化。虽然 GPU 也能执行AI推理任务,但 NPU 在成本与能耗方面更具优势。
从成本角度看,NPU是比微控制器(MCU)、GPU 或 FPGA 更具经济性的AI处理方案。尽管集成 NPU 的芯片初期成本可能高于传统微控制器,但其卓越的能效与 AI 处理能力使其在整体价值上更具吸引力。NPU专为加速神经网络推理而设计,在功耗远低于 CPU 的同时提供更高的性能。这种效率不仅降低了运行成本,还延长了嵌入式设备的电池寿命,从而在长期使用中更具成本效益。此外,NPU 可实现实时AI处理,无需依赖更昂贵、耗能更高的 GPU 或 FPGA,进一步增强了其经济吸引力。
NPU 是一种经济、高能效的解决方案,专为嵌入式系统中的高效 AI 推理与神经网络计算而设计。
尽管 NPU 在 AI 推理方面效率极高,但在嵌入式系统中,其内存与功耗仍然有限。因此,模型压缩成为关键手段,以减小模型体积与复杂度,使 NPU 在不超出系统限制的前提下实现实时性能。
利用投影与量化压缩 AI 模型
模型压缩技术通过减小模型体积与复杂度,提升推理速度并降低功耗,从而帮助大型AI模型部署到边缘设备。然而,过度压缩可能会影响预测精度,因此工程师需谨慎评估在满足硬件限制的前提下可接受的精度损失范围。
投影与量化是两种互补的压缩技术,可联合使用以优化 AI 模型在 NPU 上的部署。投影通过移除冗余的可学习参数来减小模型结构,而量化则将剩余参数转换为低精度(通常为整数)数据类型,从而进一步压缩模型。两者结合可同时压缩模型结构与数据类型,在保持精度的同时提升效率。
推荐的做法是先使用投影对模型进行结构压缩,降低其复杂度与体积,再应用量化以进一步减少内存占用与计算成本。
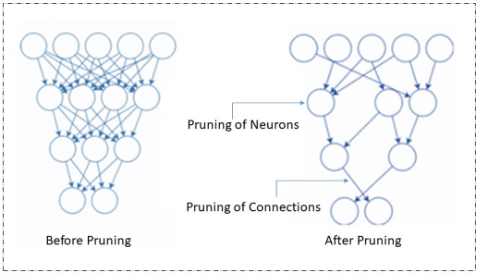
投影
神经网络投影是一种结构压缩技术,可通过将层的权重矩阵投影到低维子空间来减少模型中的可学习参数。在MATLAB Deep Learning Toolbox中,该方法基于主成分分析(PCA),识别神经激活中变化最大的方向,并通过更小、更高效的表示来近似高维权重矩阵,从而移除冗余参数。这种方式在保留模型准确性与表达能力的同时,显著降低了内存与计算需求。
量化
量化是一种数据类型压缩技术,通过将模型中的可学习参数(权重与偏置)从高精度浮点数转换为低精度定点整数类型,来减少模型的内存占用与计算复杂度。这种方法可显著提升模型的推理速度,尤其适用于NPU部署。虽然量化会带来一定的数值精度损失,但通过使用代表实际运行情况的输入数据对模型进行校准,通常可以在可接受的范围内保持准确性,满足实时应用需求。
应用案例:在 STMicroelectronics 微控制器上部署量化模型
STMicroelectronics 开发了一套基于 MATLAB 与 Simulink 的工作流程,用于将深度学习模型部署到 STM32 微控制器。工程师首先设计并训练模型,随后进行超参数调优与知识蒸馏以降低模型复杂度。接着,他们应用投影技术移除冗余参数以实现结构压缩,并使用量化将权重与激活值转换为8位整数,从而减少内存使用并提升推理速度。这种双阶段压缩方法使得深度学习模型能够在资源受限的 NPU 与 MCU 上部署,同时保持实时性能。
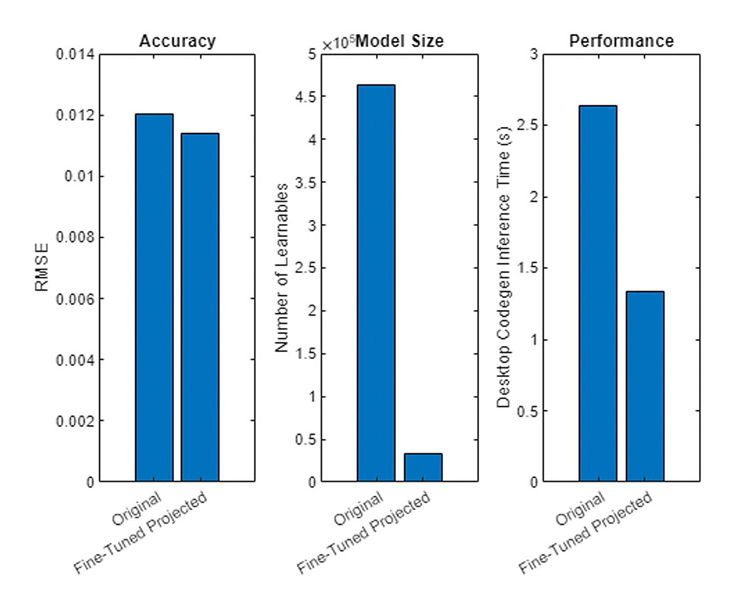
对一个包含LSTM层的循环神经网络在建模电池荷电状态时,投影并调优前后的准确率、模型大小与推理速度进行对比。
在 NPU上部署 AI 模型的最佳实践
投影与量化等模型压缩技术可显著提升 AI 模型在 NPU 上的性能与可部署性。然而,由于压缩可能影响模型精度,因此必须通过仿真与硬件在环(HIL)验证进行迭代测试,以确保模型满足功能与资源要求。尽早且频繁地测试有助于工程师在问题扩大前及时发现并解决,从而降低后期返工风险,确保嵌入式系统部署顺利进行。
统一的开发生态系统也能解决 AI 模型部署中面临的诸多挑战,简化集成流程,加快开发进度,并在整个过程中支持全面测试。在当今软件环境日益碎片化的背景下,这一点尤为重要。工程师常常需要将不同代码库集成到仿真流程或更大的系统环境中。由于各平台与标准开发环境分离,集成与验证的复杂性进一步增加。引入 NPU 后,工具链的复杂性也随之上升,因此更需要统一的生态系统来应对这些挑战。
面向边缘设计:在功耗、精度与性能之间寻求平衡
嵌入式 AI 的未来以性能为核心,专为边缘环境而构建,并由驱动复杂工程系统的 AI 模型提供动力。工程师的成功依赖于对模型压缩权衡的深入理解、在硬件上尽早进行测试,以及构建具备适应性的系统。通过将智能的 NPU 与 AI 模型设计相结合,并辅以战略性的压缩技术,工程师能够将嵌入式设备转变为强大的实时决策引擎。
| 本文作者
Johanna Pingel, MathWorks
Johanna Pingel 是 MathWorks 的产品市场经理。她专注于机器学习和深度学习应用,致力于让人工智能变得实用、有趣且易于实现。她于 2013 年加入公司,专长于使用 MATLAB 进行图像处理和计算机视觉应用。
Jack Ferrari, MathWorks
Jack Ferrari 是 MathWorks 的产品经理,致力于帮助 MATLAB 和 Simulink 用户将 AI 模型压缩并部署到边缘设备和嵌入式系统中。他拥有与多个行业客户合作的经验,包括汽车、航空航天和医疗器械行业。Jack 拥有波士顿大学机械工程学士学位。
Reed Axman, MathWork
Reed Axman 是 MathWorks 的高级合作伙伴经理,负责为 STMicroelectronics、Texas Instruments 和 Qualcomm 等公司提供以硬件为中心的 AI 工作流程支持。他与 MathWorks 的合作伙伴及内部团队协作,帮助客户将嵌入式 AI 能力集成到其产品中。他拥有亚利桑那州立大学机器人与人工智能硕士学位,研究方向为用于医疗应用的软体机器人。
-
嵌入式
+关注
关注
5186文章
20143浏览量
328644 -
AI
+关注
关注
89文章
38083浏览量
296312 -
模型
+关注
关注
1文章
3648浏览量
51692 -
NPU
+关注
关注
2文章
358浏览量
20823
原文标题:更智能、更小巧、更快速:工程师如何通过 NPU 与模型压缩优化边缘 AI
文章出处:【微信号:MATLAB,微信公众号:MATLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
模型压缩技术,加速AI大模型在终端侧的应用
NanoEdge AI的技术原理、应用场景及优势
AI赋能边缘网关:开启智能时代的新蓝海
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?
如何精准驱动菜品识别模型--基于米尔瑞芯微RK3576边缘计算盒
【HarmonyOS HiSpark AI Camera】边缘计算安全监控系统
音频处理SoC在500 µW以下运行AI
基于RKNN程序开发和模型转换的NPU简要说明
嵌入式边缘AI应用开发指南
ST MCU边缘AI开发者云 - STM32Cube.AI
边缘AI的模型压缩技术
边缘AI的模型压缩技术





 工商网监
工商网监
评论