 TI Edge AI - AM6xA 处理器与深度学习加速器及其效率
TI Edge AI - AM6xA 处理器与深度学习加速器及其效率

TI 处理器与深度学习加速器
[TI]的AM6xA(如[AM68Ax]和[AM69Ax])边缘AI处理器采用异构架构,带有用于深度学习计算的专用加速器。这个加速器被称为MMA -矩阵乘法加速器。该MMA与TI自己的C7x数字信号处理器一起,可以进行高效的张量,矢量和标量处理。加速器是独立的深度学习处理,不依赖于主机ARM CPU。由于模型计算有大量的数据传输,加速器有自己的DMA引擎和内存子系统,与SoC的其余部分连接到相同的DDR。这与专有的Super-tiling技术一起,导致高达90%的加速器引擎利用率和DDR带宽驱动尽可能低的功耗,以实现节能计算。
*附件:am68a 数据手册.pdf
*附件:am69a数据手册.pdf
 image586×586 85.1 KB
image586×586 85.1 KBMMA架构(来源:TI)
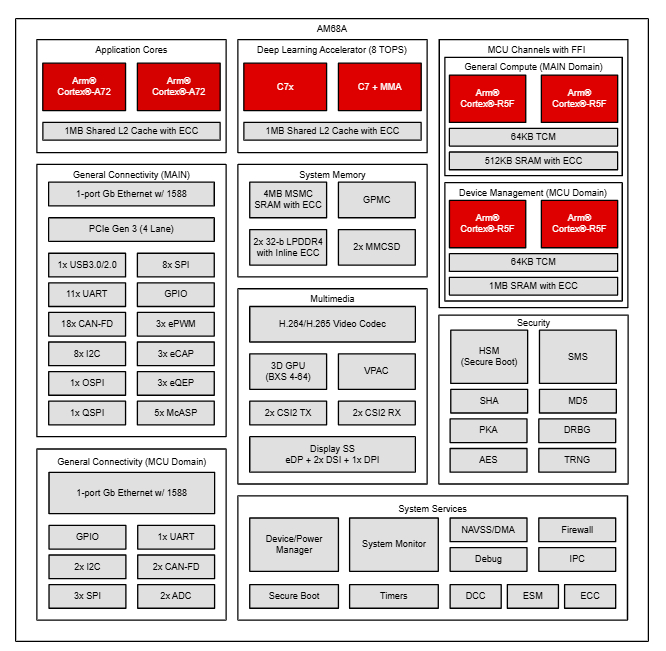
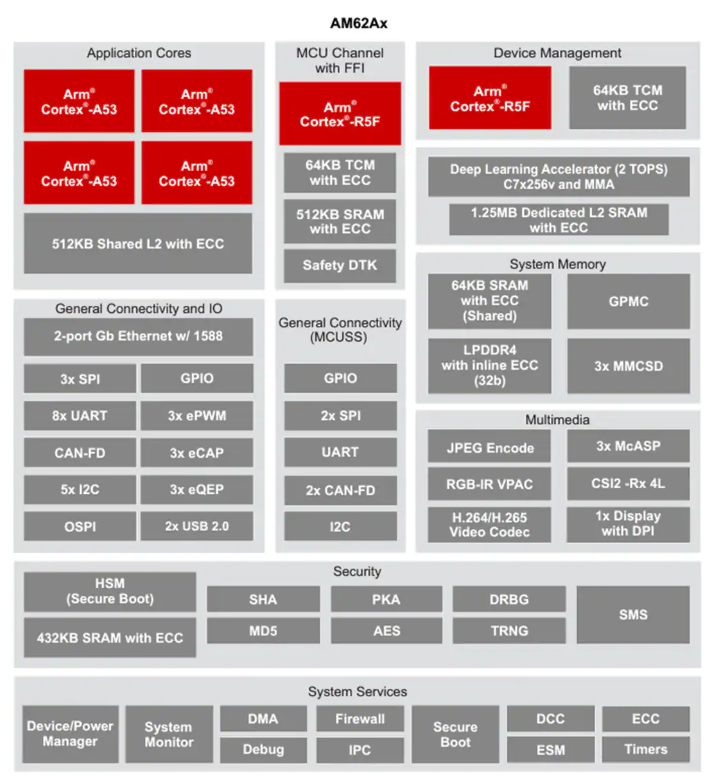
使用MMA作为AI功能的加速,整体SoC框图如下图所示。产品组合中的每个边缘AI设备(如AM62A、AM68A等)的架构都是相似的。
 image865×320 68.2 KB
image865×320 68.2 KBAM6xA处理器框图(来源:TI)
基于异构架构,片上系统(SoC)经过优化,可在多核Cortex-A微处理单元(mpu)上轻松编程,同时集成深度学习、成像、视觉、视频和图形处理等计算密集型任务。任务被卸载到专用硬件加速器和可编程核心上。使用高带宽互连和智能存储器架构对这些核心进行整体系统级集成,可实现高吞吐量和能源效率。通过系统组件的预集成实现优化的系统BOM。请注意,像AM62A这样的成本和功耗优化的SoC并不包括所有硬件功能,例如GPU和DMPAC,或者可能包括性能降低的加速器变体以降低功耗。
深度学习效率
通常,TOPS(每秒tera次操作)用于衡量深度学习的性能比较。TOPS不能完全涵盖深度学习性能的所有方面,因为它还依赖于内存(DDR)容量和神经网络架构。
实际的推理时间取决于系统架构利用系统中最优数据流的效率。因此,更好的性能基准是给定模型在给定输入图像分辨率下的推理时间。更快的推理时间允许处理更多的图像,从而产生更高的每秒帧数(FPS)。因此,FPS除以TOPS (FPS/TOPS)显示了建筑的效率。同样,FPS/瓦特是嵌入式处理器能源效率的一个很好的基准。
特性
处理器内核:
- 高达双 64 位 Arm Cortex-A72 微处理器子系统,频率高达 2GHz
- 每个双核 Cortex-A72 群集 1MB 共享 L2 缓存
- 每个 Cortex-A72 内核 32KB L1 D-Cache 和 48KB L1 I-Cache
- 深度学习加速器:
- 高达 8 万亿次每秒作 (TOPS)
- 带有图像信号处理器 (ISP) 和多个视觉辅助加速器的视觉处理加速器 (VPAC)
- 双核 Arm Cortex-R5F MCU,在通用计算分区中高达 1.0GHz,带 FFI
- 16KB L1 D-Cache、16KB L1 I-Cache 和 64KB L2 TCM
- 双核 Arm® Cortex-R5F® MCU,频率高达 1.0 GHz,支持设备管理
- 32K L1 D-Cache、32K I-Cache 和 64K L2 TCM,所有内存均支持 SECDED ECC
- 带有图像信号处理器 (ISP) 和多个视觉辅助加速器的视觉处理加速器 (VPAC)
- 480 MPixel/s 图像处理器
- 支持高达 16 位的输入 RAW 格式
- 宽动态范围 (WDR)、镜头畸变校正 (LDC)、视觉成像子系统 (VISS) 和多标量 (MSC) 支持
- 输出颜色格式 : 8 位、12 位和 YUV 4:2:2、YUV 4:2:0、RGB、HSV/HSL
多媒体:
- 显示子系统支持:
- 3D 图形处理单元
- IMG BXS-4-64,高达 800MHz
- 50GFLOPS,4GTexels/秒
500MTexels/s,>8GFLOPs
- 支持至少 2 个合成图层
- 最高支持 2048x1080 @60fps
- 支持 ARGB32、RGB565 和 YUV 格式
- 支持 2D 图形
- OpenGL ES 3.1、Vulkan 1.2
- 两个 CSI2.0 4L 摄像机串行接口 (CSI-Rx) 加上带 DPHY 的 CSI2.- 4L Tx (CSI-Tx)
- 视频编码器/解码器
- 支持 5.1 级高级的 HEVC (H.265) 主要配置文件
- 支持 5.2 级 H.264 BaseLine/Main/High 配置文件
- 支持高达 4K UHD 分辨率 (3840 × 2160)
- 4K60 H.264/H.265 编码/解码(高达 480MP/s)
内存子系统:
- 高达 4MB 的片上 L3 RAM,具有 ECC 和一致性
- ECC 错误保护
- 共享一致性缓存
- 支持内部 DMA 引擎
- 最多两个带 ECC 的外部内存接口 (EMIF) 模块
- 支持 LPDDR4 内存类型
- 支持高达 4266MT/s 的速度
- 多达 2 个 32 位数据总线,每个 EMIF 具有高达 17GB/s 的内联 ECC
- 通用内存控制器 (GPMC)
- 在 MAIN 域中最多两个 512KB 片上 SRAM,受 ECC 保护
设备安全性:
- 具有安全运行时支持的安全启动
- 客户可编程根密钥,最高 RSA-4K 或 ECC-512
- 嵌入式硬件安全模块
- 加密硬件加速器 – 具有 ECC、AES、SHA、RNG、DES 和 3DES 的 PKA
高速串行接口:
- 一个 PCI-Express (PCIe) Gen3 控制器
- 每个控制器最多 4 个通道
- 第 1 代 (2.5GT/s)、第 2 代 (5.0GT/s) 和第 3 代 (8.0GT/s)作,具有自动协商功能
- 一个 USB 3.0 双角色设备 (DRD) 子系统
- 两个 CSI2.0 4L 摄像机串行接口 RX (CSI-RX) 和两个带 DPHY 的 CSI2.0 4L TX (CSI-TX)
- 符合 MIPI CSI 1.3 标准 + MIPI-DPHY 1.2
- CSI-RX 支持 1、2、3 或 4 数据通道模式,每通道高达 2.5Gbps
- CSI-TX 支持 1、2 或 4 数据通道模式,每通道高达 2.5Gbps
以太网:
- 两个以太网 RMII/RGMII 接口
闪存接口:
- 嵌入式多媒体卡接口 (eMMC™ 5.1)
- 1 个安全数字 3.0/安全数字输入输出 3.0 接口 (SD3.0/SDIO3.0)
- 两个同步闪存接口配置为
- 一个 OSPI 或 HyperBus™ 或 QSPI,以及
- 一个 QSPI
技术/封装:
- 16nm FinFET 技术
- 23mm x 23mm、0.8mm 间距、770 引脚 FCBGA (ALZ)
技术文档
=TI 选择的此产品的热门文档
-
处理器
+关注
关注
68文章
20332浏览量
254917 -
加速器
+关注
关注
2文章
841浏览量
40240 -
AI
+关注
关注
91文章
41101浏览量
302580 -
深度学习
+关注
关注
73文章
5607浏览量
124625
发布评论请先 登录
使用NORDIC AI的好处
边缘计算中的AI加速器类型与应用

TDA4VL-Q1处理器技术文档总结
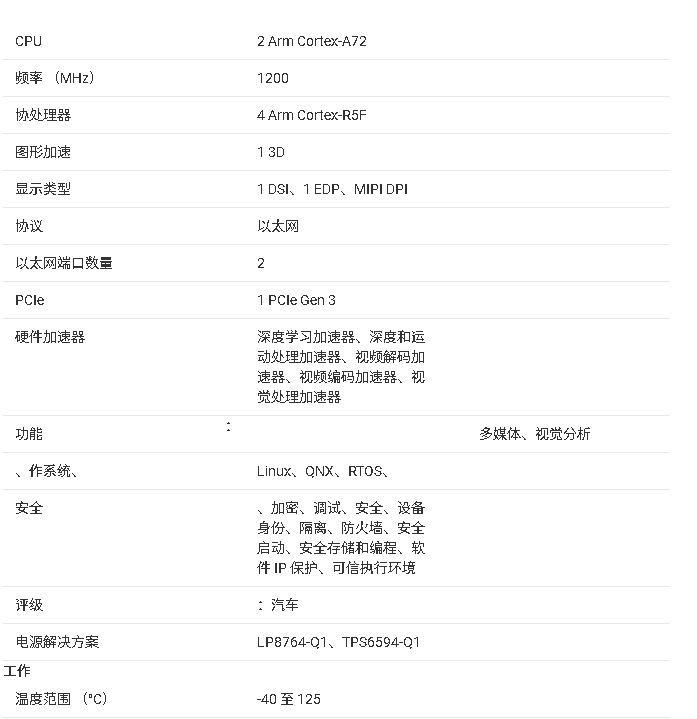
TDA4AL-Q1处理器的技术文档摘要
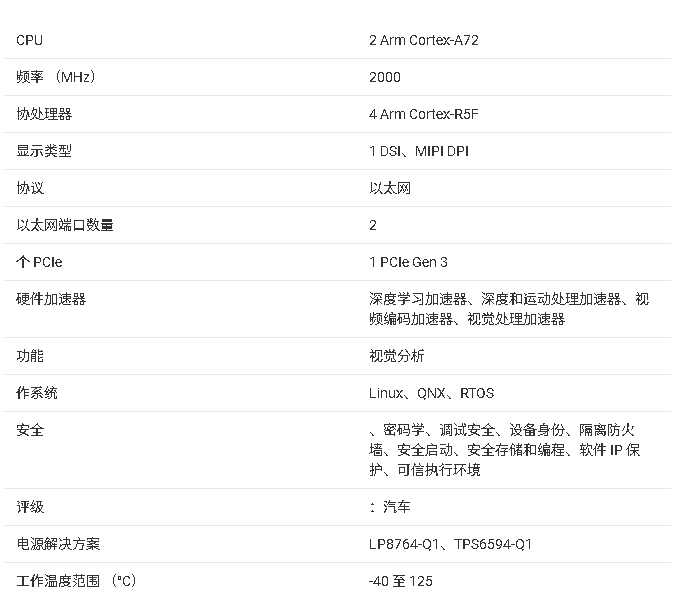
AM68A/AM68处理器技术文档摘要
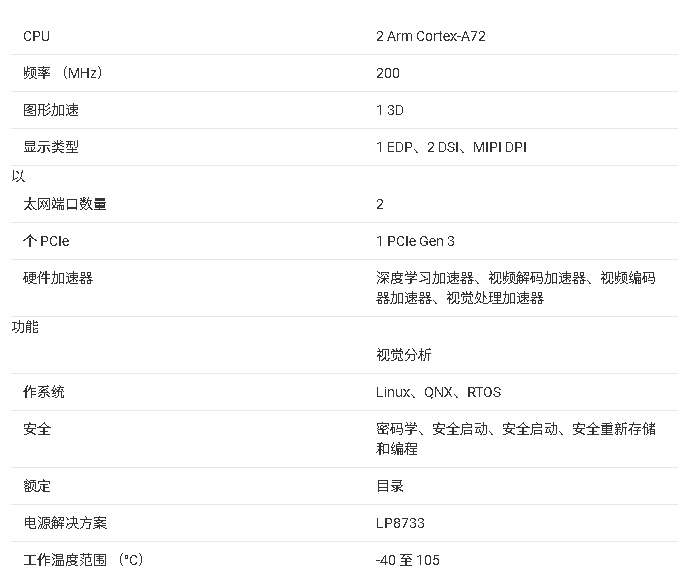
AM62A7-Q1处理器的技术文档总结
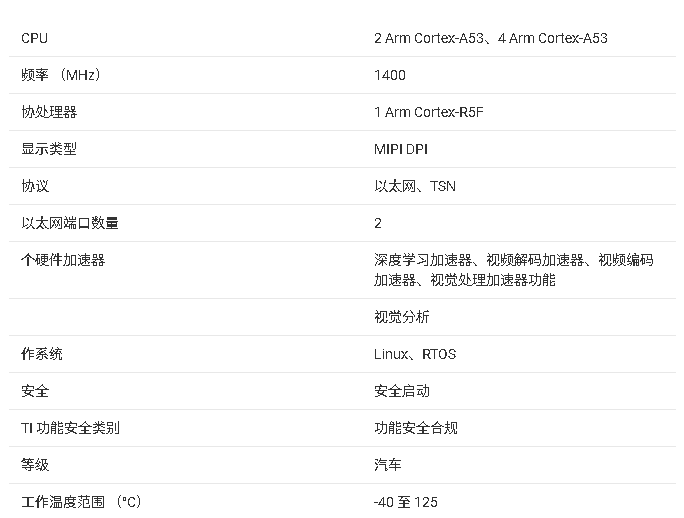
AM62Ax处理器技术文档总结
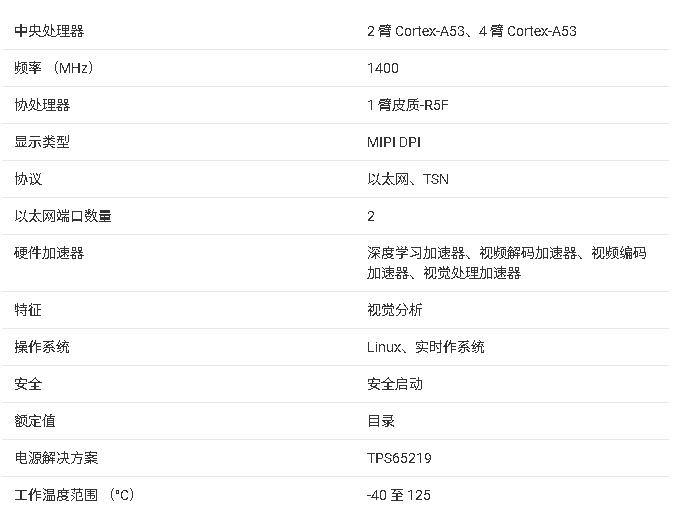
AM62A3处理器技术文档总结

AM67x处理器技术文档总结

【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
德州仪器AM68x Jacinto 8处理器技术解析
英特尔Gaudi 2E AI加速器为DeepSeek-V3.1提供加速支持

Andes晶心科技推出新一代深度学习加速器
德州仪器AM62Ax Sitara™处理器技术解析
Texas Instruments 适用于AM64x Sitalog ™处理器的SK-AM64B入门套件数据手册




评论