 如何利用Splunk最新的Metrics Store来对Kubernetes的集群进行性能监控
如何利用Splunk最新的Metrics Store来对Kubernetes的集群进行性能监控

Kubernetes已经成为容器编排的事实上的王者,连Docker都已经向K8s女王大人低头。对于Kubernetes的cluster的数据收集和监控已经成为IT运维的一个重要话题。我们今天来看一看如何利用Splunk最新的Metrics Store来对Kubernetes的集群进行性能监控。
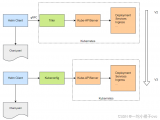
部署架构
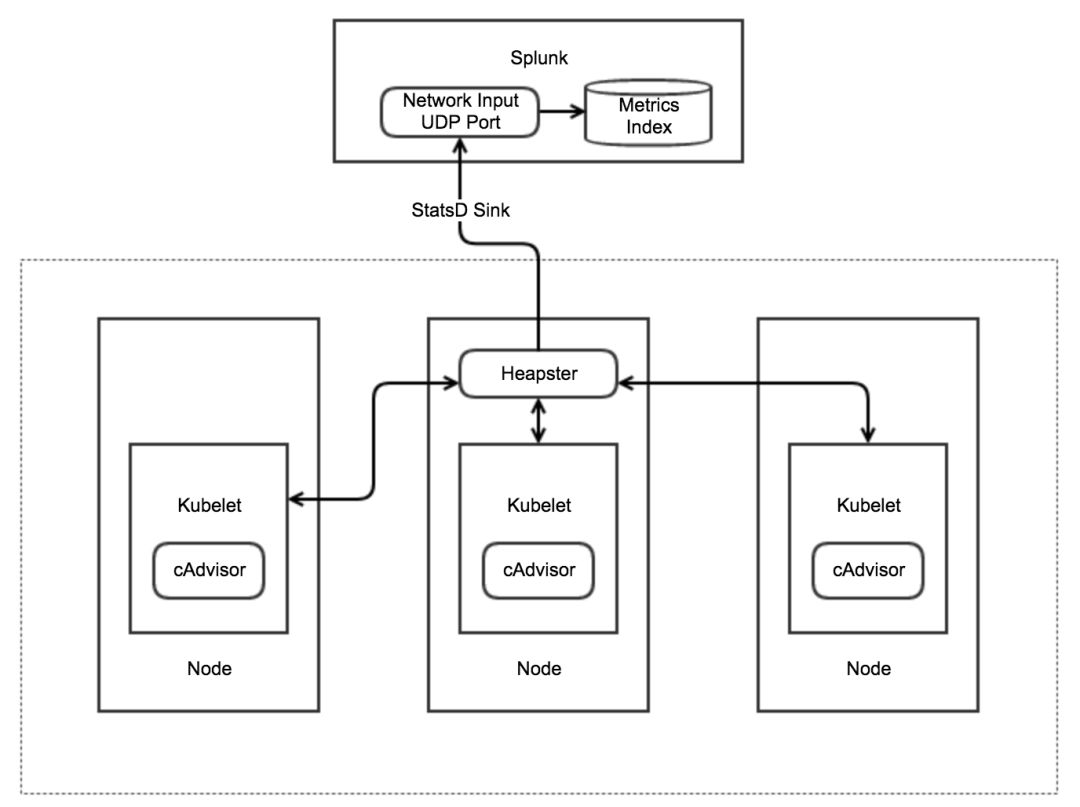
下图是该方案的部署架构,主要包括:
利用Heapster收集K8s的性能数据,包含CPU,Memory,Network,File System等
利用Heapster的Statsd Sink,发送数据到Splunk的Metrics Store
利用Splunk的搜索命令和仪表盘功能对性能数据进行监控
前期准备
前期主要要准备好两件事:
编译最新的Heapster的镜像,并上传到某个公共的Docker镜像仓库,例如docker hub
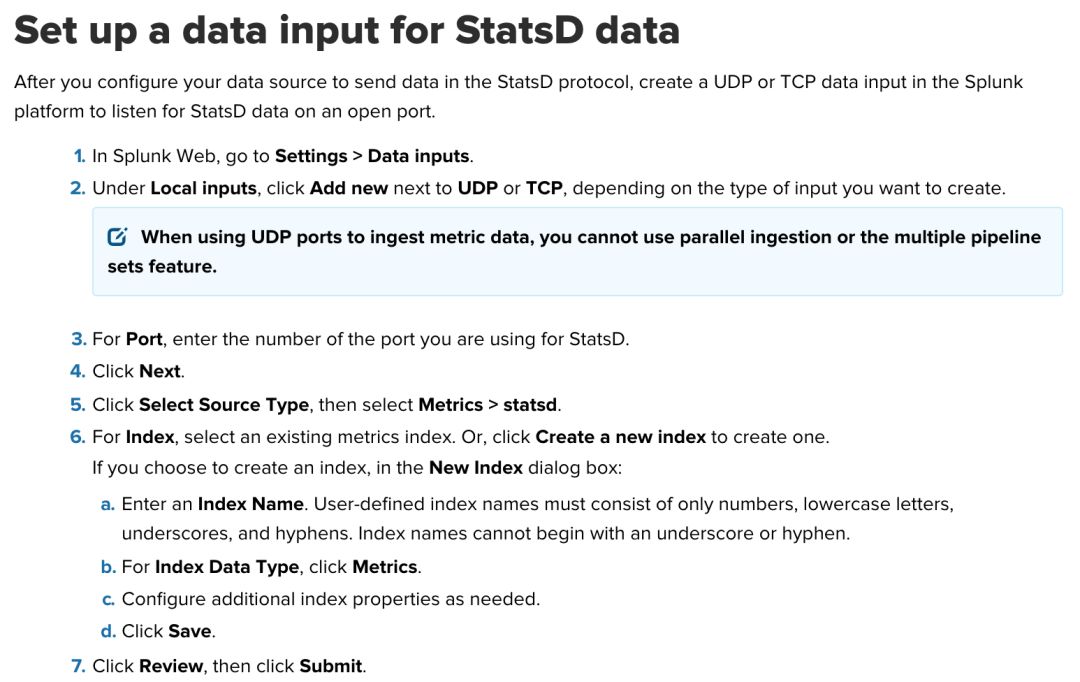
在Splunk中配置Metrics Store和对应的网络输入(Network Input UDP/TCP)
这里主要要做的选择是Statsd的传输协议用UDP还是TCP。这里我推荐使用TCP。 最新的Heapster代码支持不同的Backend,包含了log, influxdb, stackdriver, gcp monitoring, gcp logging, statsd, hawkular-metrics, wavefront, openTSDB, kafka, riemann, elasticsearch等等。因为Splunk的Metrics Store支持statsd协议,所以可以很容易的和Heapster集成。
首先我们需要利用最新的heapster代码,编译一个容器镜像,因为docker hub上的heapsterd的官方镜像的版本比较旧,并不支持statsd。所以需要自己编译。
mkdir myheapstermkdir myheapster/srcexport GOPATH=myheapstercd myheapster/srcgit clone https://github.com/kubernetes/heapster.gitcd heapstermake container
运行以上的命令来编译最新的heapster镜像。
注意,heapster缺省使用udp协议,如果想要使用tcp,需要修改代码
https://github.com/kubernetes/heapster/blob/master/metrics/sinks/statsd/statsd_client.go
func (client *statsdClientImpl) open() error { var err error client.conn, err = net.Dial("udp", client.host) if err != nil { glog.Errorf("Failed to open statsd client connection : %v", err) } else { glog.V(2).Infof("statsd client connection opened : %+v", client.conn) } return err}
把udp改成tcp。
我在docker hub上放了两个镜像,分别对应udp版本的tcp版本,大家可以直接使用
naughtytao/heapster-amd64:v1.5.0-beta.3 udp
naughtytao/heapster-amd64:v1.5.0-beta.4 tcp
然后需要在Splunk中配置Metrics Store,参考这个文档
安装配置Heapster
在K8s上部署heapster比较容易,创建对应的yaml配置文件,然后用kubectl命令行创建就好了。
以下是Deployment和Service的配置文件:
deployment.yaml
apiVersion: extensions/v1beta1kind: Deploymentmetadata: name: heapster namespace: kube-systemspec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster version: v6 spec: containers: - name: heapster image: naughtytao/heapster-amd64:v1.5.0-beta.3 imagePullPolicy: Always command: - /heapster - --source=kubernetes:https://kubernetes.default - --sink=statsd:udp://ip:port?numMetricsPerMsg=1
service.yaml
apiVersion: v1kind: Servicemetadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-systemspec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster
注意这里deployment的--sink的配置,ip是Splunk的IP或者主机名,port的对应的Splunk的data input的端口号。当使用udp协议的时候,需要配置的numMetricsPerMsg的值比较小,当这个值比较大的时候,会出message too long的error。当使用tcp的时候可以配置较大的数值。
运行 kubectl apply -f *.yaml 来部署heapster
如果正常运行,对应的heapster pod的日志如下
I0117 18:10:56.054746 1 heapster.go:78] /heapster --source=kubernetes:https://kubernetes.default --sink=statsd:udp://ec2-34-203-25-154.compute-1.amazonaws.com:8124?numMetricsPerMsg=10I0117 18:10:56.054776 1 heapster.go:79] Heapster version v1.5.0-beta.4I0117 18:10:56.054963 1 configs.go:61] Using Kubernetes client with master "https://kubernetes.default" and version v1I0117 18:10:56.054978 1 configs.go:62] Using kubelet port 10255I0117 18:10:56.076200 1 driver.go:104] statsd metrics sink using configuration : {host:ec2-34-203-25-154.compute-1.amazonaws.com:8124 prefix: numMetricsPerMsg:10 protocolType:etsystatsd renameLabels:map[] allowedLabels:map[] customizeLabel:0x15fc8c0}I0117 18:10:56.076248 1 driver.go:104] statsd metrics sink using configuration : {host:ec2-34-203-25-154.compute-1.amazonaws.com:8124 prefix: numMetricsPerMsg:10 protocolType:etsystatsd renameLabels:map[] allowedLabels:map[] customizeLabel:0x15fc8c0}I0117 18:10:56.076272 1 heapster.go:202] Starting with StatsD SinkI0117 18:10:56.076281 1 heapster.go:202] Starting with Metric SinkI0117 18:10:56.090229 1 heapster.go:112] Starting heapster on port 8082
在Splunk中进行监控
好了如果一切正常的化,heapster会用statsd的协议和格式发送metrics到Splunk的metrics store。
然后就可以用利用SPL的mstats和mcatalog命令来分析,监控metrics数据了。
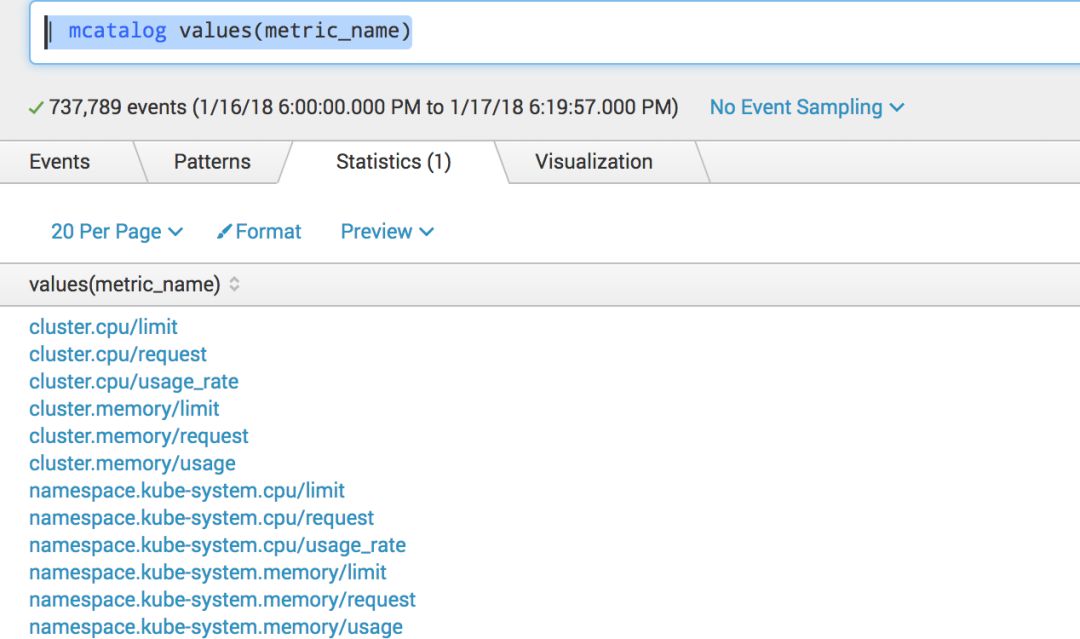
以下搜索语句列出所有的Metrics
| mcatalog values(metric_name)
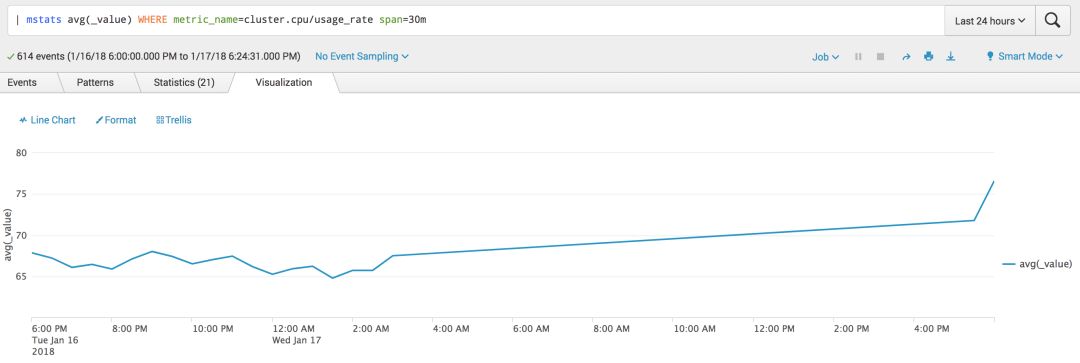
以下搜索语句列出整个cluster的CPU使用,我们可以用Area或者Line Chart来可视化搜索结果。
| mstats avg(_value) WHERE metric_name=cluster.cpu/usage_rate span=30m
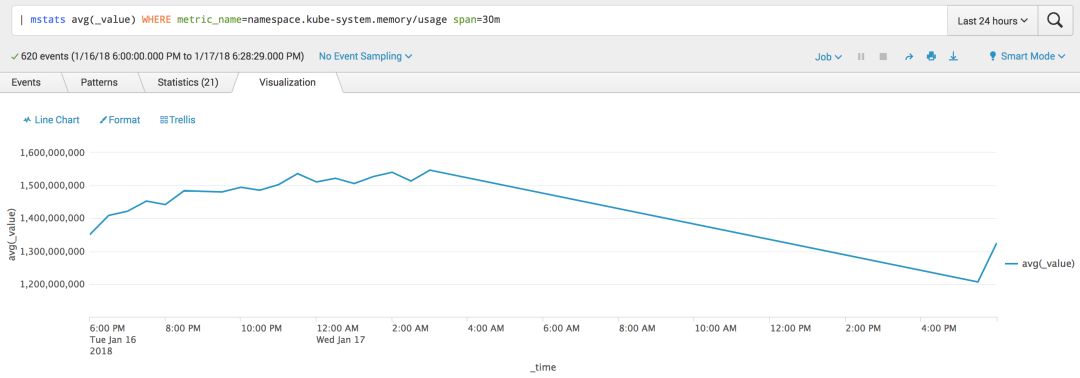
kube-system namespace的对应内存使用情况
| mstats avg(_value) WHERE metric_name=namespace.kube-system.memory/usage span=30m
大家可以把自己感兴趣的分析结果放在Dashboard中,利用Realtime设置进行监控。
好了,更多的分析选项可以参考Splunk文档。
-
cpu
+关注
关注
68文章
11323浏览量
225835 -
数据收集
+关注
关注
0文章
73浏览量
11762 -
kubernetes
+关注
关注
0文章
274浏览量
9530
原文标题:使用Heapster和Splunk监控Kubernetes运行性能
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Kubernetes Ingress Controller对比解析
Prometheus千节点集群的横向扩展实践
Kubernetes Pod异常问题排查实战
KubePi:开源Kubernetes可视化管理面板,让集群管理如此简单
Kubernetes kubectl命令行工具详解
借助京东AI言犀提升Kubernetes集群巡检的效率和准确性
Kubernetes安全加固的核心技术
高效管理Kubernetes集群的实用技巧
基于eBPF的Kubernetes网络异常检测系统
Redis集群部署与性能优化实战
使用树莓派构建 Slurm 高性能计算集群:分步指南!

Ubuntu K8s集群安全加固方案
Kubernetes Helm入门指南



评论