 算力积木+3D堆叠!GPNPU架构创新,应对AI推理需求
算力积木+3D堆叠!GPNPU架构创新,应对AI推理需求

电子发烧友网报道(文/李弯弯)2025年,人工智能正式迈入应用推理时代。大模型从实验室走向千行百业,推理需求呈指数级爆发。然而,高昂的推理成本与有限的算力供给之间的矛盾日益凸显,成为制约AI规模化落地的关键瓶颈。在此背景下,云天励飞推出其第五代芯片架构——GPNPU(General-Purpose Neural Processing Unit,通用神经网络处理单元),以一场底层架构的革命,试图重塑AI算力格局,推动大模型推理走向极致性价比时代。
GPNPU的核心定位是:做推理时代的优等生。它摒弃了传统芯片追求大而全的通用计算思路,转而聚焦大模型推理的核心场景,如Prefill准备阶段和Decode生成阶段,进行深度定制与优化。其目标极具挑战性:将当前约1美元/百万Token的推理成本,压缩至仅需1美分/百万Token,实现百倍效率提升。
GPNPU的黑科技源于三大底层创新。首先是算力积木设计思想。传统芯片往往一刀切,难以兼顾云、边、端多样化的部署需求。GPNPU采用模块化架构,如同乐高积木般可灵活堆叠,实现一次流片、多规格输出。其算力覆盖从8T到256T,既能支撑云端大模型推理,也能赋能边缘设备与终端智能体,如机器人、手机、AR眼镜,真正实现全场景覆盖。
其次,GPNPU采用3D堆叠存储技术,直面内存墙难题。大模型推理对带宽极为敏感,数据搬运速度常成为性能瓶颈。通过3D堆叠,GPNPU大幅提升存储密度与带宽利用率,让计算单元得以持续满血运行,显著提升能效比。
第三,GPNPU实现异构化与灵活调度。它深刻洞察到推理任务的动态特性:Prefill阶段重算力,Decode阶段重带宽。因此,通过软硬协同优化,GPNPU可动态调整算力、带宽与存储的配比,不再依赖单一芯片硬扛,而是以灵活架构适配任务变化,实现资源最优利用。
与传统架构相比,GPNPU展现出显著差异化优势。传统GPU虽生态成熟、通用性强,但推理成本高昂;传统NPU能效较高,但多聚焦终端推理,通用性受限。而GPNPU则兼具GPU的通用性与NPU的高能效,专为大模型推理优化,覆盖端、边、云全场景,并以算力积木实现前所未有的架构灵活性,真正实现极致性价比。
目前,基于GPNPU架构的芯片正加速落地。正在研发的Nova 500系列,作为第五代GPNPU芯片,重点提升带宽与能效,是实现“1元内搞定百万Token”目标的关键一步。展望未来,Nova 600系列将探索光电一体化互联,构建高性价比的算力网络,进一步将推理成本推向分级成本新低。
依托GPNPU,云天励飞已构建“深穹”(云端)、“深界”(边缘)、“深擎”(具身智能)三大芯片产品矩阵,全面服务于互联网大厂、智能终端厂商与机器人企业,推动AI应用的广泛落地。
在国产工艺受限、高端GPU供应不确定的现实下,云天励飞没有选择在制程工艺上硬拼,而是以架构创新另辟蹊径。GPNPU不仅是技术的突破,更是一种战略智慧的体现——通过“算力积木+3D堆叠”的创新路径,走出一条高能效、低成本、全场景的差异化发展之路。它预示着,AI算力将不再昂贵稀缺,而是如水电般普惠,真正赋能千行百业的智能化变革。
GPNPU的核心定位是:做推理时代的优等生。它摒弃了传统芯片追求大而全的通用计算思路,转而聚焦大模型推理的核心场景,如Prefill准备阶段和Decode生成阶段,进行深度定制与优化。其目标极具挑战性:将当前约1美元/百万Token的推理成本,压缩至仅需1美分/百万Token,实现百倍效率提升。
GPNPU的黑科技源于三大底层创新。首先是算力积木设计思想。传统芯片往往一刀切,难以兼顾云、边、端多样化的部署需求。GPNPU采用模块化架构,如同乐高积木般可灵活堆叠,实现一次流片、多规格输出。其算力覆盖从8T到256T,既能支撑云端大模型推理,也能赋能边缘设备与终端智能体,如机器人、手机、AR眼镜,真正实现全场景覆盖。
其次,GPNPU采用3D堆叠存储技术,直面内存墙难题。大模型推理对带宽极为敏感,数据搬运速度常成为性能瓶颈。通过3D堆叠,GPNPU大幅提升存储密度与带宽利用率,让计算单元得以持续满血运行,显著提升能效比。
第三,GPNPU实现异构化与灵活调度。它深刻洞察到推理任务的动态特性:Prefill阶段重算力,Decode阶段重带宽。因此,通过软硬协同优化,GPNPU可动态调整算力、带宽与存储的配比,不再依赖单一芯片硬扛,而是以灵活架构适配任务变化,实现资源最优利用。
与传统架构相比,GPNPU展现出显著差异化优势。传统GPU虽生态成熟、通用性强,但推理成本高昂;传统NPU能效较高,但多聚焦终端推理,通用性受限。而GPNPU则兼具GPU的通用性与NPU的高能效,专为大模型推理优化,覆盖端、边、云全场景,并以算力积木实现前所未有的架构灵活性,真正实现极致性价比。
目前,基于GPNPU架构的芯片正加速落地。正在研发的Nova 500系列,作为第五代GPNPU芯片,重点提升带宽与能效,是实现“1元内搞定百万Token”目标的关键一步。展望未来,Nova 600系列将探索光电一体化互联,构建高性价比的算力网络,进一步将推理成本推向分级成本新低。
依托GPNPU,云天励飞已构建“深穹”(云端)、“深界”(边缘)、“深擎”(具身智能)三大芯片产品矩阵,全面服务于互联网大厂、智能终端厂商与机器人企业,推动AI应用的广泛落地。
在国产工艺受限、高端GPU供应不确定的现实下,云天励飞没有选择在制程工艺上硬拼,而是以架构创新另辟蹊径。GPNPU不仅是技术的突破,更是一种战略智慧的体现——通过“算力积木+3D堆叠”的创新路径,走出一条高能效、低成本、全场景的差异化发展之路。它预示着,AI算力将不再昂贵稀缺,而是如水电般普惠,真正赋能千行百业的智能化变革。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI
+关注
关注
91文章
41164浏览量
302624
发布评论请先 登录
相关推荐
热点推荐
端侧AI“堆叠DRAM”技术,这些国内厂商发力!
正3D DRAM等定制化存储方案正是基于利基存储和先进封装,以近存计算的方式满足AI推理的存储需求。SoC厂商、下游终端厂商都在积极适配这一类新型存储。 华邦电子CUBE 华邦

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
310P芯片的底层架构,深度剖析这款产品的技术细节、算力门槛及其在实际产业落地中的真实价值。
一、176TOPS的产业门槛:为何这是边缘算力
发表于 03-10 14:19
百亿Token一分钱!云天励飞喊出“推理成本万倍降”,公布三年三芯路线图
励飞再次阐述了GPNPU架构的技术内涵,并公开了未来三年大算力芯片路线图,致力于成为“最懂AI的推理

力争百万 Tokens 推理成本降低百倍:云天励飞发布未来三年大算力芯片战略,首曝 DeepVerse 路线图
集中于攻克大模型落地的“成本壁垒”,致力于通过底层架构创新,力争实现百万 Tokens 推理成本降低 100 倍以上的目标,推动 AI 从技术尝鲜走向普惠生产

从3D堆叠到二维材料:2026年芯片技术全面突破物理极限
2026年半导体行业跨越物理极限:3D堆叠芯片性能提升300%,二维材料量产为1纳米工艺铺路。探讨芯片技术在算力、能耗与全球化合作中的关键进展。
简单认识3D SOI集成电路技术
在半导体技术迈向“后摩尔时代”的进程中,3D集成电路(3D IC)凭借垂直堆叠架构突破平面缩放限制,成为提升性能与功能密度的核心路径。
应对端侧AI算力、内存、功耗“三堵墙”困境,安谋科技Arm China “周易”X3给出技术锦囊
NPU IP,通过架构创新、软硬件协同优化与开放生态等,为应对端侧AI“算力墙”、“内存墙”、

硅芯科技:AI算力突破,新型堆叠EDA工具持续进化
电子发烧友网报道(文/黄晶晶)先进封装是突破算力危机的核心路径。2.5D/3D Chiplet异构集成可破解内存墙、功耗墙与面积墙,但面临多物理场分析、测试容错等EDA设计挑战。现有E
国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?
反而压到了310W。更有意思的是它的异构架构:NPU+CPU+DVPP的组合,居然能同时扛住训练和推理场景,之前做自动驾驶算法时,用它跑模型时延直接降了20%。
但疑惑也有:这种算力密
发表于 10-27 13:12
什么是AI算力模组?
未来,腾视科技将继续深耕AI算力模组领域,全力推动AI边缘计算行业的深度发展。随着AI技术的不断演进和物联网应用的持续拓展,腾视科技的

什么是AI算力模组?
未来,腾视科技将继续深耕AI算力模组领域,全力推动AI边缘计算行业的深度发展。随着AI技术的不断演进和物联网应用的持续拓展,腾视科技的

睿海光电领航AI光模块:超快交付与全场景兼容赋能智算时代——以创新实力助力全球客户构建高效算力底座
光模块功耗和光纤部署复杂度,同时结合优化的前向纠错(FCE)技术,确保误码率低于10⁻¹²,灵敏度稳定在-5dBm以内,充分满足AI算力集群对长距离、低时延的严苛需求。
二、交付周期领
发表于 08-13 19:03
积算科技上线赤兔推理引擎服务,创新解锁FP8大模型算力
北京2025年7月30日 /美通社/ -- 近日,北京积算科技有限公司(以下简称"积算科技")宣布其算力服务平台上线赤兔推理引擎。积
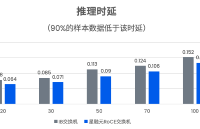
算力革命:RoCE实测推理时延比InfiniBand低30%的底层逻辑
AI 训练与推理中的网络效率瓶颈,助力数据中心在高带宽、低延迟、高可靠性的需求下实现算力资源的最优配置。



评论