 畅享DeepSeek自由,忆联高性能CSSD为端侧大模型加速
畅享DeepSeek自由,忆联高性能CSSD为端侧大模型加速

深圳2025年3月13日/美通社/ -- 当下,开源大模型DeepSeek凭借其强大的语言理解和生成能力,已成为全民追捧的AI工具。无论是文案创作还是代码编写,只需"DeepSeek一下"即可轻松解决。然而,随着用户访问量的激增,服务器无响应、等待时间长等问题也屡见不鲜。一时间,能够离线运行,且更具隐私性的DeepSeek端侧部署也成为新风向。
本地部署虽具备诸多优点,但对电脑的硬件配置却有一定的要求。大模型包含大量参数,即使是蒸馏过的小模型,模型大小也动辄几十GB甚至上百GB。电脑除了需要CPU、GPU能够高效运行之外,一款高性能的SSD也必不可少。忆联AM541搭载新一代Jaguar6020主控,内置高容量SRAM及IO加速模块,顺序读取速度高达7000 MB/s,能够轻松应对DeepSeek大模型加载等高负载场景,为用户提供流畅的使用体验,让用户真正实现"DeepSeek自由"。
适配度100%,大模型首次加载丝滑流畅
在DeepSeek本地加载运行过程中,SSD是整个数据流的第一棒。当DeepSeek完成本地部署后,模型文件即保存在SSD中。当用户加载模型时,会先将大模型文件从SSD读取到系统内存中,再由内存中转传输到显存,由GPU进行推理运算。因此,SSD的性能越好,就能越快将数据传输到GPU进行计算,体现在实际应用中就是大模型的加载时间越短。
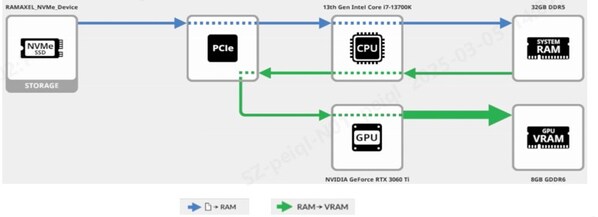
加载大模型时数据流方式
为了验证忆联AM541的性能及场景适配度,我们通过Ollama模型框架在本地部署了Deepseek-R1 8B模型,采用忆联AM541 1TB SSD及国内友商1TB A产品搭配GeForce RTX 3060 Ti 显卡,在同等环境下进行了模型加载测试。
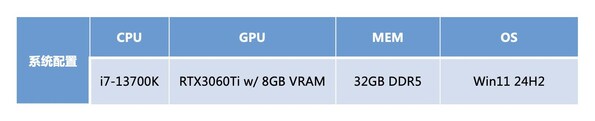
系统配置
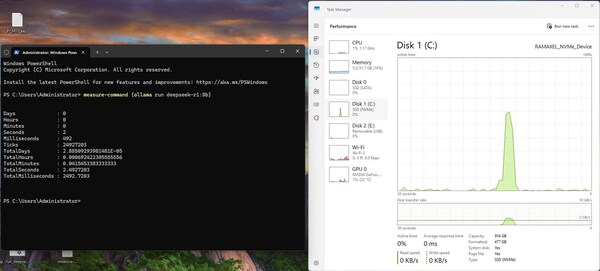
大模型加载时SSD状态(见右侧图)
测试结果显示,搭载AM541的PC在加载大模型时表现出色,首次加载时间(最快)仅为2.486秒,领先国内一线SSD厂商同类产品约9%。这一成绩充分体现了AM541对DeepSeek等高负载应用100%适配,能够为用户带来更加流畅的使用体验。
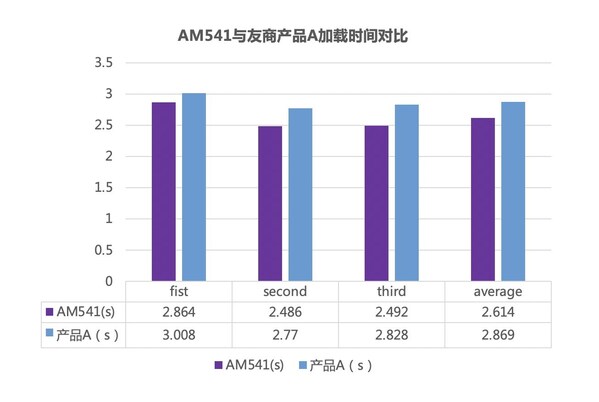
顺序读突破7GB/s,硬核性能助力用户畅享"DeepSeek自由"
更短加载时间背后,反映的是SSD更高的性能及更加灵活的场景适应性。得益于SoC内置的加速模块,AM541的标称顺序读写速度达到了7000 MB/s、5600 MB/s ,4KB随机读写速度可达800K IOPS、800K IOPS。从DeepSeek加载时的pattern解析来看,AM541性能波峰接近7GB/s,这与其标称的性能高度吻合。
AM541缘何更快?测试人员进一步对加载过程进行了trace解析,发现模型加载过程主要以大size命令的低QD顺序读为主,而AM541自带的Big SRAM策略及延迟控制机制在处理此类命令时优势明显,使得大模型加载时间大幅领先友商。
此外,经测试发现,当大模型在搭载AM541的电脑上完成首次加载后,模型文件即被DRAM缓存,因此当设备Idle后再次加载时,模型文件可以直接从DRAM传输到VRAM,加载时间比首次更快,真正将DeepSeek变为用户的"私人工具",随时畅享"DeepSeek自由"。
拥抱大模型,忆联为AI生态持续助力
随着AI本地化趋势的加速,DeepSeek一体机等终端设备也逐渐普及。在消费电子领域,已有主流 PC厂商将DeepSeek大模型嵌入AIPC中,多款手机也开始发力AI大模型。未来,个人电脑、手机等终端设备极有可能会搭载多种大模型,甚至各种行业应用也会接入大模型。面对不同参数规模的AI模型,以及不同模型频繁切换带来的高频读写过程,SSD不仅要有足够大的容量,同时对SSD的全面性能及稳定性都是一种考验。
依托硬件加速及先进的软件算法,AM541不仅在低QD Latency上具备优势,在多种混合读写中均有出色表现,可轻松应对多应用场景。
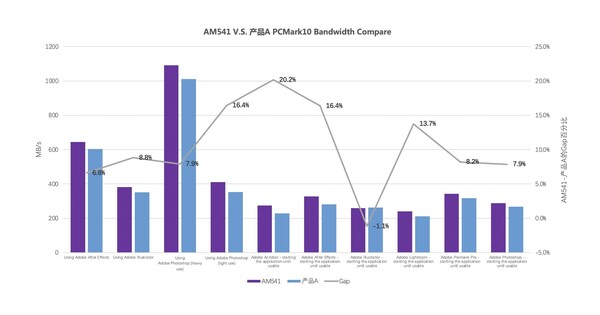
在PCMark10测试中,AM541跑分超过了3700,比友商同类产品A高出约300分,在办公、游戏、内容创作等多个场景中性能领先,其中,在常见的数字内容创作中,AM541平均比友商同类产品快10.5%。
AI浪潮奔涌不停,技术创新日新月异,作为底层硬件支撑,SSD在AI本地化进程中扮演着关键角色。忆联AM541凭借其硬核性能,不仅为DeepSeek大模型的本地化部署提供了高效解决方案,也为用户带来了前所未有的使用体验。未来,忆联将紧跟行业趋势,聚焦端侧大模型的技术痛点,推进技术创新与产品迭代,为AI生态的繁荣发展提供持续动能。
审核编辑 黄宇
-
CSSD
+关注
关注
0文章
11浏览量
6756 -
大模型
+关注
关注
2文章
3765浏览量
5269 -
DeepSeek
+关注
关注
2文章
838浏览量
3396
发布评论请先 登录
忆联AM6D1以DRAMLess架构重塑性能与成本平衡

英特尔与忆联重磅推出企业级网络存储解决方案

借助谷歌LiteRT构建下一代高性能端侧AI

引领端侧大模型落地!Firefly-RK182X 开发套件上线发售

英特尔Gaudi 2E AI加速器为DeepSeek-V3.1提供加速支持

华为CANN与智谱GLM端侧模型完成适配
端侧大模型迎来“轻”革命!移远通信 × RWKV 打造“轻量AI大脑”

终于有人把端侧大模型说清楚了

【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
英特尔Benchmark验证!忆联UH812a问鼎PCIe Gen5企业级存储性能巅峰




评论