 专访AMD GPU教父王启尚:卓越的RDNA 4架构,造就新一代性价比王者显卡
专访AMD GPU教父王启尚:卓越的RDNA 4架构,造就新一代性价比王者显卡


在今年CES大会上首次公布定位4K游戏的Radeon RX 9070系列显卡之后,AMD于2月28日再次举办发布会并宣布了Radeon RX 9070系列的技术细节与售价,其中Radeon RX 9070首发售价4499元起,Radeon RX 9070 XT首发售价4999元起,可以说是用2K显卡的价格让玩家买到了4K显卡,在同级产品中性价比优势无可匹敌。我们在发布会现场有幸采访到AMD GPU技术与工程研发高级副总裁王启尚先生,那么大家就一起来听听这位GPU教父级的大佬对RDNA 4的解读吧!
01
全面升级的RDNA 4架构带来更高性能与能效表现

▲RDNA 4架构的全面升级为玩家带来了发烧级的游戏体验
RDNA架构从诞生至今已经发展到了第四代,每一代都为玩家带来了出色的显卡产品,并提供了发烧级的游戏体验。而RDNA 4更是在新的架构设计和4nm制程的支持下带来更加出色的性能与能效表现。概括来看,就是大幅提升了光栅化性能与计算效率、大幅升级光追性能与AI性能、增强了显存带宽利用率并提供了更出色的视频画质。
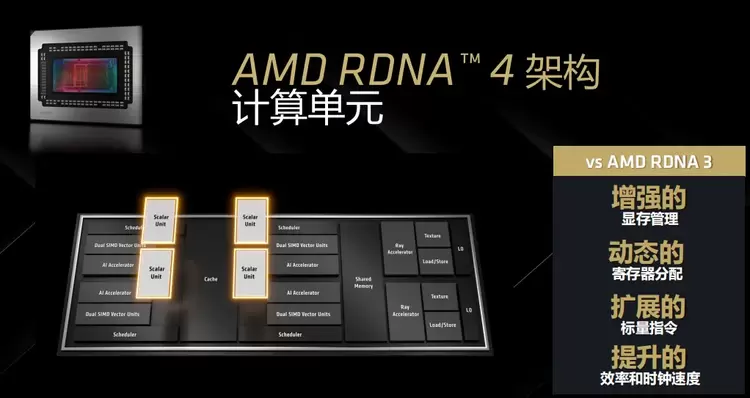
▲RDNA 4架构全新设计了CU单元
王启尚先生介绍道,RDNA 4架构采用了全新设计的CU单元,增强了显存系统,大幅提升了显存带宽的利用率,在同样的显存带宽下也能提供更强的游戏性能和AI性能;改进了标量单元的效率,支持动态寄存器分配,从而最终大幅提升了CU单元的执行效率和能效表现,同时也做到了更高的工作频率。综合来看,RDNA 4的CU单元性能相对于RDNA 3提升了大约40%。
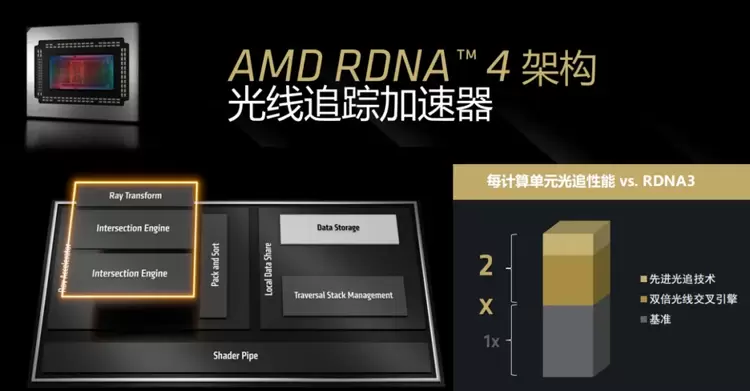
▲RDNA 4架构配备第三代光线加速器
此外,RDNA 4架构配备了第三代光线加速器,它将Ray Intersection Engine(光线交叉引擎)提升到了两个,拥有新的光线变换引擎和新的定向包围盒,为RDNA 4的新CU带来了相对于上代两倍的光追性能。因此,RX 9070系列相对上代来讲会拥有强得多的光追游戏性能。

▲RDNA 4架构配备第二代AI加速器
RDNA 4架构的AI加速器也升级到了第二代,其中FP16性能是上代的两倍,INT8性能是上代的四倍,FP16稀疏性能是上代的四倍,INT8稀疏性能是上代的八倍,并且还新增了对FP8精度格式的原生支持。如此一来,RDNA 4不管是在AI应用还是在未来的AI渲染计算中,相对上代RDNA 3都有巨大的性能提升。此外,RDNA 4首发的RX 9070系列两款显卡都配备了16GB/256bit大显存,这对于吃显存的AI应用来说也非常有利。

在提到RX 9070系列大显存在AI方面的优势时,王启尚先生介绍道:“影响显卡AI运算性能的核心重点就是显存和带宽,这也是我们RDNA 4架构的优势所在。首先,我们通过技术手段让RDNA 4的GPU实现了最高8倍于RDNA 3的AI性能;其次,在显存带宽不变的情况下,我们通过技术手段将其利用率提升,从而可以实现显卡AI性能的直接提升。”
此外,大家可能注意到与竞品最新产品主推FP4精度不一样的是,RDNA 4主打的是FP8精度计算,那么AMD为什么会选择FP8呢?王启尚先生给出了答案:“大家都看到了我们FSR 4对游戏帧率的显著提升效果,它能够使很多3A游戏的帧率提升达3倍以上,并提供近乎于原生画质的效果。我们的FSR 4所采用的就是RDNA 4架构的8bit浮点运算格式(FP8),我们认为,FP8能够提供优于FP4的输出质量,并且可以将性能与画质达到尽可能的平衡,这就是我们采用FP8格式的重要原因。”
02
FSR 4专属黑科技加持,RDNA 4如虎添翼
本次RDNA 4显卡还搭载了一项专属黑科技:FSR 4。王启尚先生在会上详细介绍了FSR 4的技术细节,FSR 4专为RDNA 4开发,是基于机器学习模型的技术(因此暂时是RDNA 4专属),它可以带来比FSR 3.1(基于分析模型)更好的图像画质、更低的帧延迟(基于机器学习的超分辨率+帧生成+Anti-Lag 2),并且带来了神经渲染功能。
此外,原本支持FSR 3.1的游戏可以非常方便地升级到支持FSR 4,这就意味着支持FSR 4的游戏会迅速地多起来。实际上,目前已经有超过35个游戏宣布首发支持FSR 4,今年内估计有超过75个游戏大作会支持FSR 4。对于RX 9070系列显卡来说,有了FSR 4的支持,更是可以在4K游戏中轻松实现百帧以上的流畅度

▲FSR 4完全在AMD平台上进行开发训练与优化
那么,基于机器学习模型的FSR 4在进行AI渲染的时候是否会出现画面细节上的差异呢?针对这一点王启尚先生进行了回答:“正如在发布会上所分享的,我们的FSR 4技术是基于机器学习模型所打造的,且是使用不同种类的机器学习模型组合而成,通过反复训练来形成最佳方案。我们可以对画面细节做到尽可能好地保留,至于是否会出现细节差异,就需要看看广大的发烧友们测试的结果了。不过我们内部测试时对于FSR 4的画质渲染效果和对游戏性能的提升效果是非常满意的。”
除了FSR 4之外,新版的Radeon Software也带来了更多的功能,其中也包含了AI方面的应用。王启尚先生介绍到:“我们一直希望Radeon Software可以带给用户更加高质量的,便捷的使用体验。例如Adrenalin AI就集成在了AMD Software Adrenaline Edition驱动程序中。这样做的目的是为了给用户提供更加便捷的使用体验,让入门级的用户更容易上手操作。它除了可以实现从文本到图像的生成,还提供了聊天机器人的功能,方便用户更加高效地查询资料,或者了解如何对Radeon Software进行设置,这对于提升软件的易用性是很有帮助的。”
03
写在最后:作为4K游戏显卡,RX 9070系列性价比无可匹敌

在采访最后,王启尚先生总结到:“RDNA 4架构无论在绘图性能,还是光栅游戏、光追游戏、机器学习等方面都相对上一代有大幅的提升,同时AMD在功耗方面也做了很多优化工作,让它拥有更高的能效表现。至于RX 9070系列产品的定位,AMD希望让更多玩家以更低的价格享受到发烧级游戏显卡。因此,大家也看到了RX 9070系列拥有非常令人兴奋的价格。所以,不管是从性价比还是游戏性能与AI性能来讲,它都是一个非常好的选择。”
从DIY玩家的角度来说,AMD本次给RX 9070系列的定价确实非常有诚意,大家只需要花买2K显卡的钱,就可以享受到4K游戏的体验,同时还能获得FSR 4这样RDNA 4独享的帧率提升黑科技,相比同级产品夸张的价格来讲算得上是性价比完胜。而从市场角度来讲,RDNA 4的出现无疑是要将游戏显卡价格重新推向正常化,给“店大欺客”的天价显卡一招王炸。这次,可能大家都要真心说一句“AMD YES”了。
-
amd
+关注
关注
25文章
5729浏览量
140741 -
gpu
+关注
关注
28文章
5344浏览量
136321 -
显卡
+关注
关注
17文章
2526浏览量
71851
发布评论请先 登录
内存要取代GPU?HBM之父警告:以英伟达GPU为核心的架构要被颠覆

新一代eZ80:为互联网产品带来革新
告别高成本!新一代极简光端机,性能对标,价格直降近50%
广汽新一代智能座舱架构与电子电气架构即将发布
Infineon XC2734X微控制器:16/32位架构的强劲之选
曦望发布新一代推理GPU芯片,单位Token推理成本降低90%
今日看点:消息称 AMD、高通考虑导入 SOCAMM 内存;曦望发布新一代推理GPU芯片启望S3
摩尔线程新一代GPU架构即将揭晓
基于蜂鸟E203架构的指令集K扩展
迅为Hi3403V610开发板海思Cortex-A55架构核心板卡




评论