 Arm技术助力Google Axion处理器加速AI工作负载推理
Arm技术助力Google Axion处理器加速AI工作负载推理

作者:Arm 基础设施事业部高级产品经理 Ashok Bhat
由 Arm Neoverse V2 平台赋能的 Google Axion 处理器已在 Google Cloud 上正式上线,其中,C4A 是首款基于 Axion 的云虚拟机,为基于 CPU 的人工智能 (AI) 推理和通用云工作负载实现了显著的性能飞跃。
Axion CPU 延续了 Google Cloud 的定制芯片计划,旨在提高工作负载性能和能效,标志着在重塑 AI 云计算格局方向上的重大进步。Google 选择 Arm Neoverse 平台是因为它具备高性能、高能效和创新灵活性,而且有着强大的软件生态系统和广泛的行业应用,可确保与现有应用的轻松集成。
Neoverse V2 平台引入了新的硬件扩展,例如 SVE/SVE2、BF16 和 i8mm,与上代 Neoverse N1 相比,显著增强了机器学习性能。这些扩展增强了向量处理、BFloat16 运算和整数矩阵乘法,使得基于 Neoverse V2 的 CPU 每周期执行的 MAC 运算次数比 N1 提高最多四倍。
从生成式 AI 到计算机视觉:加快 AI 工作负载推理速度并提升性能
立足于开源为原则的 AI 具备众多领先的开源项目。近年来,Arm 一直与合作伙伴开展密切合作,以提高这些开源项目的性能。在许多情况下,我们会利用 Arm Kleidi 技术来提高 Neoverse 平台上的性能,Kleidi 技术可通过 Arm Compute Library 和 KleidiAI 库访问。
大语言模型
由 Meta 开发的 Llama 模型包含一系列先进的大语言模型 (LLM),专为各种生成任务而设计,模型大小从 10 亿到 4,050 亿个参数不等。这些模型针对性能进行了优化,并可针对特定应用进行微调,因而在自然语言处理任务中用途广泛。
Llama.cpp 是一个 C++ 实现方案,可以在不同的硬件平台上实现这些模型的高效推理。它支持 Q4_0 量化方案,可将模型权重减少为 4 位整数。
为了展示基于 Arm 架构的服务器 CPU 在 LLM 推理方面的能力,Arm 软件团队和 Arm 合作伙伴对 llama.cpp 中的 int4 内核进行了优化,以利用这些新的指令。具体来说,我们增加了三种新的量化格式:为仅支持 Neon 的设备添加了 Q4_0_4_4,为支持 SVE/SVE2 和 i8mm 的设备添加了 Q4_0_4_8,为支持 SVE 256 位的设备添加了 Q4_0_8_8。
因此,与当前的 x86 架构实例相比,基于 Axion 的虚拟机在提示词处理和词元 (token) 生成方面的性能高出两倍。
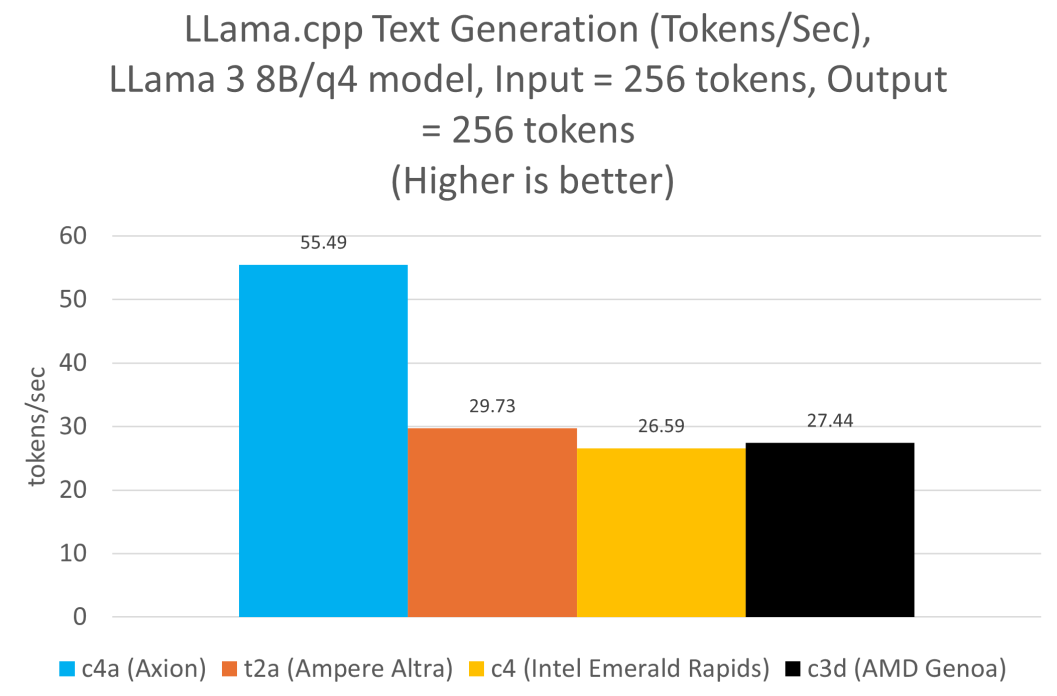
我们在所有实例上运行了 Llama 3.1 8B 模型,并对每个实例使用了推荐的 4 位量化方案。Axion 的数据是在 c4a-standard-48 实例上使用 Q4_0_4_8 量化方案生成的,而 Ampere Altra 的数据是在 t2a-standard-48 实例上使用 Q4_0_4_4 生成的。x86 架构的数据是在 c4-standard-48 (Intel Emerald Rapids) 和 c3d-standard-60 (AMD Genoa) 上使用 Q4_0 量化格式生成的。在所有实例中,线程数始终设置为 48。
BERT
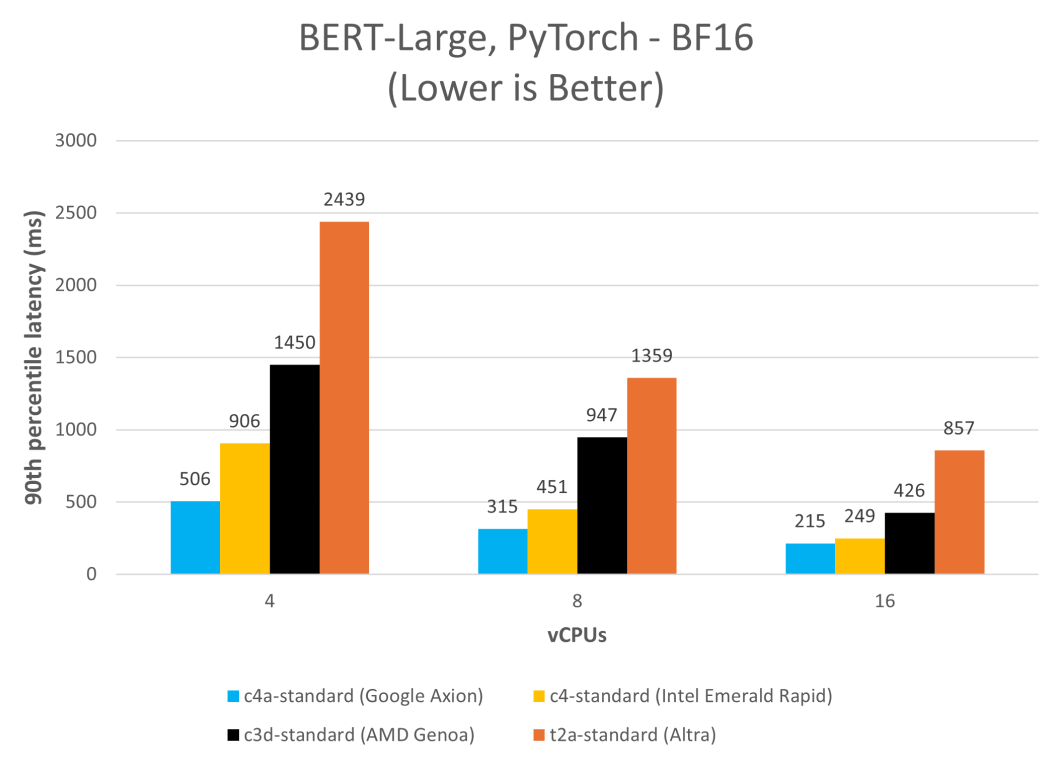
在 C4A 虚拟机上运行 BERT 取得了显著的速度提升,大幅减少了延迟并提高了吞吐量。此例中,我们在各种 Google Cloud 平台实例上以单流模式(批量大小为 1)使用 PyTorch 2.2.1 运行 MLPerf BERT 模型,并测量第 90 百分位的延迟。
ResNet-50
此外,Google Axion 的功能不仅限于 LLM,还可应用于图像识别模型,例如 ResNet-50 就能受益于此硬件的先进特性。BF16 和 i8mm 指令集成后,实现了更高的精度和更快的训练速度,展现了 Axion 相较基于 x86 架构实例的性能优势。
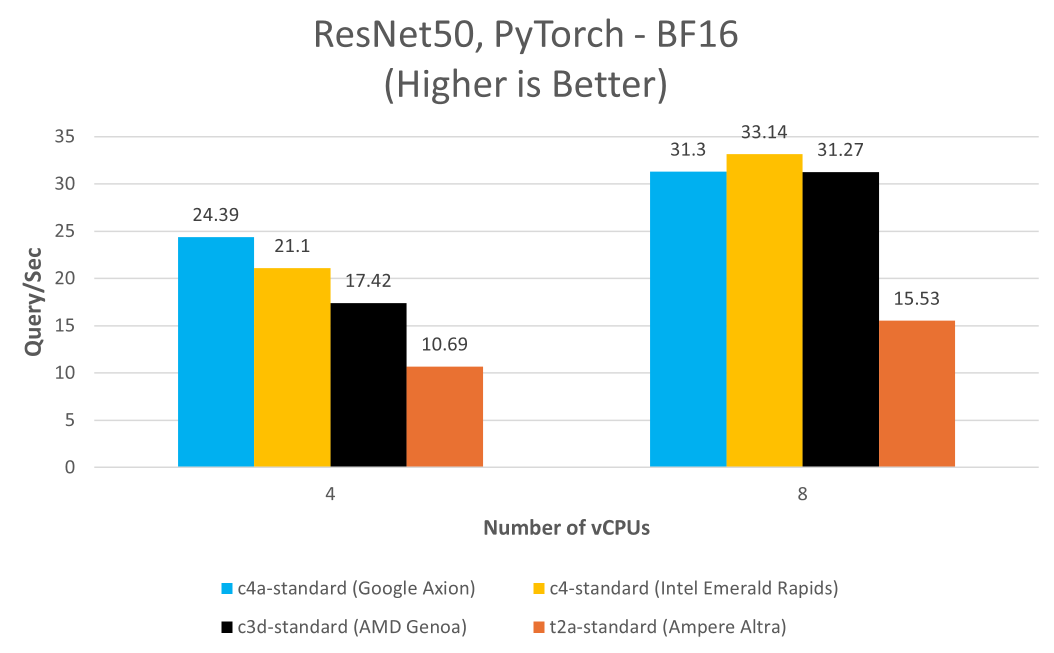
此例中,我们在各种 Google Cloud 平台实例上以单流模式(批量大小为 1)使用 PyTorch 2.2.1 运行 MLPerf ResNet-50 PyTorch 模型。
XGBoost
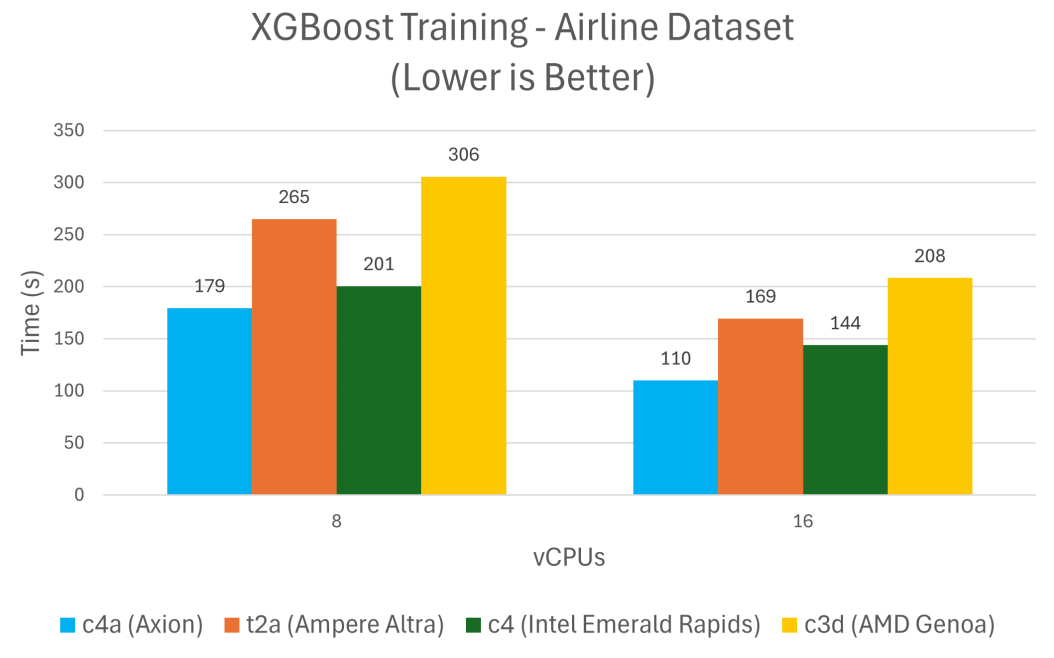
XGBoost 是一个领先的机器学习算法库,用于解决回归、分类和排序问题,与 Google Cloud 上类似的 x86 架构实例相比,在 Axion 上训练和预测所需的时间减少了 24% 到 48%。
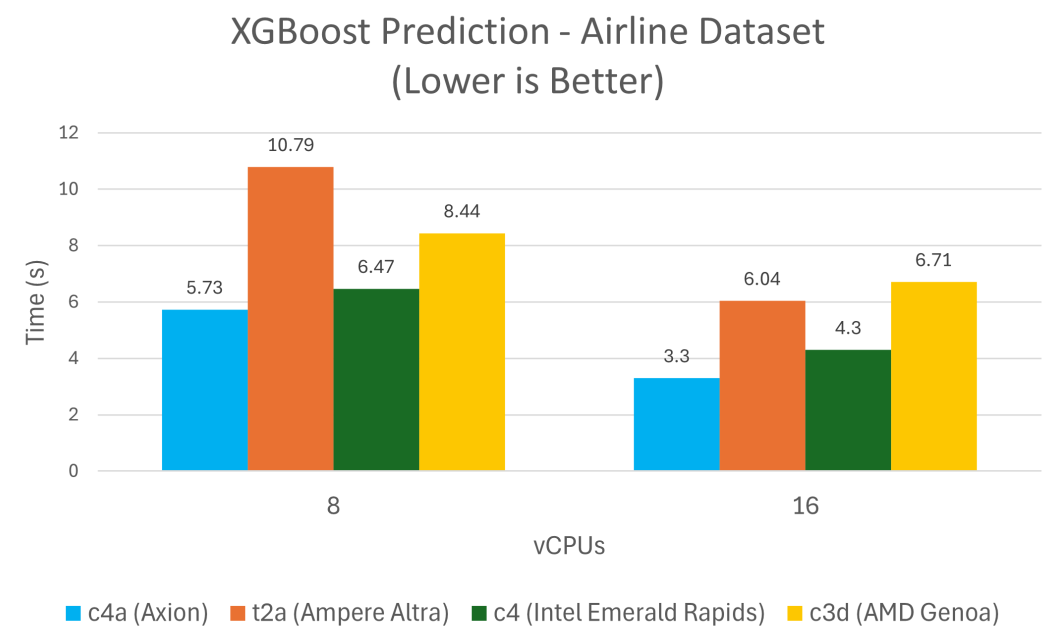
结论
从上述结果,可以发现基于 Axion 的虚拟机在性能方面超越了上一代基于 Neoverse N1 的虚拟机和 Google Cloud 上其他的 x86 架构替代方案。Google Cloud C4A 虚拟机能够处理从 XGBoost 等传统机器学习任务到 Llama 等生成式 AI 应用的各类工作负载,是AI 推理的理想之选。
Arm 资源:助力云迁移
为了提升 Google Axion 的使用体验,Arm 汇集了各种资源:
[1] 通过 Arm Learning Paths 迁移到 Axion:依照详细的指南和最佳实践,简化向 Axion 实例的迁移。
[2] Arm Software Ecosystem Dashboard:获取有关 Arm 的最新软件支持信息。
[3] Arm 开发者中心:无论是刚接触 Arm 平台,还是正在寻找开发高性能软件解决方案的资源,Arm 开发者中心应有尽有,可以帮助开发者构建更卓越的软件,为数十亿设备提供丰富的体验。欢迎开发者在 Arm 不断壮大的全球开发者社区中,下载内容、交流学习和讨论。
-
ARM
+关注
关注
135文章
9631浏览量
395126 -
计算机
+关注
关注
19文章
7863浏览量
93730 -
AI
+关注
关注
91文章
42599浏览量
303517 -
Neoverse
+关注
关注
0文章
17浏览量
5012
原文标题:基于 Arm Neoverse 的 Google Axion 以更高性能加速 AI 工作负载推理
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Synaptics基于Arm架构打造AI原生计算SoC
西门子硬件辅助验证解决方案助力Arm打造可扩展AI基础设施
直播预告|玄铁 x Canonical:从本地推理到 AI 工厂,基于 RISC-V 的 AI 基础设施创新路径探讨
Arm携手Google Cloud推进代理式AI基础设施规模化落地

Cadence 与 Google 合作,利用 ChipStack AI Super Agent 在 Google Cloud 上扩展 AI 驱动的芯片设计
使用NORDIC AI的好处
瑞芯微SOC智能视觉AI处理器
d-Matrix与Andes晶心科技合作打造下一代AI推理加速器
瑞萨电子RZ/V系列微处理器助力边缘AI开发

今日看点丨华为发布AI推理创新技术UCM;比亚迪汽车出口暴增130%
Arm KleidiAI与XNNPack集成实现AI性能提升




评论