 美格智能AIMO智能体+DeepSeek-R1模型,AI应用的iPhone时刻来了
美格智能AIMO智能体+DeepSeek-R1模型,AI应用的iPhone时刻来了

导语:
当AI大模型从云端下沉至终端设备,一场关于效率、隐私与智能化的革命悄然展开。作为全球领先的无线通信模组及解决方案提供商,美格智能凭借其高算力AI模组矩阵与端侧大模型部署经验,结合最新发布的AIMO智能体产品,正加速开发DeepSeek-R1模型在端侧落地应用及端云结合整体方案,助力国产优质模型渗透千行百业,共塑智能化未来。
AIMO智能体硬件加速迭代,AI硬件与大模型协同优化
美格智能基于高通骁龙高性能计算平台打造的AIMO智能体产品,集成48Tops AI算力,支持混合精度计算(INT4/FP8)与异构计算架构(8核CPU+Adreno GPU+Hexagon NPU),可高效承载7B参数级大模型的端侧推理需求。其板载16GB LPDDR5X内存与256GB UFS 4.0存储,为模型动态加载与实时数据处理提供硬件保障。2025年美格智能将推出单颗模组算力达到100Tops的高阶AI硬件,远期规划AI模组算力超过200Tops。

美格智能已成功在高算力AI模组上部署LLaMA-2、通义千问Qwen、ChatGLM2等大模型,验证了从模型压缩(量化、剪枝)到框架适配(ONNX/TFLite)的全流程能力。美格智能自研的MEIG AI算法部署平台、AIMO智能体、模型优化器等,可大幅缩短模型落地周期,支持开发者通过Python快速完成应用开发,并支持开发者进行模型训练。
AIMO智能体内置的高算力AI模组的异构计算架构,具备协同加速能力,支持模型并行计算与低功耗运行,LPDDR5X内存提供超过60GB/s带宽,满足7B模型推理时的高吞吐需求。内置专用AI加速引擎支持INT4/FP16混合精度计算,与DeepSeek-R1模型的量化格式(INT4/FP8)高度适配。
DeepSeek-R1低调亮相,蒸馏小模型超越OpenAI o1-mini
DeepSeek-R1采用强化学习逻辑,驱动通过多阶段RL训练(基础模型→RL→微调迭代),DeepSeek-R1在数学、代码、逻辑推理任务中表现比肩国际顶尖模型,如AIME数学竞赛准确率达71%。DeepSeek-R1提供轻量化适配:DeepSeek-R1系列提供1.5B至70B参数蒸馏版本,其中7B模型经INT4量化后仅需2-4GB存储,完美适配终端设备内存限制。DeepSeek-R1的动态思维链,支持数万字级内部推理过程,解决复杂问题时能自主拆解步骤并验证逻辑,输出可解释性更强的结果。
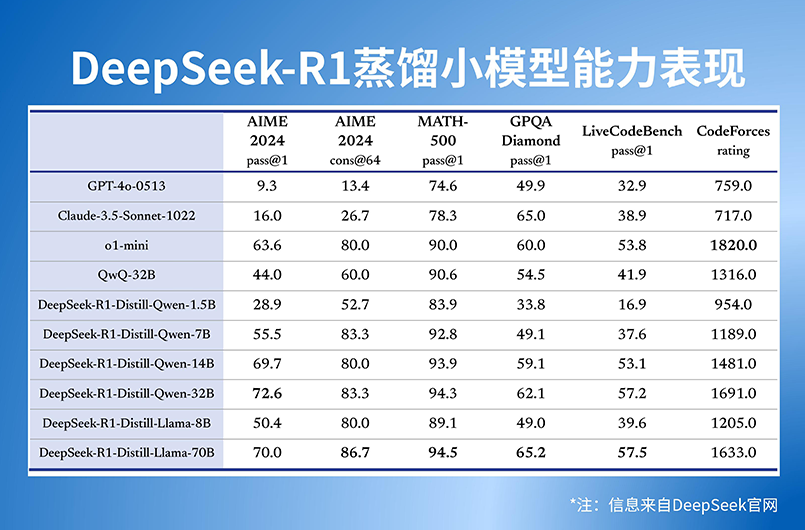
DeepSeek在开源DeepSeek-R1-Zero和DeepSeek-R1两个660B模型的同时,通过DeepSeek-R1的输出,蒸馏了6个小模型开源给社区,其中32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果。除32B和70B模型能力强悍外,DeepSeek-R1同步开源1.5B、7B、8B、14B等多个蒸馏小模型,极大扩展了终端侧模型部署的可选性,并支持用户进行“模型蒸馏”,明确允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。
以DeepSeek-R1 7B模型的端侧适配性举例,该模型具备轻量化设计特征,经蒸馏和量化后模型体积压缩至2-4GB,很好的匹配移动端存储限制。模型具备低延迟推理能力,在高算力模组平台上,可实现10-20 tokens/s的生成速度。模型支持分块推理和稀疏计算,结合美格智能高算力AI模组的能效优化,能实现极低的功耗控制。
算力与模型的技术迭代,AI应用的iPhone时刻即将带来
美格智能研发团队结合AIMO智能体、高算力AI模组的异构计算能力,结合多款模型量化、部署、功耗优化Know-how,正在加速开发DeepSeek-R1模型在端侧落地应用及端云结合整体方案。

▶超低功耗
首先持续对DeepSeek-R1模型的推理延迟进行优化,保证模型在高算力模组软硬件环境下的超低功耗运行。
▶开发工具链
不断进行工具链打通,模组内嵌的SNPE引擎直接支持DeepSeek-R1模型的ONNX/TFLite格式,大模型适配周期将大幅缩短。
▶端云协同
结合动态卸载技术,根据任务复杂度自动分配端侧与边缘计算资源,保障实时性与能效平衡。为客户提供端云协同模板,面向开发者提供动态任务分配框架,简单配置即可实现“本地优先,云端兜底”。
通过高阶AI硬件与DeepSeek-R1模型的能力结合,将突破端侧AI的能力边界。7B模型支持长文本理解、代码生成等传统端侧小模型无法完成的任务。多模态融合能力,高算力AI模组的ISP+AI能力结合DeepSeek-R1模型,可实现端侧图文问答、视频内容解析(如实时字幕生成)。个性化持续学习,通过AI模组的边缘计算能力,支持联邦学习框架下的本地模型微调(如用户习惯适配)。
在算力+模型的不断迭代背后,端侧AI及端云协同的商业模式和商业竞争力都将面临重构,DeepSeek-R1的发布,更是会极大刺激AI下游应用,如工业智能化、汽车Agent、机器人、个人大模型等应用场景的指数级增长,AI应用即将迎来属于自己的iPhone时刻。
▶基于DeepSeek-R1的AI Agent开发应用
结合美格智能自研的AIMO智能体及DeepSeek-R1模型的基础能力,开发面向工业智能化、座舱智能体、智能无人机、机器人等领域的AI Agent应用。
▶端侧AI能力包
推出面向AI场景的订阅服务,针对中小型的B端或C端客户,推出“端侧AI能力包”,与大模型厂商合作,针对Token输入/输出数量、不同类型模型调用、流量费用等领域,推出一体化端侧AI Turn-key方案。
▶智能化硬件增值
商业模式方面,各类高AI配置硬件叠加端侧模型加载或云端模型接入,为高算力硬件带来更多智能化增值。
▶自建GPU服务器与个性化专属大模型开发
美格研发团队持续拓展通用模型的部署通路,并不断向客户开放相关教程和源代码,并且以最新的高算力计算平台搭建GPU服务器,可用于端侧模型训练和支持客户开发专属大模型,结合DeepSeek-R1及其宽松、开放式的MIT授权协议,千行百业的个性化模型开发和应用即将爆发。
2025年,端侧AI、端云协同等各类AI应用的iPhone时刻将加速到来。DeepSeek-R1的出现,某种程度上改变了我们对于Scale的认知,但也不会带来云端算力的需求减少甚至崩塌,相反优质模型对于AI应用场景的极大刺激,也会推动云端算力需求的提升,端侧不断进化,云端负责兜底,端云结合终将是不变的方向。
美格智能也将持续以高算力AI模组、AI Agent应用、大模型部署服务、端侧AI服务整体解决方案为基石,携手大模型厂商、生态伙伴等不断推动类似DeepSeek-R1等优秀模型的应用拓展,让普惠、自主的高阶AI实现应有的社会价值。
-
AI
+关注
关注
91文章
41976浏览量
303077 -
智能体
+关注
关注
1文章
617浏览量
11656 -
美格智能
+关注
关注
2文章
332浏览量
12471 -
大模型
+关注
关注
2文章
3863浏览量
5297 -
DeepSeek
+关注
关注
2文章
861浏览量
3472
发布评论请先 登录
百度腾讯抢滩布局!DeepSeek-R1升级和开源背后,国产AI的逆袭之路
瑞芯微(EASY EAI)RV1126B AI模型部署

瑞芯微(EASY EAI)RV1126B AI模型转换

【2025夏季班正课】大模型Agent智能体开发实战 课分享
广和通成功部署DeepSeek-R1-0528-Qwen3-8B模型
DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

HarmonyOS AI辅助编程工具(CodeGenie)智能问答
速看!EASY-EAI教你离线部署Deepseek R1大模型

【「DeepSeek 核心技术揭秘」阅读体验】+混合专家
【「DeepSeek 核心技术揭秘」阅读体验】--全书概览
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
Arm Neoverse N2平台实现DeepSeek-R1满血版部署

NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录




评论