 Arm Neoverse N2平台实现DeepSeek-R1满血版部署
Arm Neoverse N2平台实现DeepSeek-R1满血版部署

今年年初,开源大语言模型 (LLM) DeepSeek 在国内外人工智能 (AI) LLM 领域掀起热议。它在模型架构和训练、推理方法上实现创新,在性能和工程效率上带来了显著提升,并在成本效率方面颇具优势。Arm 携手合作伙伴,在 Arm Neoverse N2 平台上使用开源推理框架 llama.cpp 实现 DeepSeek-R1 满血版的部署,目前已可提供线上服务。
在基于 Neoverse N2 平台设计的服务器级 CPU 上,通过对软硬件架构的合理适配,以及出色调优来充分发挥平台的计算能力和内存带宽,能够以 INT8 的量化版本提供业界可用的词元 (token) 生成速度,并以更具竞争力的性价比为中小微企业提供业界顶尖的 LLM 服务。
在部署 DeepSeek 大模型过程中,Arm 结合底层架构特性进行了深度优化:模型本身跨多 NUMA(非统一内存访问)节点以交错 (interleave) 方式加载,以便充分利用所有内存带宽;除 INT8 量化外,通过开启 KV 量化,以及激活 Flash Attention 机制,以此进一步降低计算量和压缩内存占用。通过技术团队的努力,DeepSeek 满血版的整体性能相较优化前提升了 67%。工程团队后续也会持续投入,提高多节点上的计算并发度及带宽利用率,并通过开发者社区不断完善 Arm 架构的软件生态。
细究 DeepSeek 的模型架构创新,它针对大模型运行时的痛点进行计算、内存访问和算法流水线上的效率提升,比如 MLA 和 FP8 训练和推理减少了内存占用和带宽需求,DeepSeekMoE 降低了计算强度、提高计算效率,DualPipe 提高了多计算节点间的通信和计算效率。这些工程优化思维与 Arm 一贯倡导的高能效设计目标不谋而合,也使得在纯 CPU 平台上运行如此大规模的模型成为可能。
Arm 平台致力于助力合作伙伴提高性能,并降低总体拥有成本 (TCO),在 Neoverse N2 平台运行 DeepSeek 大模型推理也淋漓尽致地体现了这一原则。在为中小微企业提供大模型服务时,并发需求降低,成本敏感度提高。在基于 Neoverse N2 平台上运行的 DeepSeek-R1 为他们提供了一个更为均衡的选择。相较传统多卡 GPU/加速器平台,这能极大地降低订阅服务成本,使用户能以较低代价快速启动业务部署。下图是两种方案订阅服务的价格对比:
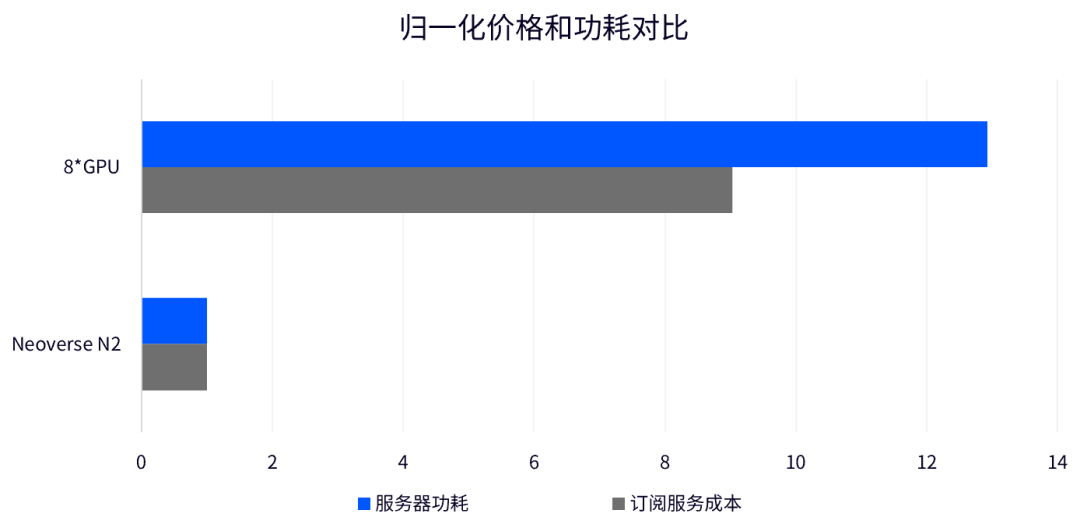
搭载 Neoverse N2 平台的服务器平台能把部署成本降低约八倍。此外,对数据中心来说,在 CPU 上部署 LLM 也能充分利用在线的空闲算力,提高整体资源利用率。与此同时,基于 Neoverse N2 平台的服务器功耗仅为传统八卡 GPU 服务器的 1/12,能极大地降低数据中心的能耗压力。
如此大规模的模型(6,710亿参数)能够在数据中心服务器级 CPU 上运行,并迅速上线为客户提供快速部署,得益于 Neoverse 平台对 AI 推理负载的一贯思考和设计,包括 2 x 128 位的可伸缩向量扩展 (SVE2) 特性、BF16/INT8 数据格式支持,以及点积和矩阵乘法等指令的支持,加之多通道高带宽内存配置,和低延迟 CMN 互联等等。
随着 AI 领域的飞速发展,LLM 在持续的工程创新和优化之下应用领域不断变广。Arm 将持续通过 Neoverse 平台为行业赋能,并在这一新的技术纪元中引领变革。
-
ARM
+关注
关注
135文章
9588浏览量
393693 -
人工智能
+关注
关注
1820文章
50337浏览量
266978 -
DeepSeek
+关注
关注
2文章
840浏览量
3406
原文标题:在 Arm Neoverse N2 平台上以更优成本、更低功耗,充分释放 DeepSeek-R1 满血版性能
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
百度腾讯抢滩布局!DeepSeek-R1升级和开源背后,国产AI的逆袭之路
如何在Arm Neoverse N2平台上提升llama.cpp扩展性能
广和通成功部署DeepSeek-R1-0528-Qwen3-8B模型
DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

速看!EASY-EAI教你离线部署Deepseek R1大模型

【「DeepSeek 核心技术揭秘」阅读体验】--全书概览
【VisionFive 2单板计算机试用体验】3、开源大语言模型部署
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录

【书籍评测活动NO.62】一本书读懂 DeepSeek 全家桶核心技术:DeepSeek 核心技术揭秘
DeepSeek开源新版R1 媲美OpenAI o3
使用瑞萨MPU芯片RZ/V2H部署DeepSeek-R1模型


AMD实现首个基于台积电N2制程的硅片里程碑




评论