 摩尔线程GPU原生FP8计算助力AI训练
摩尔线程GPU原生FP8计算助力AI训练

近日,摩尔线程正式开源MT-MegatronLM与MT-TransformerEngine两大AI框架。通过深度融合FP8混合训练策略和高性能算子库,这两大框架在国产全功能GPU上实现了高效的混合并行训练和推理,显著提升了训练效率与稳定性。摩尔线程是国内率先原生支持FP8计算精度的国产GPU企业,此次开源不仅为AI训练和推理提供了全新的国产化解决方案,更对推动国产GPU在AI大模型领域的应用具有重要意义。
▼MT-MegatronLM开源地址:
https://github.com/MooreThreads/MT-MegatronLM
▼MT-TransformerEngine开源地址:
https://github.com/MooreThreads/MT-TransformerEngine
框架介绍
MT-MegatronLM是面向全功能GPU的开源混合并行训练框架,支持dense模型、多模态模型及MoE(混合专家)模型的高效训练。该框架利用全功能GPU支持FP8混合精度策略、高性能算子库muDNN与集合通信库MCCL,可以显著提升国产全功能GPU集群的算力利用率。
MT-TransformerEngine主要用于Transformer模型的高效训练与推理优化,通过算子融合、并行加速策略等技术,充分释放摩尔线程全功能GPU高密度计算的潜力和memory bound算子的效率。
技术突破与优势
两大框架的技术突破集中体现在硬件适配与算法创新的深度协同:
▽混合并行训练:支持Dense、多模态及MoE模型的混合并行训练,可灵活应对不同模型架构的复杂运算场景;
▽FP8混合训练策略:结合摩尔线程GPU原生支持的FP8混合精度训练策略,能够有效提升训练效率;
▽高性能算子库:通过高性能算子库muDNN与通信库MCCL的深度集成,系统性优化了计算密集型任务与多卡协同的通信开销;同时结合摩尔线程开源Simumax库,可自动进行并行策略搜索,并针对不同模型和加速环境spec最大化并行训练性能;
▽异常训练处理:框架内置的rewind异常恢复机制,可自动回滚至最近稳定节点继续训练,大幅提升大规模训练的稳定性;
▽完整的兼容性:两个框架兼容GPU主流生态,既保障了现有生态的平滑迁移,也为开发者构建自有的AI技术栈提供了底层支撑。
▼摩尔线程Simumax开源地址:
https://github.com/MooreThreads/SimuMax
实际应用效果
在实际应用中,这两个框架的充分结合已经取得了显著的成果。这些成果不仅验证了框架的技术成熟度,也为国产GPU生态的规模化应用奠定了坚实基础。
▽高效训练:在全功能GPU集群上,Llama3 8B模型的训练任务,可以利用FP8在loss几乎无损的情况下MFU达到90%以上;(如下图所示)
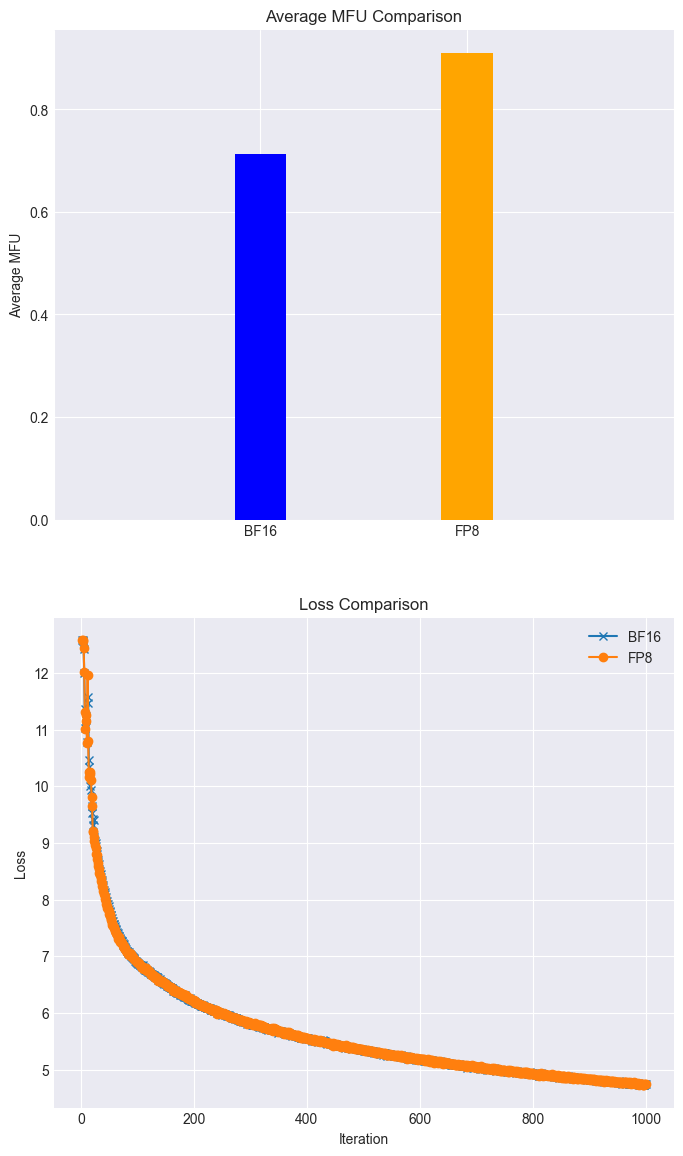
图注:利用摩尔线程FP8混合精度加速技术在loss无损的情况下得到28%的加速
▽复现DeepSeek 满血版训练:摩尔线程已深度集成并开源对DeepSeek并行算法DualPipe的高效支持,MT-DualPipe可以完整接入MT-Megatron框架和MT-TransformerEngine框架,成功实现DeepSeek V3训练流程的完整复现,支持MLA、MTP及多种专家平衡策略;
▽性能大幅优化:通过多种Transformer算子融合技术,显著提升了内存带宽利用率,有效缓解memory bound瓶颈,进一步释放国产GPU的硬件潜力。
持续优化与生态共建
为加速国产GPU生态发展与建设,摩尔线程将持续优化MT-MegatronLM与MT-TransformerEngine框架,并引入一系列创新功能:
▽Dual Pipe/ZeroBubble并行策略:进一步降低气泡率,提升并行训练效率;
▽多种FP8优化策略:独创的FP8优化策略,提高训练的性能和稳定性;
▽异步checkpoint策略:提高训练过程中的容错能力和效率;
▽优化后的重计算策略:减少计算和显存开销,提高训练速度;
▽容错训练策略:独创的容错训练算法,增强训练过程中的容错能力;
▽集成摩尔线程FlashMLA和DeepGemm库:进一步释放摩尔线程GPU的算力和FP8计算能力,提升计算性能和效率。
摩尔线程始终致力于推动开源生态的发展,通过技术开放与生态共建,加速国产全功能GPU在AI计算领域的规模化应用,为更多用户提供更智能、高效的解决方案。
▼ 关于摩尔线程
摩尔线程成立于2020年10月,以全功能GPU为核心,致力于向全球提供加速计算的基础设施和一站式解决方案,为各行各业的数智化转型提供强大的AI计算支持。
我们的目标是成为具备国际竞争力的GPU领军企业,为融合人工智能和数字孪生的数智世界打造先进的加速计算平台。我们的愿景是为美好世界加速。
-
gpu
+关注
关注
28文章
5346浏览量
136323 -
AI
+关注
关注
91文章
42408浏览量
303364 -
开源
+关注
关注
3文章
4441浏览量
46659 -
摩尔线程
+关注
关注
2文章
300浏览量
6701
原文标题:开源MT-MegatronLM和MT-TransformerEngine|摩尔线程GPU原生FP8计算助力AI训练
文章出处:【微信号:moorethreads,微信公众号:摩尔线程】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
燧原科技L600 FP8原生适配DeepSeek-V4-Pro/Flash模型
摩尔线程S5000 + 智源FlagOS:基于原生FP8引擎,Day-0适配DeepSeek-V4

摩尔线程MTT S5000率先完成对GLM-5的适配

Day-0支持|摩尔线程MTT S5000率先完成对GLM-5的适配

摩尔线程正式开源TileLang-MUSA项目
小马智行与摩尔线程达成战略合作
全栈国产AI Coding上线:摩尔线程+硅基流动+智谱,强强联合!

摩尔线程正式推出AI Coding Plan智能编程服务
摩尔线程公布全功能GPU架构路线图:以“花港”新架构与万卡训练集群,开启自主算力新时代

摩尔线程新一代GPU架构即将揭晓
摩尔线程吴庆详解 MUSA 软件栈:以技术创新释放 KUAE 集群潜能,引领 GPU 计算新高度

摩尔线程亮相WAIC 2025:以“AI工厂”理念驱动算力进化,全栈AI应用赋能千行百业

摩尔线程“AI工厂”:五大核心技术支撑,打造大模型训练超级工厂

摩尔线程“AI工厂”:以系统级创新定义新一代AI基础设施



评论