 【AI简报20231103期】ChatGPT参数揭秘,中文最强开源大模型来了!
【AI简报20231103期】ChatGPT参数揭秘,中文最强开源大模型来了!

1. 用FP8训练大模型有多香?微软:比BF16快64%,省42%内存
原文:https://mp.weixin.qq.com/s/xLvJXe2FDL8YdByZLHjGMQ
低精度训练是大模型训练中扩展模型大小,节约训练成本的最关键技术之一。相比于当前的 16 位和 32 位浮点混合精度训练,使用 FP8 8 位浮点混合精度训练能带来 2 倍的速度提升,节省 50% - 75% 的显存和 50% - 75% 的通信成本,而且英伟达最新一代卡皇 H100 自带良好的 FP8 硬件支持。但目前业界大模型训练框架对 FP8 训练的支持还非常有限。最近,微软提出了一种用于训练 LLM 的 FP8 混合精度框架 FP8-LM,将 FP8 尽可能应用在大模型训练的计算、存储和通信中,使用 H100 训练 GPT-175B 的速度比 BF16 快 64%,节省 42% 的内存占用。更重要的是:它开源了。
大型语言模型(LLM)具有前所未有的语言理解和生成能力,但是解锁这些高级的能力需要巨大的模型规模和训练计算量。在这种背景下,尤其是当我们关注扩展至 OpenAI 提出的超级智能 (Super Intelligence) 模型规模时,低精度训练是其中最有效且最关键的技术之一,其优势包括内存占用小、训练速度快,通信开销低。目前大多数训练框架(如 Megatron-LM、MetaSeq 和 Colossal-AI)训练 LLM 默认使用 FP32 全精度或者 FP16/BF16 混合精度。
但这仍然没有推至极限:随着英伟达 H100 GPU 的发布,FP8 正在成为下一代低精度表征的数据类型。理论上,相比于当前的 FP16/BF16 浮点混合精度训练,FP8 能带来 2 倍的速度提升,节省 50% - 75% 的内存成本和 50% - 75% 的通信成本。
尽管如此,目前对 FP8 训练的支持还很有限。英伟达的 Transformer Engine (TE),只将 FP8 用于 GEMM 计算,其所带来的端到端加速、内存和通信成本节省优势就非常有限了。
但现在微软开源的 FP8-LM FP8 混合精度框架极大地解决了这个问题:FP8-LM 框架经过高度优化,在训练前向和后向传递中全程使用 FP8 格式,极大降低了系统的计算,显存和通信开销。
论文地址:https://arxiv.org/abs/2310.18313
开源框架:https://github.com/Azure/MS-AMP
实验结果表明,在 H100 GPU 平台上训练 GPT-175B 模型时, FP8-LM 混合精度训练框架不仅减少了 42% 的实际内存占用,而且运行速度比广泛采用的 BF16 框架(即 Megatron-LM)快 64%,比 Nvidia Transformer Engine 快 17%。而且在预训练和多个下游任务上,使用 FP8-LM 训练框架可以得到目前标准的 BF16 混合精度框架相似结果的模型。
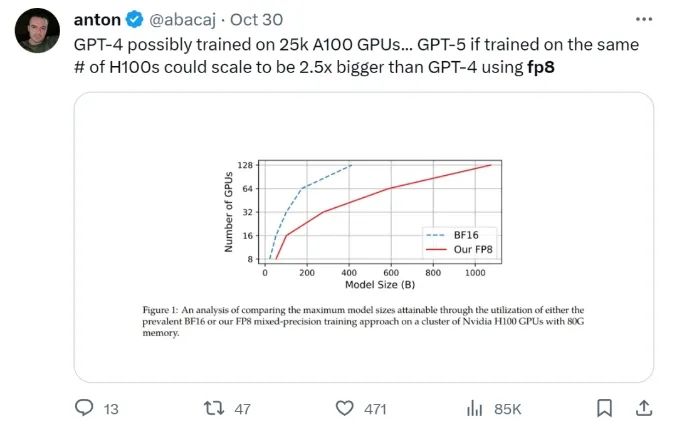
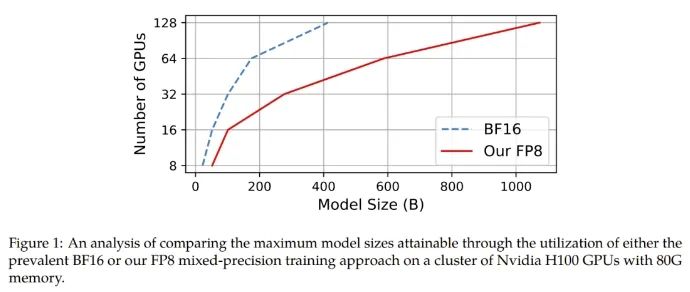
在给定计算资源情况下,使用 FP8-LM 框架能够无痛提升可训练的模型大小多达 2.5 倍。有研发人员在推特上热议:如果 GPT-5 使用 FP8 训练,即使只使用同样数量的 H100,模型大小也将会是 GPT-4 的 2.5 倍!
Huggingface 研发工程师调侃:「太酷啦,通过 FP8 大规模训练技术,可以实现计算欺骗!」
FP8-LM 主要贡献:
-
一个新的 FP8 混合精度训练框架。其能以一种附加方式逐渐解锁 8 位的权重、梯度、优化器和分布式训练,这很便于使用。这个 8 位框架可以简单直接地替代现有 16/32 位混合精度方法中相应部分,而无需对超参数和训练方式做任何修改。此外,微软的这个团队还发布了一个 PyTorch 实现,让用户可通过少量代码就实现 8 位低精度训练。
-
一个使用 FP8 训练的 GPT 式模型系列。他们使用了新提出的 FP8 方案来执行 GPT 预训练和微调(包括 SFT 和 RLHF),结果表明新方法在参数量从 70 亿到 1750 亿的各种大小的模型都颇具潜力。他们让常用的并行计算范式都有了 FP8 支持,包括张量、流水线和序列并行化,从而让用户可以使用 FP8 来训练大型基础模型。他们也以开源方式发布了首个基于 Megatron-LM 实现的 FP8 GPT 训练代码库。
FP8-LM 实现
具体来说,对于使用 FP8 来简化混合精度和分布式训练的目标,他们设计了三个优化层级。这三个层级能以一种渐进方式来逐渐整合 8 位的集体通信优化器和分布式并行训练。优化层级越高,就说明 LLM 训练中使用的 FP8 就越多。
此外,对于大规模训练(比如在数千台 GPU 上训练 GPT-175B),该框架能提供 FP8 精度的低位数并行化,包括张量、训练流程和训练的并行化,这能铺就通往下一代低精度并行训练的道路。
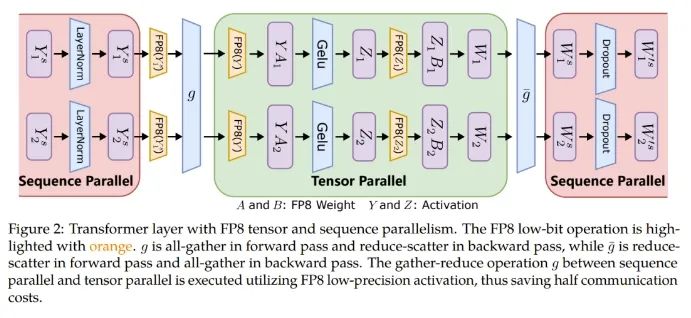
张量并行化是将一个模型的各个层分散到多台设备上,从而将权重、梯度和激活张量的分片放在不同的 GPU 上。
为了让张量并行化支持 FP8,微软这个团队的做法是将分片的权重和激活张量转换成 FP8 格式,以便线性层计算,从而让前向计算和后向梯度集体通信全都使用 FP8。
另一方面,序列并行化则是将输入序列切分成多个数据块,然后将子序列馈送到不同设备以节省激活内存。
如图 2 所示,在一个 Transformer 模型中的不同部分,序列并行化和张量并行化正在执行,以充分利用可用内存并提高训练效率。
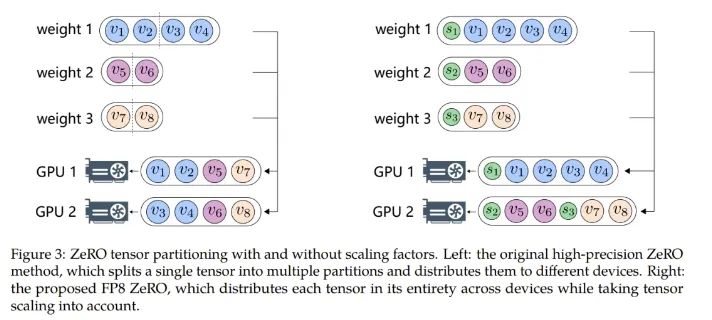
而对于 ZeRO(零冗余优化器 / Zero Redundancy Optimizer),却无法直接应用 FP8,因为其难以处理与 FP8 划分有关的缩放因子。因此针对每个张量的缩放因子应当沿着 FP8 的划分方式分布。
为了解决这个问题,研究者实现了一种新的 FP8 分配方案,其可将每个张量作为一个整体分散到多台设备上,而不是像 ZeRO 方法一样将其切分成多个子张量。该方法是以一种贪婪的方式来处理 FP8 张量的分配,如算法 1 所示。

具体来说,该方法首先根据大小对模型状态的张量排序,然后根据每个 GPU 的剩余内存大小将张量分配到不同的 GPU。这种分配遵循的原则是:剩余内存更大的 GPU 更优先接收新分配的张量。通过这种方式,可以平滑地沿张量分配张量缩放因子,同时还能降低通信和计算复杂度。图 3 展示了使用和不使用缩放因子时,ZeRO 张量划分方式之间的差异。
使用 FP8 训练 LLM 并不容易。其中涉及到很多挑战性问题,比如数据下溢或溢出;另外还有源自窄动态范围的量化错误和 FP8 数据格式固有的精度下降问题。这些难题会导致训练过程中出现数值不稳定问题和不可逆的分歧问题。为了解决这些问题,微软提出了两种技术:精度解耦(precision decoupling)和自动缩放(automatic scaling),以防止关键信息丢失。
精度解耦
精度解耦涉及到解耦数据精度对权重、梯度、优化器状态等参数的影响,并将经过约简的精度分配给对精度不敏感的组件。
针对精度解耦,该团队表示他们发现了一个指导原则:梯度统计可以使用较低的精度,而主权重必需高精度。
更具体而言,一阶梯度矩可以容忍较高的量化误差,可以配备低精度的 FP8,而二阶矩则需要更高的精度。这是因为在使用 Adam 时,在模型更新期间,梯度的方向比其幅度更重要。具有张量缩放能力的 FP8 可以有效地将一阶矩的分布保留成高精度张量,尽管它也会导致精度出现一定程度的下降。由于梯度值通常很小,所以为二阶梯度矩计算梯度的平方可能导致数据下溢问题。因此,为了保留数值准确度,有必要分配更高的 16 位精度。
另一方面,他们还发现使用高精度来保存主权重也很关键。其根本原因是在训练过程中,权重更新有时候会变得非常大或非常小,对于主权重而言,更高的精度有助于防止权重更新时丢失信息,实现更稳定和更准确的训练。
自动缩放
自动缩放是为了将梯度值保存到 FP8 数据格式的表征范围内,这需要动态调整张量缩放因子,由此可以减少 all-reduce 通信过程中出现的数据下溢和溢出问题。
具体来说,研究者引入了一个自动缩放因子 μ,其可以在训练过程中根据情况变化。
实验结果
为了验证新提出的 FP8 低精度框架,研究者实验了用它来训练 GPT 式的模型,其中包括预训练和监督式微调(SFT)。实验在 Azure 云计算最新 NDv5 H100 超算平台上进行。
实验结果表明新提出的 FP8 方法是有效的:相比于之前广泛使用 BF16 混合精度训练方法,新方法优势明显,包括真实内存用量下降了 27%-42%(比如对于 GPT-7B 模型下降了 27%,对于 GPT-175B 模型则下降了 42%);权重梯度通信开销更是下降了 63%-65%。
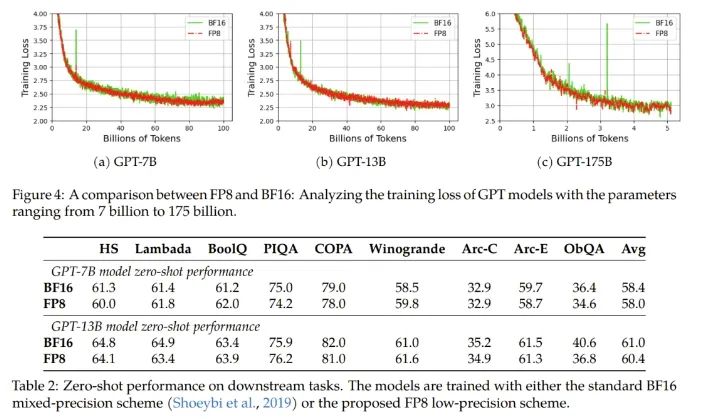
不修改学习率和权重衰减等任何超参数,不管是预训练任务还是下游任务,使用 FP8 训练的模型与使用 BF16 高精度训练的模型的表现相当。值得注意的是,在 GPT-175B 模型的训练期间,相比于 TE 方法,在 H100 GPU 平台上,新提出的 FP8 混合精度框架可将训练时间减少 17%,同时内存占用少 21%。更重要的是,随着模型规模继续扩展,通过使用低精度的 FP8 还能进一步降低成本,如图 1 所示。
对于微调,他们使用了 FP8 混合精度来进行指令微调,并使用了使用人类反馈的强化学习(RLHF)来更好地将预训练后的 LLM 与终端任务和用户偏好对齐。
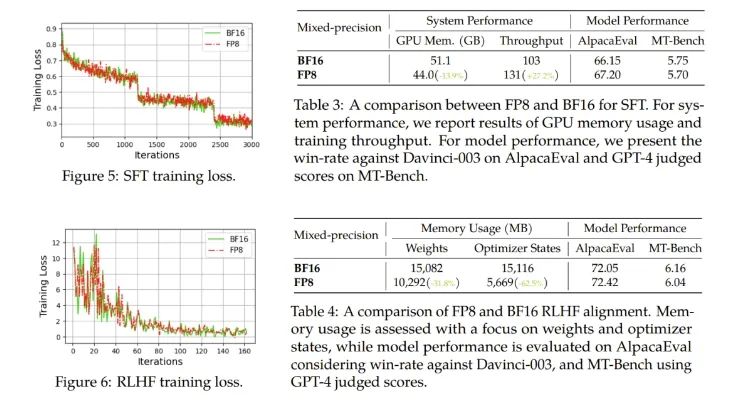
结果发现,在 AlpacaEval 和 MT-Bench 基准上,使用 FP8 混合精度微调的模型与使用半精度 BF16 微调的模型的性能相当,而使用 FP8 的训练速度还快 27%。此外,FP8 混合精度在 RLHF 方面也展现出了巨大的潜力,该过程需要在训练期间加载多个模型。通过在训练中使用 FP8,流行的 RLHF 框架 AlpacaFarm 可将模型权重减少 46%,将优化器状态的内存消耗减少 62%。这能进一步展现新提出的 FP8 低精度训练框架的多功能性和适应性。
他们也进行了消融实验,验证了各组件的有效性。
可预见,FP8 低精度训练将成为未来大模型研发的新基建。
2. 万万没想到,ChatGPT参数只有200亿?
原文:https://mp.weixin.qq.com/s/4oovtS-FaA-Yvk0Tgy3Lng
谁都没有想到,ChatGPT 的核心秘密是由这种方式,被微软透露出来的。
昨天晚上,很多讨论 AI 的微信群都被一篇 EMNLP 论文和其中的截图突然炸醒。
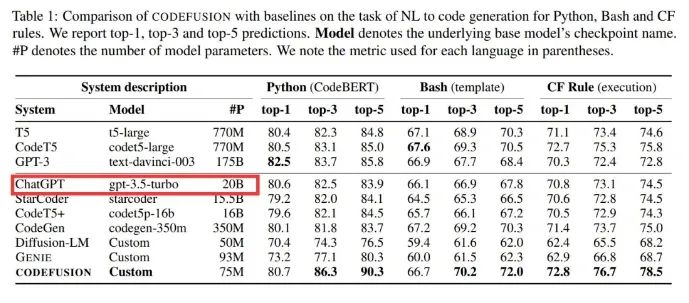
微软一篇题为《CodeFusion: A Pre-trained Diffusion Model for Code Generation》的论文,在做对比的时候透露出了重要信息:ChatGPT 是个「只有」20B(200 亿)参数的模型,这件事引起了广泛关注。
距 ChatGPT 发布已经快一年了,但 OpenAI 一直未透露 ChatGPT 的技术细节。由于其强大的模型性能,人们对 ChatGPT 的参数量、训练数据等信息抱有诸多疑问和猜测。
作为行业一直以来的标杆,ChatGPT 性能强大,可以解决各种各样的问题。它的前身 GPT-3 参数量就达到了 1750 亿,实用化以后的大模型居然被 OpenAI 瘦身了快 9 倍,这合理吗?
「如何看待这篇论文」的话题立刻冲上了知乎热榜。

具体来说,微软这篇论文提出了一种预训练的扩散代码生成模型 ——CodeFusion。CodeFusion 的参数量是 75M。在实验比较部分,论文的表 1 将 ChatGPT 的参数量明确标成了 20B。
众所周知,微软和 OpenAI 是合作已久的一对伙伴,并且这是一篇 EMNLP 2023 论文,因此大家推测这个数据很有可能是真实的。
然而,关于 ChatGPT 参数量的猜测,人们一直认为是一个庞大的数字,毕竟 GPT-3 的参数量就已经达到了 175B(1750 亿)。掀起大型语言模型(LLM)浪潮的 ChatGPT,难道就只有 20B 参数?
大家怎么看?
这个数据被扒出来之后,在知乎和 Twitter 已经引起了广泛讨论。毕竟,200 亿参数达到这样的效果十分惊人。再则,国内追赶出的大模型动则就是数百亿、上千亿。
那么这个数据保不保真?大家都有什么看法呢?
NLP 知名博主、新浪微博新技术研发负责人张俊林「盲猜」分析了一波,引起了大家广泛赞同:
不负责任猜测一波:GPT 4 是去年 8 月做好的,ChatGPT 估计是 OpenAI 应对 Anthropic 要推出的 Claude 专门做的,那时候 GPT 4 应该价值观还没对齐,OpenAI 不太敢放出来,所以临时做了 ChatGPT 来抢先发优势。OpenAI 在 2020 年推出 Scaling law 的文章,Deepmind 在 2022 年推出的改进版本 chinchilla law。OpenAI 做大模型肯定会遵循科学做法的,不会拍脑袋,那么就有两种可能:
可能性一:OpenAI 已经看到 Chinchilla 的论文,模型是按照龙猫法则做的,我们假设 ChatGPT 的训练数据量不低于 2.5T token 数量(为啥这样后面分析),那么按照龙猫法则倒推,一般训练数据量除以 20 就应该是最优参数量。于是我们可以推出:这种情况 ChatGPT 模型的大小约在 120B 左右。
可能性二:OpenAI 在做 ChatGPT 的时候还没看到 Chinchilla 的论文,于是仍然按照 OpenAI 自己推导的 Scaling law 来设计训练数据量和模型大小,推算起来训练数据量除以 12.5 左右对应模型最优参数,他们自己的 Scaling law 更倾向把模型推大。假设训练数据量是 2.5T 左右,那么这种情况 ChatGPT 的模型大小应该在 190 到 200B 左右。
大概率第一个版本 ChatGPT 推出的时候在 200B 左右,所以刚出来的时候大家还是觉得速度慢,价格也高。3 月份 OpenAI 做过一次大升级,价格降低为原先的十分之一。如果仅仅靠量化是不太可能压缩这么猛的,目前的结论是大模型量化压缩到 4 到 6bit 模型效果是能保持住不怎么下降的。
所以很可能 OpenAI 这次升级从自己的 Scaling law 升级到了 Chinchilla 的 Scaling law,这样模型大小就压缩了 120B 左右,接近一半(也有可能远小于 120B,如果按照 chinchilla law,llama 2 最大的模型应该是 100B 左右,此时算力分配最优,也就是说成本收益最合算。但是实际最大的 llama2 模型才 70B,而且更小的模型比如 7B 模型也用超大数据集。
llama1 65B 基本是符合 chinchilla law 的,llama2 最大模型已经打破 chinchilla law 开始怼数据了。就是说目前大家做大模型的趋势是尽管不是算力分配最优,但是都倾向于增加数据减小模型规模,这样尽管训练成本不合算,但是推理合算,而训练毕竟是一次性的,推理则并发高次数多,所以这么配置很明显总体是更合算的),再加上比如 4bit 量化,这样推理模型的大小可以压缩 4 倍,速度大约可提升 8 倍左右,如果是采取继续增加训练数据减小模型规模,再加上其它技术优化是完全有可能把推理价格打到十分之一的。
后续在 6 月份和 8 月份各自又价格下调了 25%,最终可能通过反复加数据减小规模逐渐把模型压缩到 20B 左右。
这里解释下为何 ChatGPT 的训练数据量不太可能比 2.5T 低,LLaMA 2 的训练数据量是 2T,效果应该稍弱于 ChatGPT,所以这里假设最少 2.5T 的训练数据。目前研究结论是当模型规模固定住,只要持续增加训练数据量,模型效果就会直接增长,mistral 7B 效果炸裂,归根结底是训练数据量达到了 8 个 T,所以导致基础模型效果特别强。以 ChatGPT 的效果来说,它使用的数据量不太可能低于 2.5T。
当然,还有另外一种可能,就是 ChatGPT 在后期优化(比如第一次大升级或者后续的升级中,开始版本不太可能走的这条路)的时候也不管 scaling law 了,走的是类似 mistral 的路线,就是模型大小固定在 20B,疯狂增加训练数据,如果又构造出合适的 instruct 数据,效果也可能有保障。
不论怎么讲,对于 6B 到 13B 左右比较适合应用落地的模型,强烈呼吁中文开源模型模仿 mistral,固定住一个最适合使用的模型大小,然后疯狂增加训练数据,再加上好的 instruct 策略,是有可能作出小规模效果体验足够好的模型的。我个人认为对于开源模型来说,7B-13B 左右大小的模型应该是兵家必争之地。有心气做开源的可以再努把力,把训练数据往上再努力怼一怼。
早在 OpenAI 开放 ChatGPT API 时,0.002 美元 / 1k token 的定价就令人们意外,这个价格只有 GPT-3.5 的 1/10。彼时就有人推测:「ChatGPT 是百亿(~10B)参数的模型」,并且「ChatGPT 使用的奖励模型(reward model)可能是千亿级模型」。该推测来源于清华大学 NLP 在读博士郑楚杰的知乎回答。

但所有这些都是猜测,由于 OpenAI 对参数量、训练数据、方法等核心信息一直讳莫如深,因此 20B 这个数据到底是不是真的根本无法求证。如果是真的,那么大型语言模型未来的改进方向还会是增加参数量吗?
再过几天,就是 OpenAI 的开发者大会了,也许我们能够了解到更多有用的信息,让我们拭目以待吧。
3. 代码能力超越GPT-4,这个模型登顶Big Code排行榜,YC创始人点赞
原文:https://mp.weixin.qq.com/s/fSVPRjNpWPVrLVA59PrIBA
一款号称代码能力超越GPT-4的模型,引发了不少网友的关注。
准确率比GPT-4高出超过10%,速度却接近GPT-3.5,而且窗口长度也更长。
据开发者描述,他们的模型取得了74.7%的Pass@1通过率,超过了原始GPT-4的67%,登上了Big Code榜首。
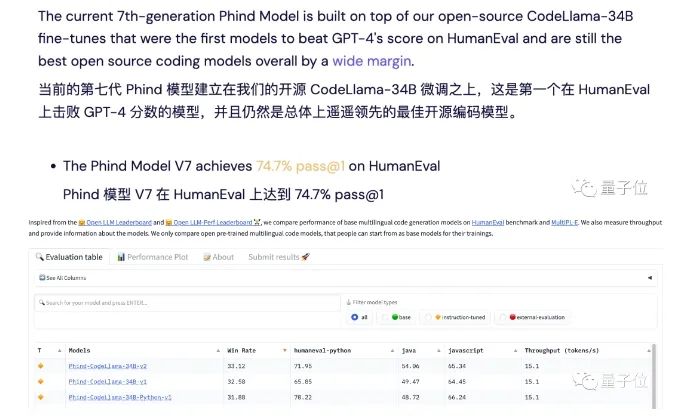
这个模型名叫Phind,和以其为基础的面向开发者的AI搜索工具同名。
它是由开发团队在CodeLlama-34B的基础之上微调得到的。
Phind利用TensorRT-LLM在H100上可以跑出每秒100个token的速度,是GPT-4的5倍。
此外,Phind的上下文长度达到了16k,其中12k可供用户输入,另外4k保留给检索结果中的文本。

针对这个产品,网友们议论纷纷,结果是喜忧参半:
支持的人,如著名创业投资公司YCombinator创始人Paul Graham表示,Phind可以让人们用更少的资源和大厂抗衡。

Phind vs GPT-4
正式开始之前,先来说说对Phind的第一印象。
它的界面十分简洁,主要就是一个搜索框,而且不需要登录就能无限量使用。
左下角有一个Pair Programmer的开关,直观上的区别就是开启之后回答界面更侧重对话,不开启的话则更像搜索引擎。
此外,还可以从自研模型和GPT-4中选择,GPT-4则需要登录,而且每天只能用10次。

接下来就是和GPT-4进行的对比测试,GPT-4没有开启代码解释器。
首先还是从LeetCode题目开始测起,Prompt就是是原问题加上下面这段话:
请用Python写一段代码解决这个问题,给出通用的解法,不需要设定参数值,代码需要以如下内容开头:(LeetCode页面中给出的起始片段)
为了防止Phind通过检索来“作弊”,我们还在Phind的Prompt结尾加入了这句话:
不要检索任何信息,靠你自己的能力创建代码
第一题在LeetCode中被归为组合数学问题,难度为困难,通过率67.1%。

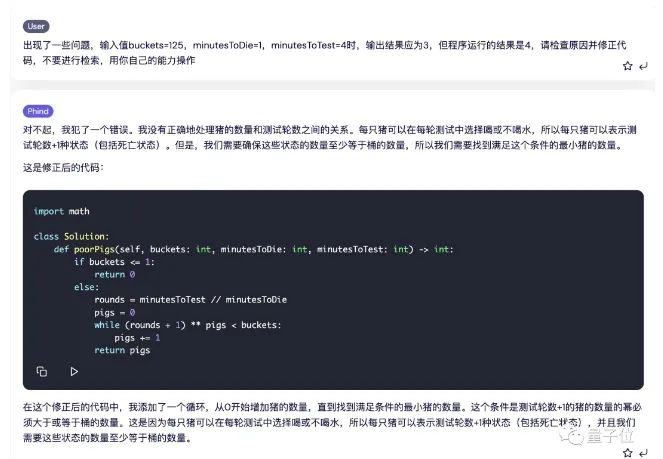
Phind给出了这样的代码和解释,经过测试,20条测试数据中有19项正确。

出错的是这一条,这里的输出结果应该是3,但Phind给出的程序运行结果是4。

我们试着反馈给Phind,看它能不能找出错误的原因,结果分析一番之后给出了新的代码,并通过了测试。
而GPT-4这边,则是一次性通过。
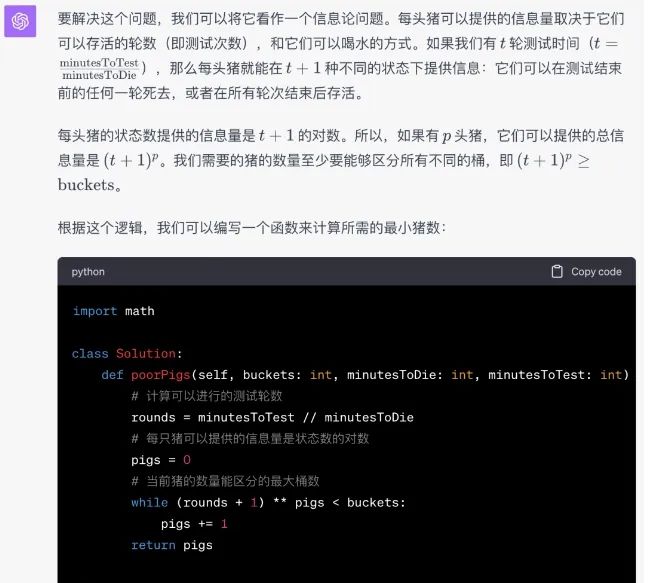
道LeetCode题目测试下来,Phind以一平两负的成绩输给了GPT-4。
但需要说明的是,这里我们为了测试模型本身表现,通过提示词关闭了Phind的检索功能,但从实用角度出发,如果保留搜索,Phind还是能很好地解决这些问题的。
接着,我们又测试了一下他们的实际开发能力,这次的题目是扫雷游戏。
Phind会问我们有没有什么特殊要求,这里我们直接点跳过。
然后Phind会对任务进行拆解,对每个子任务又分别进行检索。

这时的代码也是分段给出的,有趣的是,在生成过程中,Phind会使用不同来源中的代码。
然后我们让Phind给出完整代码,并通过链接的第三方平台直接运行。
结果呢,我们一进去就看到程序已经非常“贴心”地把雷的位置清楚地标注好了。
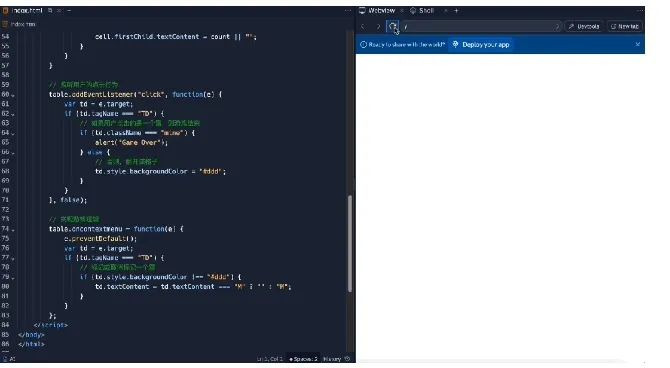
不过这次,GPT-4的代码更加离谱一些,运行出来是这样的:

虽然都没做对,但硬要比较的话,这一轮,Phind略胜一筹。
一路测试下来,很难判断它们孰优孰劣,但考虑到搜索能力,以及免费免登录的特性,Phind还是可圈可点的。
4. 中文最强开源大模型来了!130亿参数,0门槛商用,来自昆仑万维
原文:https://mp.weixin.qq.com/s/MKu6eusxyCXw3fLhgbcp0A
开源最彻底的大模型来了——130亿参数,无需申请即可商用。
不仅如此,它还附带着把全球最大之一的中文数据集也一并开源了出来:600G、1500亿tokens!
这就是来自昆仑万维的Skywork-13B系列,包含两大版本:
-
Skywork-13B-Base:该系列的基础模型,在多种基准评测中都拔得头筹的那种。
-
Skywork-13B-Math:该系列的数学模型,数学能力在GSM8K评测上得分第一。
在各大权威评测benchmark上,如C-Eval、MMLU、CMMLU、GSM8K,可以看到Skywork-13B在中文开源模型中处于前列,在同等参数规模下为最优水平。
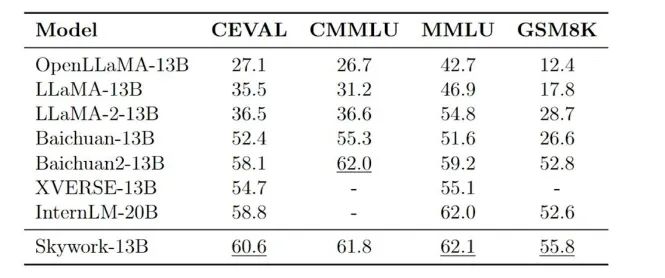
而Skywork-13B系列之所以能取得如此亮眼的成绩,部分原因离不开刚才我们提到的数据集。
毕竟清洗好的中文数据对于大模型来说可谓是至关重要,几乎从某种程度上决定了其性能。
但昆仑万维能将如此“至宝”无偿地给奉献出来,不难看出它对于构建开源社区、服务开发者的满满诚意。
除此之外,昆仑万维Skywork-13B此次还配套了“轻量版”大模型,是在消费级显卡中就能部署和推理的那种!
Skywork-13B下载地址(Model Scope):https://modelscope.cn/organization/skywork
Skywork-13B下载地址(Github):https://github.com/SkyworkAI/Skywork
接下来,我们进一步来看下Skywork-13B系列更多的能力。
无需申请即可商用
Skywork-13B系列大模型拥有130亿参数、3.2万亿高质量多语言训练数据。
由此,模型在生成、创作、数学推理等任务上提升明显。
首先在中文语言建模困惑度评测中,Skywork-13B系列大模型超越了目前所有中文开源模型。
在科技、金融、政务、企业服务、文创、游戏等领域均表现出色。
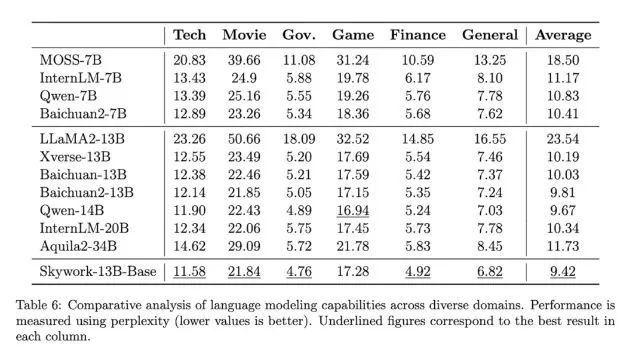
另外,Skywork-13B-Math专长数学任务,进行过数学能力强化训练,在GSM8K等数据集中取得了同等规模模型最佳效果。
与此同时,昆仑万维还开源了数据集Skypile/Chinese-Web-Text-150B。其数据是通过精心过滤的数据处理流程从中文网页中筛选而来。
由此,开发者可以最大程度借鉴技术报告中大模型预训练的过程和经验,深度定制模型参数,进行针对性训练与优化 。
除此之外,Skywork-13B还公开了模型使用的评估方法、数据配比研究和训练基础设施调优方案等。
而Skywork-13B的一系列开源,无需申请即可商用!
用户在下载模型并同意遵守《Skywork模型社区许可协议》后,不用再次申请商业授权。
授权流程也取消了对行业、公司规模、用户数量等方面限制。
昆仑万维会如此彻底开源其实也并不意外。
昆仑万维董事长兼CEO方汉是最早参与到开源生态建设的老兵了,也是中文Linux开源最早的推动者之一。
在今年ChatGPT趋势刚刚兴起时,他就多次公开发声、强调开源的重要性:
代码开源可助力中国版ChatGPT弯道超车。
所以也就不难理解Skywork-13B系列大模型的推出了。
而在短短2个月后,昆仑万维又将最新的大模型、最新的数据集,一并发布且开源,可以说它的一切动作不仅在于快,更是在于敢。
那么接下来的问题是——为什么要这么做?
其实,对于AIGC这一板块,昆仑万维早在2020年便已经开始涉足,早早的准备和技术积累就是它能够在大热潮来临之际快速跟进的原因之一。
据了解,昆仑万维目前已形成AI大模型、AI搜索、AI游戏、AI音乐、AI动漫、AI社交六大AI业务矩阵。
至于不遗余力的将开源这事做好做大,一方面是源于企业的基因。
昆仑万维董事长兼CEO方汉是最早参与到开源生态建设的开源老兵,也是中文Linux开源最早的推动者之一,开源的精神和AIGC技术的发展早已在昆仑万维战略中完美融合。
正如方汉此前所言:
昆仑天工之所以选择开源,因为我们坚信开源是推动AIGC生态发展的土壤和重要力量。昆仑万维致力于在AIGC模型算法方面的技术创新和开拓,致力于推进开源AIGC算法和模型社区的发展壮大,致力于降低AIGC技术在各行各业的使用和学习门槛。
没错,降低门槛,便是其坚持开源的另一大原因。
从昆仑万维入局百模大战以来的种种动作中,也很容易看到它正在践行着让天工用起来更简单、更丝滑。
总而言之,昆仑万维目前已然是处于国产大模型的第一梯队,甚至说是立于金字塔尖都不足为过。
那么在更大力度的开源加持之下,天工大模型还将有怎样惊艳的表现,是值得期待一波了。
5. A17 Pro vs 8Gen3,手机旗舰SoC迭代,GPU和NPU成为下一轮发力点
原文:https://mp.weixin.qq.com/s/1snqc5TKjPajcUz4ELIO6w
电子发烧友网报道(文/周凯扬)随着2023年步入尾声,无论是苹果还是高通,都已经推出了新一代的旗舰手机SoC,这也昭示着安卓与iOS阵营手机性能的又一次年末大比。然而,对比过去拼通用计算性能和通用图形计算性能的局面,今年两大厂商都已经开始卷向其他的计算负载,比如光追、超分这样的特殊GPU负载,以及终于被积极调动算力的NPU单元。我们就从CPU,GPU和NPU三个手机SoC主力计算单元来分析苹果A17 Pro和高通骁龙8Gen3在设计上新一轮迭代。
CPU,单核多核性能各有千秋
A17 Pro和骁龙8Gen3分别是基于台积电3nm和4nm工艺打造的芯片,在最先进的半导体工艺下,CPU上的提升尤其引人注目,尤其是苹果的A17 Pro还是首发3nm的芯片。然而在各路实机测试的表现中,两者的成绩却是各有胜负。
A17 Pro虽说用上了最先进的3nm工艺,且对微架构进行了一定的改进,最大主频从A16时期的3.46GHz大幅提升至3.78GHz,但A17 Pro依然保持了6核(2性能核+4能效核)的配置,即便是在苹果自己给出的性能指标中,相较上一代也只有10%的性能提升。
而高通的骁龙8Gen3 Kyro CPU,通过升级大核为Cortex-X4、升级中核为Cortex-A720、升级小核为Cortex-A520,并将一个额外的能效核转换成了性能核,从上一代的1:4:3配置,换成了1:5:2配置。正是因为在如此激进的设计改动下,8Gen3的CPU实现了30%的性能提升,20%的能效提升。
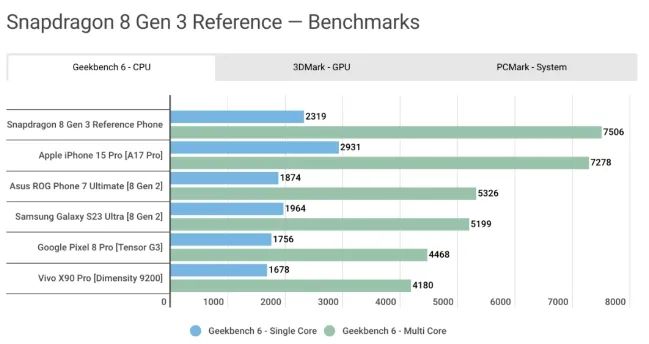
然而在Geekbench 6的测试中,我们还是能看到一些有意思的对比。根据androidauthority对iPhone15 Pro和骁龙8Gen3参考机的测试可以看出,在单核性能上,A17 Pro还是领先一大截的,而在多核性能上,骁龙8Gen3终于实现了反超。这不免让人期待起未来Snapdragon X Elite的CPU架构下放到手机SoC后,高通CPU的单核性能会有怎样的提升。
GPU,光追和超分辨率技术
至于GPU性能的对比,结果与上一代似乎并没有太大不同,在3D Mark的测试中,A17 Pro的GPU全方位落后于骁龙8Gen3。根据苹果的说法,他们对这一代GPU进行了历史上最大的一次重新设计,但从这个结果来看,重新设计的方向应该主要放在了硬件光追和超分技术上,其相比前代提升的20%GPU性能还是无法与骁龙8Gen3相提并论。
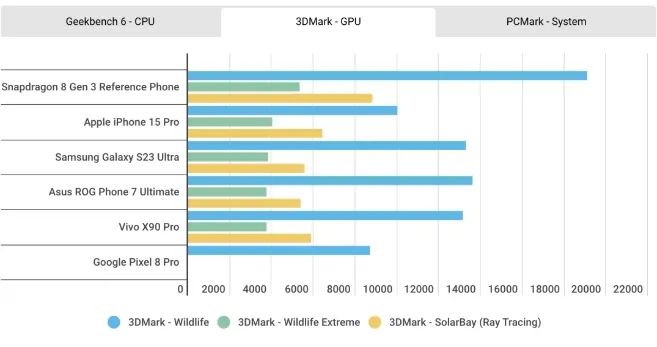
今年的手机SoC设计中,硬件光追已经成了标配。苹果称其GPU加入的硬件光追相较基于软件的光追,速度提升了4倍,更适合用于沉浸式AR应用和游戏体验。不过相较从上一代骁龙8Gen2就开始布局硬件光追的高通来说,苹果在硬件光追上的性能水平还是有所不及。从上面的3DMark光追测试成绩可以看出,8Gen3的硬件光追加速性能要高出A17 Pro一大截。
高通在硬件光追的开发上也领先于苹果,相比去年8Gen2仅有实时光追支持,今年的骁龙8Gen3还加入了对虚幻5引擎Lumen全局光照和反射系统的支持,可以实现比普通硬件光追更好的光线表现效果。
除了硬件光追以外,无论是高通还是苹果,都在这一代GPU的设计中加入了超分辨率的技术,比如苹果的MetalFX和高通的Snapdragon Game Super Resolution(GSR)。为了运行性能要求更高的3A游戏大作,仅仅靠堆高GPU性能是远远不够的,受限于智能手机的散热结构,我们需要英伟达DLSS或AMD的FSR这类超分辨率技术进一步降低配置要求和功耗。
去年的WWDC 2022上,苹果正式宣布了MetalFX这一超分技术,利用相对较低分辨率的图像输出更高的分辨率,从而减少渲染负载,提高应用或游戏体验。不过届时该技术主要是为M2系列的处理器开发的,而如今苹果已经打算将这一技术引入手机GPU。
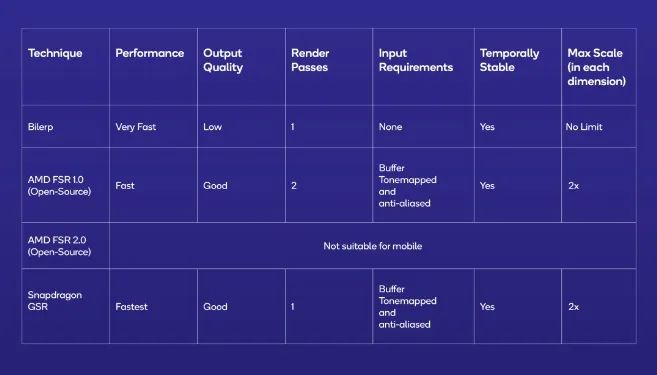
而高通则在今年推出了GSR这一超分技术,高通宣称可以提供10bit HDR 144FPS的游戏性能体验。从上述超分技术对比中可以看出,GSR最高可以实现两倍的超分。高通还表示,虽然GSR技术兼容大部分GPU,但只有在骁龙硬件平台上才能发挥出最大性能。
不过在实现方式上,苹果的MetalFX和高通的GSR还是有一些区别的。高通的GSR是一项单通空域超分辨率技术,与AMD开源的FSR 1.0实现方式一样。而苹果的MetalFX,则给到了开发者选择,既可以采用空域超分辨率技术,也可以使用FSR 2.0一样的时域抗锯齿超分辨率技术。
不过,高通选择这一技术路线不是没有原因的,首先空域超分更容易达到较好的性能和图像质量表现,比过去的插值超分在边缘细节上更有优势。而时域超分虽说可以实现更好的图像质量,但其所需的数据输入在手机图形的渲染管线却不常见,只有一部分PC游戏移植到手机上更适合这一方案。
这点从苹果MetaFX的开发文档中也可以看出,如果只选择空域超分的话,开发者只需要输入像素色彩,而选择时域超分则需要提供像素色彩、深度和动态信息,这对游戏开发者来说,就需要在渲染管线上花更多的工夫。所以高通的GSR和苹果MetaFX中的空域超分更容易适配,相信未来即将支持超分的一大批游戏都会选择这一方案。
NPU,设备端生成式AI
自今年生成式AI成为热门应用后,手机SoC厂商以及大模型应用开发者们均看到了手机AI计算单元NPU的另一大功用。尤其是在高通骁龙8Gen 3的产品详情中,高通着重介绍了这一芯片平台在生成式AI上的优势。
骁龙8Gen 3的Hexagon NPU相较上一代有了质的提升,性能提升高达98%,能效比提升高达40%。这也是高通首度在NPU中加入支持多模态生成式AI模型的AI引擎,该引擎支持LLM(大语言模型)、LVM(语言视觉模型)和ASR(自动语音识别)模型,端侧最大支持100亿参数的模型。
在LLM上,以Meta 70亿参数的Llama 2模型为例,骁龙8Gen 3支持到20token每秒的表现。同时NPU也进一步提高了Sensing Hub各大传感器调用用户数据的能力,比如同时支持两个始终感应的摄像头等。
苹果今年似乎并没有着重强调A17 Pro的神经引擎,除了35TOPS的计算性能。不过从M2和M3系列的神经引擎配置来看,苹果或许对于A17 Pro这一智能手机SoC的AI性能有更多的准备。要知道,同为16核的神经引擎,去年的A16和M2芯片其AI算力只有17 TOPS,哪怕是刚公布的M3系列芯片,其AI算力都只有18TOPS。
写在最后
至此,我们看到了高通和苹果两家厂商对于AI计算的重视,只不过两者的侧重点略有不同。比如目前苹果目前更注重于打造“直觉式AI”,着重加强设备端系统级AI和多媒体AI的表现,比如输入法自动更正、个人语音、拍照人像模式、第三方app中的图片降噪/超分等。而高通已经开始拥抱生成式AI,尤其是智能语音助手的AI性能,也给到了第三方AI应用开发者更自由的硬件资源调用。
然而无论是从纸面参数,还是从各大性能测试得出的结果可知,安卓旗舰SoC与苹果SoC的性能代差已经完全消除了,甚至前者在GPU性能上已经实现了反超。由此也可以看出,半导体工艺提升带来的性能收益已经在缩小,反而是芯片微架构和核心配置决定了最终的手机SoC性能。
6. IBM最新推出一款类脑芯片“NorthPole” 用于快速高效的人工智能
原文:https://mp.weixin.qq.com/s/nG3otCtN1mwSHKXEw-0vxw
据悉,IBM公司最新推出了一款名为“NorthPole(https://research.ibm.com/blog/northpole-ibm-ai-chip)”的类脑芯片,其运行由人工智能驱动的图像识别算法的速度是同类商业芯片的22倍,能效是同类芯片的25倍。根据IBM的一项研究显示,新型硅芯片的应用可能包括自动驾驶汽车和机器人。
以大脑为灵感的计算机硬件旨在模仿人脑以异常节能的方式快速执行计算的非凡能力。这些机器通常用于实现神经网络,类似地模仿大脑的学习和操作方式。
“NorthPole merges the boundaries between brain-inspired computing and silicon-optimized computing, between compute and memory, between hardware and software.”
—DHARMENDRA MODHA, IBM
受大脑启发的电子学经常采用的一种策略是复制生物神经元计算和存储数据的方式。将处理器和内存结合起来,可以大大减少计算机在这些组件之间穿梭数据所损失的能量和时间。
该研究的主要作者、IBM大脑启发计算的首席科学家Dharmendra Modha说:“大脑比现代计算机节能得多,部分原因是它在每个神经元中都存储了带有计算功能的内存。”
Modha说:“NorthPole融合了大脑启发计算和硅优化计算、计算和内存、硬件和软件之间的界限。”
新芯片针对2位、4位和8位低精度操作进行了优化。研究人员表示,这足以在许多神经网络上实现最先进的精度,同时省去训练所需的数值。该研究原型在25至425兆赫的频率范围内工作,每个核心每个周期可以以8位精度执行2048次操作,以2位精度执行8192次操作。
NorthPole是在过去八年中开发的,它建立在IBM最后一款类脑芯片TrueNorth的基础上。TrueNorth于2014年首次亮相,其功率效率比当时的传统微处理器低四个数量级。
Modha说:“NorthPole的主要目标是大幅降低TrueNorth的潜在资本成本。”
科学家们用两个人工智能系统测试了NorthPole —— ResNet 50图像分类网络和Yolo-v4物体检测网络。与使用类似12纳米节点制造的英伟达V100 GPU相比,NorthPole每瓦的能效是后者的25倍,速度是后者的22倍,同时面积只占五分之一。
“Given that analog systems are yet to reach technological maturity, this work presents a near-term option for AI to be deployed close to where it is needed.”
—VWANI ROYCHOWDHURY, UCLA
NorthPole的表现也优于市场上所有其他芯片,即使是使用更先进节点制造的芯片。例如,与使用4nm节点实现的英伟达H100 GPU相比,NorthPole的能效高出五倍。事实证明,NorthPole的速度大约是TrueNorth的4000倍。
加州大学洛杉矶分校的计算和人工智能科学家Vwani Roychowdhury没有参与这项研究,他说:“这篇论文代表了一场工程之旅。”
新芯片的速度和效率来自于它所有的内存都在芯片上。这意味着每个核心都可以同样轻松地访问芯片上的存储器。
此外,Modha说,从设备外部看,NorthPole是一个有源存储芯片。这有助于将NorthPole集成到系统中。
Modha说,NorthPole的潜在应用可能包括图像和视频分析、语音识别,以及被称为变压器的神经网络,这些网络是为聊天机器人(如ChatGPT)提供动力的大型语言模型(LLM)的基础。IBM表示,这些人工智能任务可能会用于自动驾驶汽车、机器人、数字助理和卫星观测等领域。
一些应用程序要求神经网络太大,无法安装在单个NorthPole芯片上。Modha说,在这种情况下,这些网络可以分解成更小的部分,可以分布在多个NorthPole芯片上。
IBM指出,NorthPole的效率显示出它不需要庞大的液体冷却系统来运行——风扇和散热器就足够了。这意味着它可以部署在更小的空间。
科学家们注意到,IBM用12纳米的节点工艺制造了NorthPole。目前CPU的技术水平是3纳米,IBM已经花了数年时间研究2纳米节点。该公司表示,这表明,这种类脑策略可能很容易取得进一步的成果。
NorthPole的架构类型通常被称为内存计算,可以是数字的,也可以是模拟的。在诸如NorthPole之类的数字内存计算系统中,需要许多电路来运行乘法-累加(MAC)运算,这是神经网络中最基本的计算。相比之下,内存中的模拟计算系统拥有更适合执行这些操作的组件。
内存中的模拟计算比数字计算需要更少的功率和空间。然而,这些模拟系统通常需要新的材料和制造技术,而NorthPole是使用传统的半导体制造技术制造的。
Roychowdhury表示:“鉴于模拟系统尚未达到技术成熟度,这项工作为人工智能在需要的地方部署提供了一个近期选择。”
———————End———————
新生态,创未来 | 2023RT-Thread 开发者大会开启报名
邀请你参加 2023 RT-Thread 开发者大会的六大理由
1、刷新RT-Thread最新技术动态和产业服务能力
2、聆听行业大咖分享,洞察产业趋势
3、丰富的技术和产品展示,前沿技术发展和应用
4、绝佳的实践机会:AIOT、MPU、RISC-V...
5、精美伴手礼人手一份开发板盲盒和免费午餐
6、黑科技满点~滴水湖地铁口安排无人车接送至会场
立刻扫码报名吧

-
RT-Thread
+关注
关注
32文章
1655浏览量
45411
原文标题:【AI简报20231103期】ChatGPT参数揭秘,中文最强开源大模型来了!
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录






HM博学谷狂野AI大模型第四期
腾讯Hy3 preview开源:重构AI大模型技术范式,开启智能计算新纪元
AI大模型微调企业项目实战课
华为昇腾深度适配智谱AI全新开源模型GLM-5




评论