 SparseViT:以非语义为中心、参数高效的稀疏化视觉Transformer
SparseViT:以非语义为中心、参数高效的稀疏化视觉Transformer

背景简介
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。因此目前几乎所有的图像篡改检测模型(IML)都遵循“语义分割主干网络”与“精心制作的手工制作非语义特征提取”相结合的设计,这种方法严重限制了模型在未知场景的伪影提取能力。

论文标题: Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization through Spare-Coding Transformer
作者单位:
四川大学(吕建成团队),澳门大学
论文链接:
https://arxiv.org/abs/2412.14598
代码链接:
https://github.com/scu-zjz/SparseViT
研究内容
利用非语义信息往往在局部和全局之间保持一致性,同时相较于语义信息在图像不同区域表现出更大的独立性,SparseViT 提出了以稀疏自注意力为核心的架构,取代传统 Vision Transformer(ViT)的全局自注意力机制,通过稀疏计算模式,使得模型自适应提取图像篡改检测中的非语义特征。
研究团队在统一的评估协议下复现并对比多个现有的最先进方法,系统验证了 SparseViT 的优越性。同时,框架采用模块化设计,用户可以灵活定制或扩展模型的核心模块,并通过可学习的多尺度监督机制增强模型对多种场景的泛化能力。
此外,SparseViT 极大地降低了计算量(最高减少 80% 的 FLOPs),实现了参数效率与性能的兼顾,展现了其在多基准数据集上的卓越表现。SparseViT 有望为图像篡改检测领域的理论与应用研究提供新视角,为后续研究奠定基础。
SparseViT 总体架构的设计概览图如下所示:
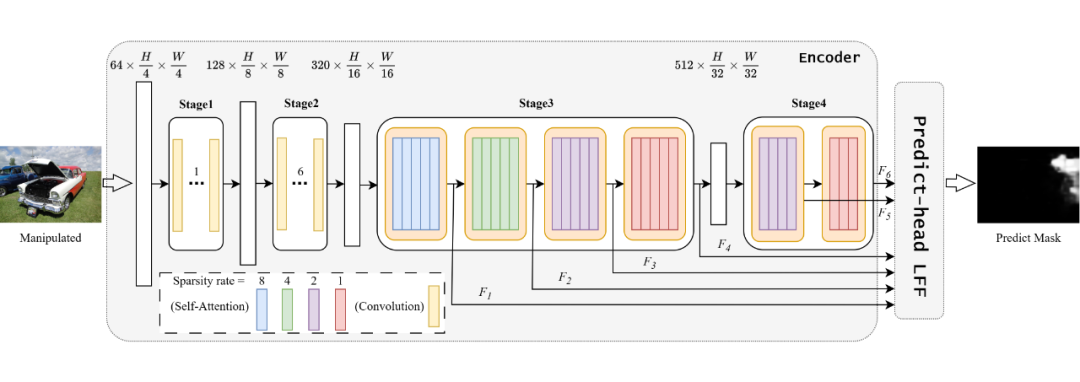
▲ 图1:SparseViT 总体架构
主要的组件包含:
1. 负责高效特征捕获的 Sparse Self-Attention
Sparse Self-Attention 是 SparseViT 框架的核心组件,专注于在减少计算复杂度的同时高效捕获篡改图像中的关键特征即非语义特征。传统的自注意力机制由于 patch 进行 token-to-token 的注意力计算,导致模型对语义信息过度拟合,使得非语义信息在受到篡改后表现出的局部不一致性被忽视。 为此,Sparse Self-Attention 提出了基于稀疏编码的自注意力机制,如图 2 所示,通过对输入特征图施加稀疏性约束,设输入的特征图 ,我们不是对 的整个特征上应用注意力,而是将特征分成形状为的张量块,表示将特征图分解为 个大小为的不重叠的张量块,分别在这些张量块上进行自注意力计算。
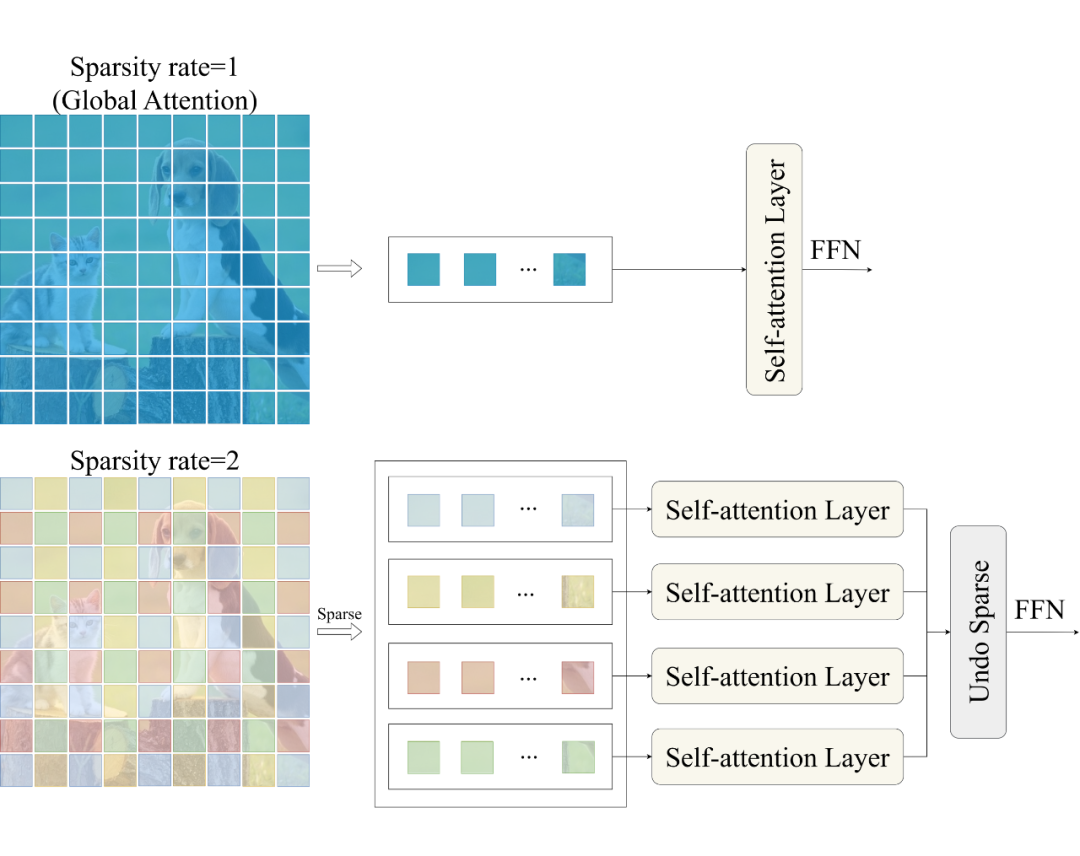
▲ 图2:稀疏自注意力
这一机制通过对特征图进行区域划分,使模型在训练中专注于非语义特征的提取,提升了对图像篡改伪影的捕捉能力。相比传统自注意力,Sparse Self-Attention 减少了约 80% 的 FLOPs,同时保留了高效的特征捕获能力,特别是在复杂场景中表现卓越。模块化的实现方式还允许用户根据需求对稀疏策略进行调整,从而满足不同任务的需求。
2. 负责多尺度特征融合的 Learnable Feature Fusion(LFF)
Learnable Feature Fusion(LFF)是 SparseViT 中的重要模块,旨在通过多尺度特征融合机制提高模型的泛化能力和对复杂场景的适应性。不同于传统的固定规则特征融合方法,LFF 模块通过引入可学习参数,动态调整不同尺度特征的重要性,从而增强了模型对图像篡改伪影的敏感度。
LFF 通过从稀疏自注意力模块输出的多尺度特征中学习特定的融合权重,优先强化与篡改相关的低频特征,同时保留语义信息较强的高频特征。模块设计充分考虑了 IML 任务的多样化需求,既能针对微弱的非语义伪影进行细粒度处理,又能适应大尺度的全局特征提取。
LFF 的引入显著提升了 SparseViT 在跨场景、多样化数据集上的性能,同时减少了无关特征对模型的干扰,为进一步优化 IML 模型性能提供了灵活的解决方案。
研究总结
简而言之,SparseViT 具有以下四个贡献:
1. 我们揭示了篡改图像的语义特征需要连续的局部交互来构建全局语义,而非语义特征由于其局部独立性,可以通过稀疏编码实现全局交互。
2. 基于语义和非语义特征的不同行为,我们提出使用稀疏自注意机制自适应地从图像中提取非语义特征。
3. 为了解决传统多尺度融合方法的不可学习性,我们引入了一种可学习的多尺度监督机制。
4. 我们提出的 SparseViT 在不依赖手工特征提取器的情况下保持了参数效率,并在四个公共数据集上实现了最先进的(SoTA)性能和出色的模型泛化能力。
SparseViT 通过利用语义特征和非语义特征之间的差异性,使模型能够自适应地提取在图像篡改定位中更为关键的非语义特征,为篡改区域的精准定位提供了全新的研究思路。
相关代码和操作文档、使用教程已完全开源在 GitHub 上(https://github.com/scu-zjz/SparseViT)。该代码有着完善的更新计划,仓库将被长期维护,欢迎全球研究者使用和提出改进意见。
SparseViT 的主要科研成员来自四川大学吕建成团队,合作方为澳门大学潘治文教授团队。
-
图像
+关注
关注
2文章
1097浏览量
42496 -
IML
+关注
关注
0文章
14浏览量
11753 -
Transformer
+关注
关注
0文章
156浏览量
6975
原文标题:AAAI 2025 | SparseViT:以非语义为中心、参数高效的稀疏化视觉Transformer
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
激光雷达+视觉组合方案

零基础手写大模型资料2026
嵌入式视觉技术赋能工业自动化领域变革

Transformer 入门:从零理解 AI 大模型的核心原理
MUN12AD05-SMFL:非隔离DC/DC电源模块的国产化替代新选择

炎核开源开放平台上架推出OpenSparseBlas高性能稀疏计算库
数据中心配电房智能化设计:高效稳定
思奥特智能机器视觉光源:以光为笔,绘就工业检测新图景

自动驾驶中如何将稀疏地图与视觉SLAM相结合?



评论