 NVIDIA RTX AI Toolkit拥抱LoRA技术
NVIDIA RTX AI Toolkit拥抱LoRA技术

在 RTX AI PC 和工作站上使用最新版 RTX AI Toolkit 微调 LLM,最高可将性能提升至原来的 6 倍。
凭借其快速理解、总结和生成基于文本的内容的能力,大语言模型(LLM)正在推动 AI 领域中的一些极为激动人心的发展。
LLM 的这些能力可支持各种场景,包括生产力工具、数字助理、电子游戏中的 NPC 等。但它们并非万能的解决方案,开发者通常必须对 LLM 进行微调,使 LLM 适应他们应用的需求。
NVIDIA RTX AI Toolkit 可通过一种名为“低秩自适应(LoRA)”的技术,让用户轻松地在 RTX AI PC 和工作站上微调和部署 AI 模型。现已推出的最新版支持在 NVIDIA TensorRT-LLM AI 加速库中同时使用多个 LoRA,最高可将微调模型的性能提升至原来的 6 倍。
通过微调提升性能
LLM 必须经过精心定制,才能实现更高的性能并满足用户日益增长的需求。
虽然这些基础模型是基于海量数据训练出来的,但它们通常缺乏开发者的特定场景所需的上下文。例如,通用型 LLM 可以生成游戏对话,但很可能会忽略文风的细微差别和微妙之处。例如,以一位有着黑暗过往并蔑视权威的林地精灵的口吻编写对话时,LLM 很有可能会忽略需要展现出来的微妙文风。
为了获得更符合自己需求的输出,开发者可以使用与应用场景相关的信息对模型进行微调。
以开发一款利用 LLM 生成游戏内对话的应用为例。微调时,首先需要使用预训练模型的权重,例如角色可能会在游戏中说出的内容的相关信息。为使对话符合相应文风,开发者可以基于较小的示例数据集(例如以更诡异或更邪恶的语气编写的对话)调整模型。
在某些情况下,开发者可能希望同时运行所有不同的微调流程。例如,他们可能希望为不同的内容频道生成以不同的语气编写的营销文案。同时,他们可能还希望总结文档并提出文风方面的建议,以及为文生图工具起草电子游戏场景描述和图像提示词。
同时运行多个模型并不现实,因为 GPU 显存无法同时容纳所有模型。即使能同时容纳,模型的推理时间也会受制于显存带宽(即 GPU 从显存读取数据的速度)。
拥抱 LoRA 技术
解决上述问题的常用方法是使用低秩自适应(LoRA)等微调技术。简单来说,您可以将这种技术视为补丁文件,其中包含微调流程中的定制过程。
训练完毕后,定制的 LoRA 可以在推理过程中与基础模型无缝集成,额外的性能开销极少。开发者可以将多个 LoRA 连接到单个模型上,以服务多种场景。这样既能使显存占用率保持在较低水平,又能为各个特定场景提供所需的额外细节内容。
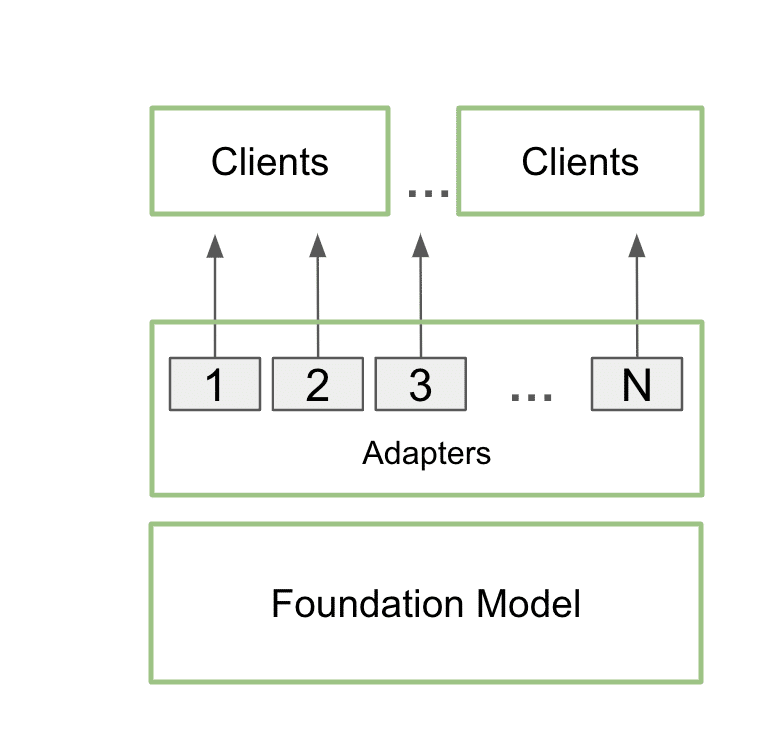
使用多 LoRA 功能通过单个基础模型同时支持多个客户端和场景的架构图
在实际操作中,这意味着应用可以在显存中只保留一个基础模型,同时使用多个 LoRA 实现多种定制。
这个过程称为多 LoRA 服务。当对模型进行多次调用时,GPU 可以并行处理所有调用,更大限度地利用其 Tensor Core 并尽可能减少对显存和带宽的需求,以便开发者在工作流中高效使用 AI 模型。使用多 LoRA 的微调模型的性能最高可提升至原来的 6 倍。
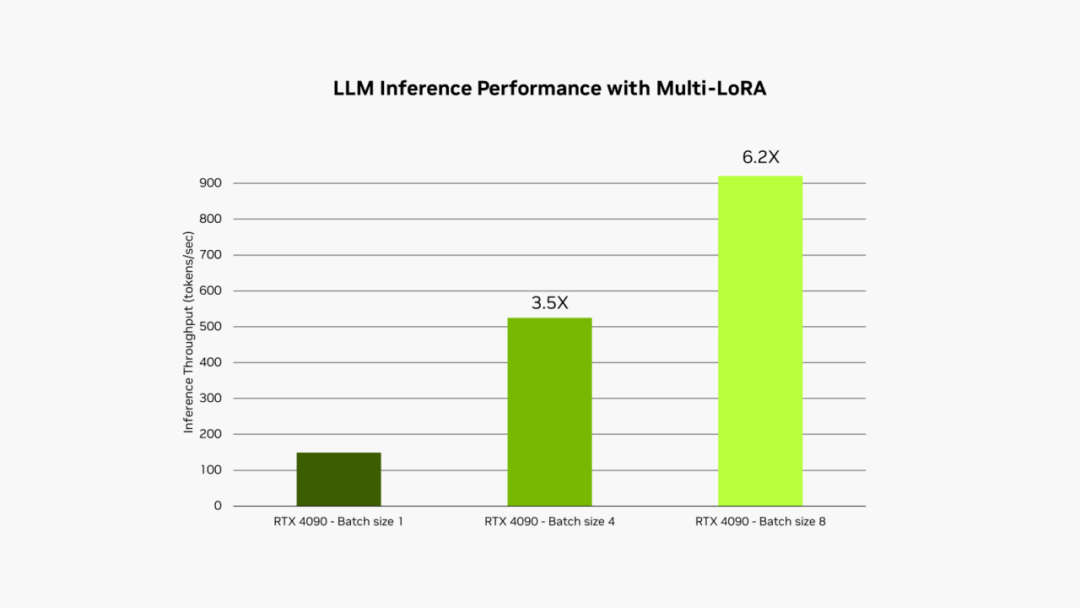
在 GeForce RTX 4090 台式电脑 GPU 上运行 Llama 3B int4 时,应用 LoRA 的 LLM 的推理性能。输入序列长度为 1,000 个 token,输出序列长度为 100 个 token。LoRA 最大秩为 64。
在前文所述的游戏内对话应用的示例中,通过使用多 LoRA 服务,应用的范围可以扩展到同时生成剧情元素和插图,两者都是由单个提示驱动的。
用户可以输入基本的剧情创意,然后 LLM 会充实这个概念,在基本创意的基础上进行扩展,提供详细的基础剧情。然后,应用可以使用相同的模型,并通过两个不同的 LoRA 进行增强,以完善剧情并生成相应的图像。其中一个 LoRA 负责生成 Stable Diffusion 提示词,以便使用本地部署的 Stable Diffusion XL 模型创建视觉效果。同时,另一个针对剧情写作进行微调的 LoRA 可以编写出结构合理、引人入胜的叙事内容。
在这种情况下,两次推理均使用相同的模型,这可确保推理过程所需的空间不会显著增加。第二次推理涉及文本和图像生成,采用批量推理的方式执行。这使得整个过程能够在 NVIDIA GPU 上异常快速且高效地推进。这样一来,用户便能快速迭代不同版本的剧情,轻松完善叙事和插图。
LLM 正在成为现代 AI 的一大重要组成部分。随着采用率和集成率的提升,对于功能强大、速度快、具有特定于应用的定制功能的 LLM 的需求也将与日俱增。RTX AI Toolkit 新增的多 LoRA 支持可为开发者提供强有力的全新方法来加速满足上述需求。
-
NVIDIA
+关注
关注
14文章
5731浏览量
110320 -
AI
+关注
关注
91文章
42158浏览量
303138 -
模型
+关注
关注
1文章
3879浏览量
52355
原文标题:不同凡响:NVIDIA RTX AI Toolkit 现提供多 LoRA 支持
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA RTX PRO 5000 Blackwell GPU多卡系统深度测评

NVIDIA RTX加速的计算机现可直接连接到Apple Vision Pro
NVIDIA和ComfyUI携手简化本地AI视频生成工作流

NVIDIA RTX PRO 5000 Blackwell GPU的深度评测

NVIDIA RTX PRO 4000 Blackwell GPU性能测试

NVIDIA RTX PRO 5000 72GB Blackwell GPU现已全面上市

NVIDIA RTX PRO 2000 Blackwell GPU性能测试

Lora技术应用领域
lora通信技术的特点
NVIDIA RTX PRO 4500 Blackwell GPU测试分析

NVIDIA RTX PRO 4500 Blackwell产品特性



评论