 优化TC3xx系统运行效率的策略
优化TC3xx系统运行效率的策略

目录
1.Tricore寻址模式
2.lsl链接文件Section分析
3.限定符对于代码的影响
4.小结
1.Tricore寻址模式
今天聊个好玩的事情。 之前ARM培训的时候,他们对于函数形参的先后顺序、数据类型、对齐方式等等做了介绍,详细分析了上述操作不同写法对于CPU的通用寄存器使用效率上的影响,这给我留下了一点印象,但不多。 而最近我在用ADS验英飞凌LMU、DSPR、PSRP等等访问效率时,发现了这样一行代码:
#pragma section farbss lmubss#pragma ,section,咱们都非常熟悉了,这个farbss是什么意思呢?以前做BSW还真没多大关注这个。 查看Tasking的手册,得到了一些答案,如下:
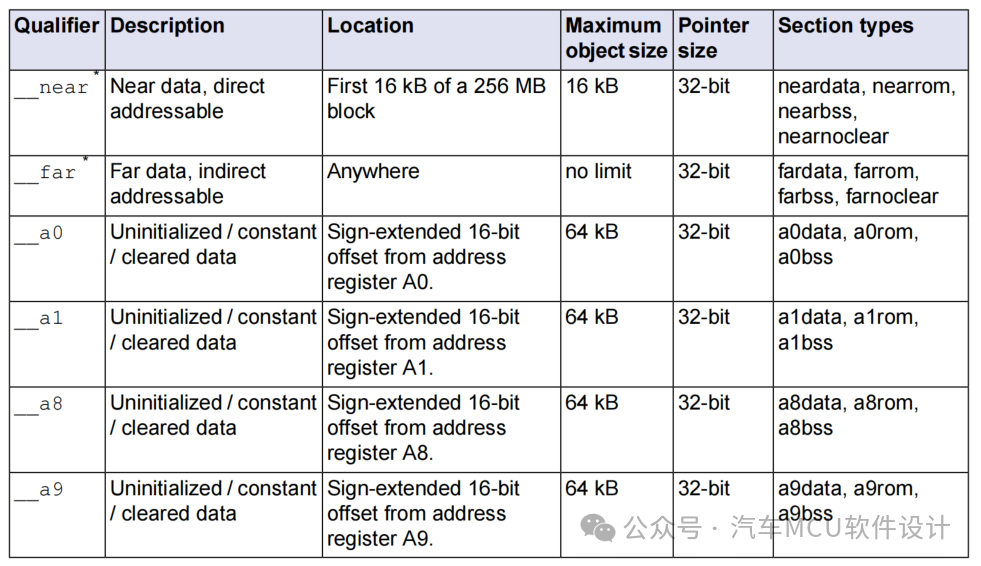
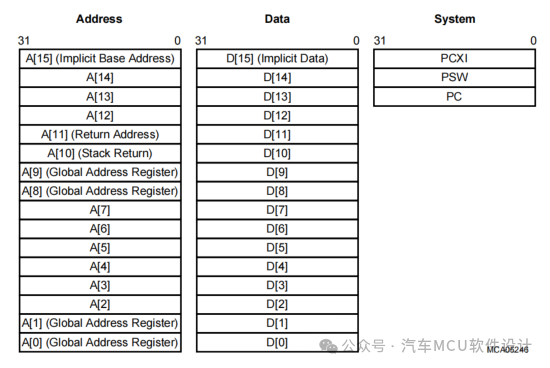


2.lsl链接文件Section分析
在ADS给的lsl模板中,可以看到关于上述限定符以及对应section type的描述,例如:
/*Near Abbsolute Addressable Data Sections*/
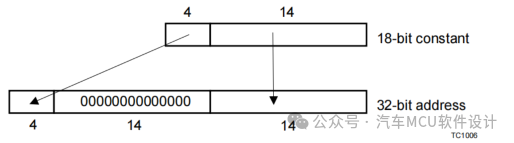
section_layout abs18
{
group
{
}
}
/*Relative A0/A1/A8/A9 Addressable Sections*/
section_layout linear
{
group
{
}
}
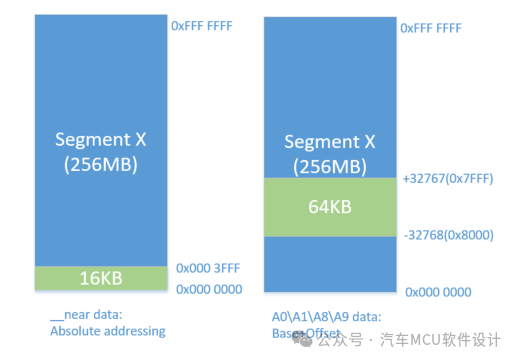
其中,abs18表示18bit绝对寻址空间,linear表示线性地址空间,如下图所示:
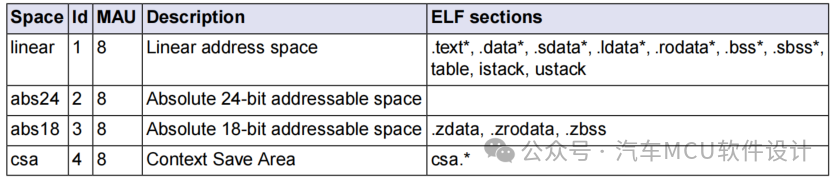
.bss:未初始化数据
.bss_a0a1a8a9:未初始化数据,用寄存器A0A1A8A9寻址
.data:已初始化数据
.data_a0a1a8a9:已初始化的数据,用寄存器A0A1A8A9寻址
.sbss:未初始化的数据,a0寻址
.sdata:已初始化的数据,a0寻址
.zbss:未初始化数据,abs18寻址
.zdata:已初始化数据,abs18寻址
我们在Cpu0_main.c里定义两个变量,不添加任何限定符,如下:

编译生成出来的map,可以看到这两个变量是放在.bss中:  对应lsl定义的Far Data Section:
对应lsl定义的Far Data Section:
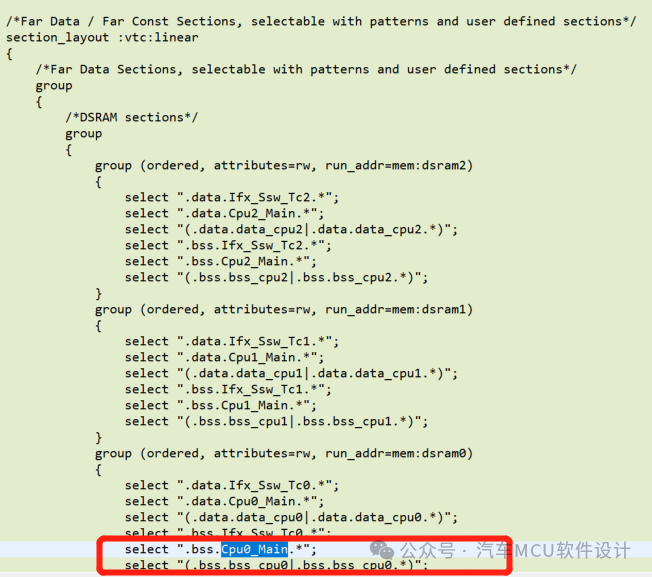
如果加上限定符__near,如下:
uint32 __near example_x ; uint32 __near example_y;
编译出来发现已经放到了zbss段

ltc E121: relocation error in "task1": relocation value 0x50000000, type R_TRICORE_16SM, offset 0x34, section ".text.Cpu0_Main.core0_main" at address 0x800023bc is not within a 16-bit signed range from the value of A0 as defined by the symbol _SMALL_DATA_
这就意味着,如果要使用寄存器+偏移寻址的方式,那么就必须是A0A1...寄存器中内容上下偏移±32KB,例如,当A0寄存器里内容为0xD0018000时,那么通过A0寄存器寻址的所有变量就应该在0xD0010000 - 0xD001FFFF。这个场景后面构建了我们再讨论,但至少我们确定了利用寄存器+偏移的方式多用于局部变量访问。
3.限定符对于代码的影响
第二节我们发现了利用不同限定符将变量发到不同的section里,但是变量的地址始终没有变化,那这到底有什么用呢? 编译出来的C代码最终会以汇编形式展示给机器,因此我们来看看不同限定符下对于代码的影响。 1)添加__near限定符,编译得到的结构,代码如下:
uint32 __near example_x ;
uint32 __near example_y;
void main(void)
{
example_x = 3;
example_y=example_x+2;
}
得到汇编代码如下
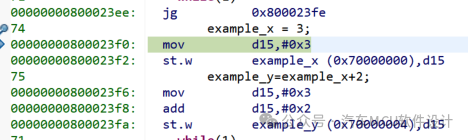
将立即数3赋给寄存器D15
D15的值直接赋给变量(x)
立即数3赋给寄存器D15
D15和2相加
将D15的值直接赋给变量(y)
统计拢共5条指令完成x=3,y=x+2这个操作; 2)添加__far限定符,得到如下
uint32 __far example_x ;
uint32 __far example_y;
void main(void)
{
example_x = 3;
example_y=example_x+2;
}
汇编代码如下:
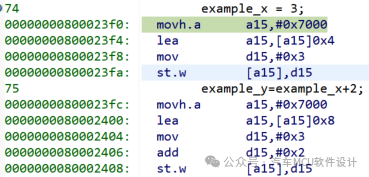
x的赋值:
将0x7000给到地址寄存器A15高16bit,低位补0,这时候A15 = 0x70000000
加载有效地址到A15,因为x地址为0x70000004,故A15 = 0x70000004
将数据3移至D15;
将D15赋给A15指向的地址
y的赋值
将0x7000给到地址寄存器A15高16bit,低位补0,这时候A15 = 0x70000000
加载有效地址到A15,因为y地址为0x70000008,故A15 = 0x70000008
将数据3移至D15,并加2;
将D15赋给A15指向的地址
总计9条指令,咋一看仅仅节省了4条指令,但从统计角度来看,效率提升了44.44%,Flash消耗更少了。 同样两行C代码,仅仅因为寻址方式的不同,汇编指令差异如此之大 ,从而影响系统运行效率。
4.小结
现在MCU的性能越来越强大,导致我在使用上越来越随意,对于这种特别底层的知识非常匮乏,直到遇到了系统优化问题,才会去从这些角度来考虑。总结下来,在系统性能优化时要注意:
构建memory限定符使用场景以优化代码执行效率;
多使用靠近CPU的memory,例如ARM TCM、Tricore DSPR、PSPR;
通过调试汇编代码,也更进一步了解了Tricore内核的运行原理;接下来,思考如何将这些理论引入到工程代码中。
-
寄存器
+关注
关注
31文章
5619浏览量
130422 -
效率
+关注
关注
0文章
151浏览量
20935 -
TriCore
+关注
关注
0文章
15浏览量
12108
原文标题:TC3xx分析--如何提高系统运行效率
文章出处:【微信号:eng2mot,微信公众号:汽车ECU开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
跳线架在数据中心的应用与优化策略
基于载波优化的云台马达驱动板控制策略
AURIX™ TC3xx 电机控制电源板:设计解析与特性洞察
英飞凌AURIX™ TC3xx安全应用套件快速上手
CW32 MCU在高频率运行下的系统稳定性的提升方案
通过优化代码来提高MCU运行效率
PCIM2025论文摘要 | 针对储能系统应用(ESS)的优化驱动器设计策略



评论