 Cortex R52内核Cache的相关概念(1)
Cortex R52内核Cache的相关概念(1)

在开始阅读本系列文章之前,请先参阅《有关CR52 MPU配置说明》。因为这篇文章讲述了,cache配置所涉及到的寄存器的设置和MPU的一些基本概念。如果读者都已经理解了上述内容,可以跳过。本章内容主要讲述cache属性的具体含意、注意事项、以及在RZ/T2M的性能测试。
RZ/T2M cache的相关说明
RZ/T2M用的Cortex-r52内核芯片做了一级Cache支持,Cache又分数据缓存D-Cache和指令缓存I-Cache,RZ/T2M cpu0的数据缓存和指令缓存大小都是16KB,cpu1的数据缓存和指令缓存大小都是32KB。对于指令缓存,用户不必过于关注,对于有执行效率要求的代码,尽量放在TCM或者使能cache的SRAM区域。这里主要说的是数据缓存D-Cache。如果Rzt2m主频是400MHz,TCM和Cache都以400MHz工作,但是如果主频是800MHz,那么TCM必须有一个指令周期的等待。也就是说TCM的工作频最高就是400MHz,而cache的工作频与CPU主频一致。
这就是为什么当用户代码比较小的时候,如果代码放在SRAM,但是代码又大部分被cache缓存了,在CPU的主频是800MHz的情况下,此时代码的执行效率高于TCM的原因。因为cache可以达到800MHz的主频,而TCM只能达到400MHz。如果CPU主频是400MHz,在代码很小的情况下,TCM的性能与SRAM的性能几乎相当。但是用户代码很大又比较复杂的时候,远超过16KB的缓存大小时,这就要看具体情况另当别论了。
TCM不是本章内容的重点,本章内容重点是SRAM的cache的说明。T2/N2 SRAM的总线频是200MHz。数据缓存D-Cache就是为了CPU加速访问SRAM。如果每次CPU要读写SRAM区的数据,都能够在Cache里面进行,自然是最好的,实现了200MHz到400MHz的飞跃,实际是做不到的,因为数据Cache大小是有限的,总有用完的时候。
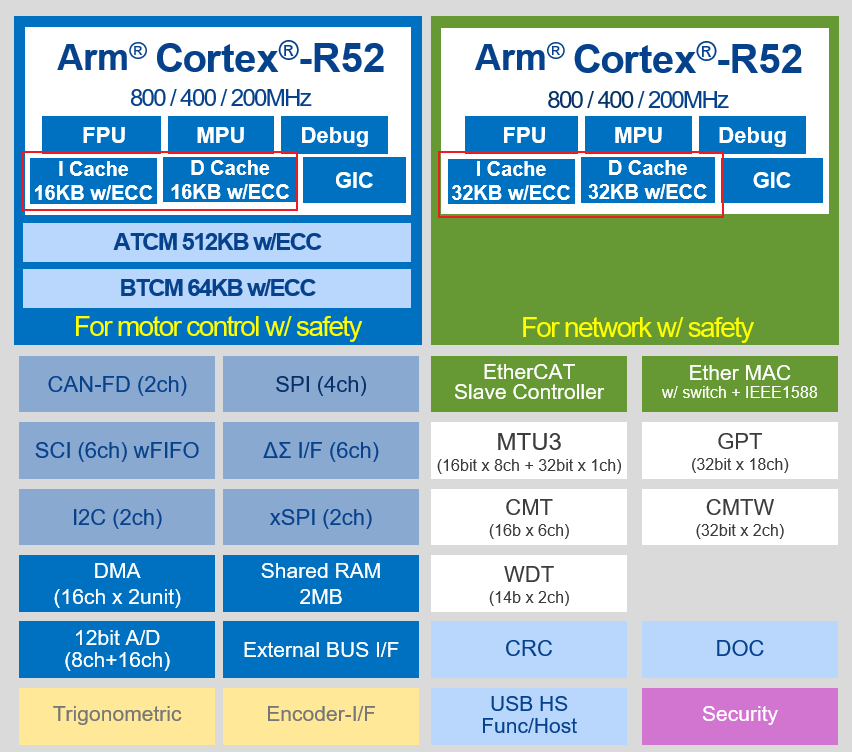
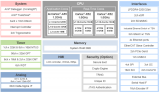
RZ/T2M系统框图
Cache相关概念
对际cache的操作主要分读写两种情况:
1Read操作
如果CPU要读取的SRAM区域的数据在Cache中已经加载好了,这就叫读命中(Cache hit)。读命中的情况下,自然效率是高的。但是如果cache里面没有,这就是所谓的cache miss,那么就要从SRAM里面加载,然后再读取。
2Write操作
如果CPU要写的SRAM区域数据在cache中已经开辟了对应的区域,这就叫写命中,如果Cache里面没有开辟对应的区域,这就是写cache miss了。
Cache的配置是通过MPU来设置的,通常用到以下几种方式:
左右滑动查看完整内容

长按可保存查看大图
对上述的几种方式说明一下:
1Normal Memory
通常我们用的块存储设备,可读,可写或者只读。
2Device
这通常用于外围设备,这些外围设备可能对读敏感或对写敏感。这个Arm体系结构限制了对设备内存的访问的排序、合并或推测。比如FPGA,这里的排序,合并和推测请看下表的解释。内容不在本章展开说明。下表对GRE,nGRE,nGnRE…等概念都有具体说明,相关的GRE的属性也都有说明。

点击可查看大图
-
内核
+关注
关注
4文章
1479浏览量
43142 -
瑞萨
+关注
关注
38文章
22542浏览量
91691 -
Cortex
+关注
关注
2文章
220浏览量
49069
发布评论请先 登录
如何实现工业伺服系统应用中实时性能的可视化与评估

安森美NPN小信号达林顿晶体管BSP52T1G、BSP52T3G、SBSP52T1G介绍
米尔RZ/T2H MPU支持支持多轴实时控制,助力工业以太网
极海Cortex-M52内核MCU G32R501在CoreMark的表现如何

【ESP32-C2系列】WT018684-S1/S1U模组规格书

【ESP32-C2系列】WT018684-S1/S1U模组产品介绍
最小化ARM Cortex-M CPU功耗的方法与技巧分享
Cortex-M内核中的精确延时的方法
AM2632-Q1汽车双核 Arm® Cortex-R5F® MCU技术手册
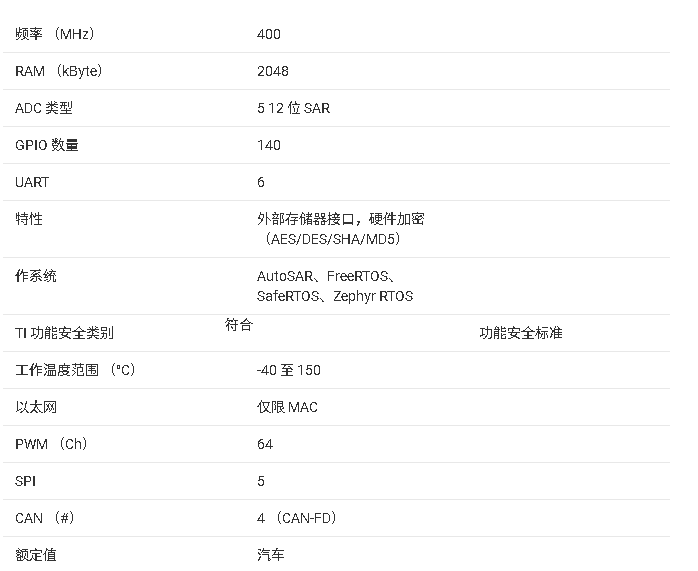
AM2631单核 Arm® Cortex-R5F® MCU技术手册
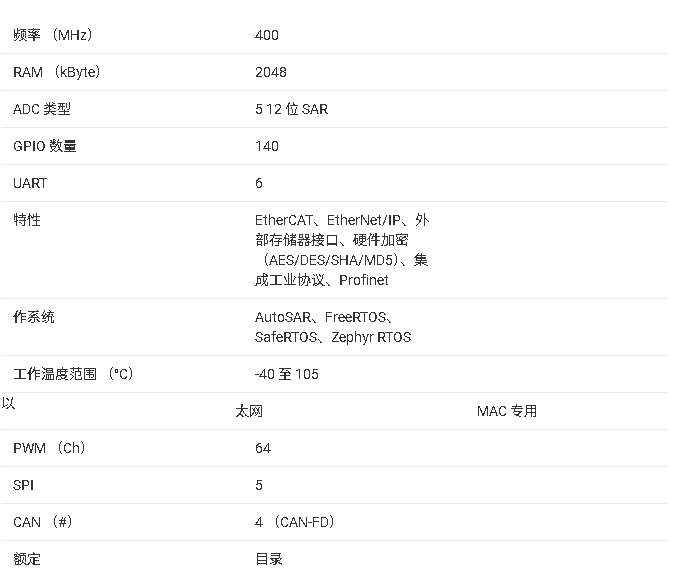
AM263P2-Q1 汽车双核 Arm® Cortex-R5F® MCU技术手册

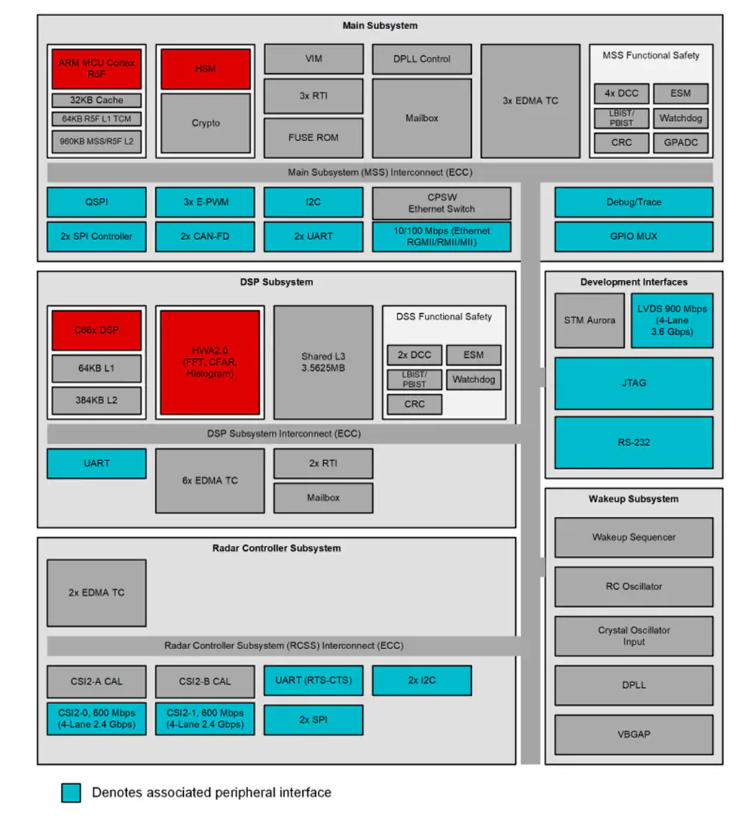
基于ARM Cortex-R5F和C66x DSP的AM273x微控制器技术解析
WHIS与高通达成战略合作
瑞萨RZ T2H更换DDR流程和工具介绍
在IAR Embedded Workbench for Arm中使用Arm Cortex-R52 NEON



评论