 国产GPU可替代!摩尔线程千卡集群点亮新成就
国产GPU可替代!摩尔线程千卡集群点亮新成就

摩尔线程、无问芯穹联合宣布,双方已经正式完成MT-infini-3B 3B(30亿参数)规模大模型的实训,基于摩尔线程国产全功能GPU MTT S4000组成的千卡集群,以及无问芯穹的AIStudio PaaS平台。
本次实训充分验证了夸娥千卡智算集群在大模型训练场景下的可靠性,同时也在行业内率先开启了国产大语言模型与国产GPU千卡智算集群深度合作的新范式。
据悉,这次的MT-infini-3B模型训练总共用时13.2天,全程稳定无中断,集群训练稳定性达到100%,千卡训练和单机相比扩展效率超过90%。
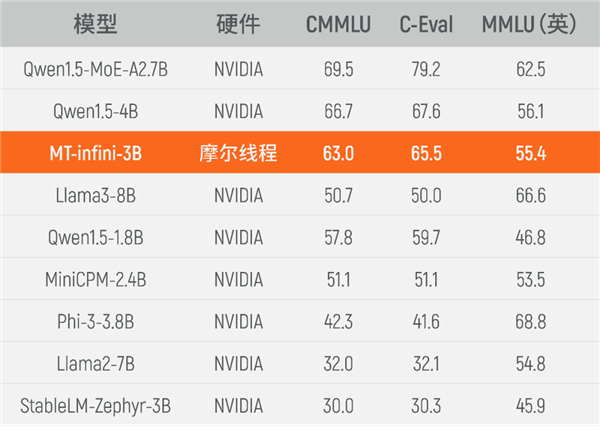
目前,实训出来的MT-infini-3B性能在同规模模型中跻身前列,相比在国际主流硬件上(尤其是NVIDIA)训练而成的其他模型,在C-Eval、MMLU、CMMLU等3个测试集上均实现性能领先。
无问芯穹正在打造“M种模型”和“N种芯片”之间的“M x N”中间层产品,实现多种大模型算法在多元芯片上的高效、统一部署,已与摩尔线程达成深度战略合作。
摩尔线程是第一家接入无问芯穹并进行千卡级别大模型训练的国产GPU公司,夸娥千卡集群已与无穹Infini-AI顺利完成系统级融合适配,完成LLama2 700亿参数大模型的训练测试。
T-infini-3B的训练,则是行业内首次实现基于国产GPU芯片从0到1的端到端大模型实训案例。
就在日前,基于摩尔线程的夸娥千卡集群,憨猴集团也成功完成了7B、34B、70B不同参数量级的大模型分布式训练,双方还达成战略合作。
经双方共同严苛测试,兼容适配程度高,训练效率达到预期,精度符合要求,整个训练过程持续稳定。
-
GPU芯片
+关注
关注
1文章
308浏览量
6589 -
摩尔线程
+关注
关注
2文章
301浏览量
6702 -
大模型
+关注
关注
2文章
3902浏览量
5331
原文标题:国产GPU可替代!摩尔线程千卡集群点亮新成就
文章出处:【微信号:hdworld16,微信公众号:硬件世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
摩尔线程与光轮智能正式达成战略合作
摩尔线程营收暴涨243%:国产GPU如何点燃算力革命的“中国芯”?
摩尔线程正式开源MuJoCo Warp MUSA

摩尔线程深耕国产算力生态,共促科技和产业融合创新

国内首个国产AI推理千卡集群落地,采用云天励飞全自研AI推理芯片
摩尔线程正式开源TileLang-MUSA项目
全栈国产AI Coding上线:摩尔线程+硅基流动+智谱,强强联合!

国产算力首证具身大脑模型训练实力:摩尔线程联合智源研究院完成RoboBrain 2.5全流程训练

墨芯人工智能千卡集群正式签约入驻新疆算力中心
算力即国力!摩尔线程架构/芯片/超节点/万卡集群四连发,助力打造AI国之重器

摩尔线程公布全功能GPU架构路线图:以“花港”新架构与万卡训练集群,开启自主算力新时代

摩尔线程新一代GPU架构即将揭晓
摩尔线程高开468% 中一签赚27万 国产GPU第一股摩尔线程高开468%

摩尔线程副总裁王华:AI工厂全栈技术重构算力基建,开启国产 GPU 黄金时代

摩尔线程吴庆详解 MUSA 软件栈:以技术创新释放 KUAE 集群潜能,引领 GPU 计算新高度




评论