 为什么说GPU再火,AI平台也少不了强力的CPU?
为什么说GPU再火,AI平台也少不了强力的CPU?

AIGC的这把火,燃起来的可不只是百模大战的热度和雨后春笋般的各式AI应用。
更是由于算力与通信需求的爆发式增长,使得底层的专用加速芯片、以及配备这些芯片的AI加速服务器再次被拉到了大众的聚光灯下。
据统计,2023年全球范围内的AI服务器市场规模已经达到了211亿美元,并且IDC还发布预测说:
预计2025年达317.9亿美元,2023-2025年CAGR为22.7%。
AIGC大模型的训练和推理需要大量的高性能算力支持,对AI服务器需求还将提升。
而且AI加速服务器不同于普通服务器,在架构上一般采用异构的方式,且GPU的数量更是能配多少就配多少,这也就是造成目前GPU千金难求的因素之一。
但你知道吗?即使在大模型时代GPU或各式AI加速芯片的光芒变得更加耀眼,但对于AI基础设施来说,CPU依然是必不可少的存在——至少一台高端的AI加速服务器中每8个GPU就需得搭配2个CPU。
不仅如此,由于AI加速服务器异构的特点,市场上除了CPU+GPU的组合方式之外,还有其它多种多样的架构,例如:
CPU+FPGA CPU+TPU CPU+ASIC CPU+多种加速卡
不难看出,即使AI加速服务器架构的组合方式万般变化,唯独不能变的就是CPU,而且往往还得是搭配高端的那种。
那么为什么会这样呢?
AI加速服务器中的CPU
首先,CPU对于AI加速服务器来说相当于人的大脑。
它可以负责整个服务器的运算与控制,是直接影响到服务器整体性能的核心部件。
CPU处理操作系统的指令,协调各个硬件组件的工作,包括内存管理、数据流控制和I/O操作。
即使在AI服务器中,GPU或其他加速器负责执行大部分计算密集型任务,CPU仍然是不可或缺的,因为它确保了整个系统的稳定运行、各组件的高效通信协作,最终推进任务的顺利执行。
其次,CPU还具备灵活性和通用性。
CPU的设计一般为通用处理器,能够执行各种类型的计算任务。
虽然GPU在并行处理方面更为高效,但CPU在处理序列化任务、执行复杂逻辑和运行通用应用程序方面更为灵活。
真正完整的AI应用平台其实需要处理一系列密切相关又特色各异的任务,包括数据预处理、模型训练、推理和后处理等,这些任务也可能甚至特别需要CPU的通用处理能力。
不仅如此,CPU还是系统启动和维护的关键点。
因为服务器的启动过程、系统监控、故障诊断和维护操作都需要CPU来执行;没有CPU,这些关键的系统级任务将无法进行。
而且CPU在软件兼容性方面更是有积累多年的优势。
市面上大多数软件和应用程序都是为CPU设计的,包括操作系统、数据库管理系统和开发工具。AI加速服务器需要运行这些软件来支持AI应用的开发和部署。
也正如我们刚才所说,现在AI加速服务器均是采用异构的形式,CPU在此过程中可以作为控制节点,管理GPU或其他加速器的计算任务,以此来实现高效的资源分配和任务调度。
最后,便是成本的问题。
虽然GPU在AI计算中非常高效,但CPU或其他专用加速芯片仍然是成本效益较高的选择,特别是在处理不适合GPU或加速器的任务时。CPU和它们的组合可以提供更佳的性能和成本平衡。
这也就不难理解为什么AI加速服务器里唯独不能缺少CPU了。
那么接下来的一个问题便是,主流的服务器厂商都在用什么样的CPU。
我们以国内AI加速服务器市场份额排第一的浪潮为例,从最新消息来看,其NE5260G7服务器便已经适配了老牌芯片巨头英特尔最新发布的第五代英特尔 至强 可扩展处理器。
而之所以浪潮要适配最新的高端CPU,可以理解为“高端的游戏需要搭配高端GPU和CPU”,AI服务器要想在性能上取得新突破,同样也是要适配高端的硬件。
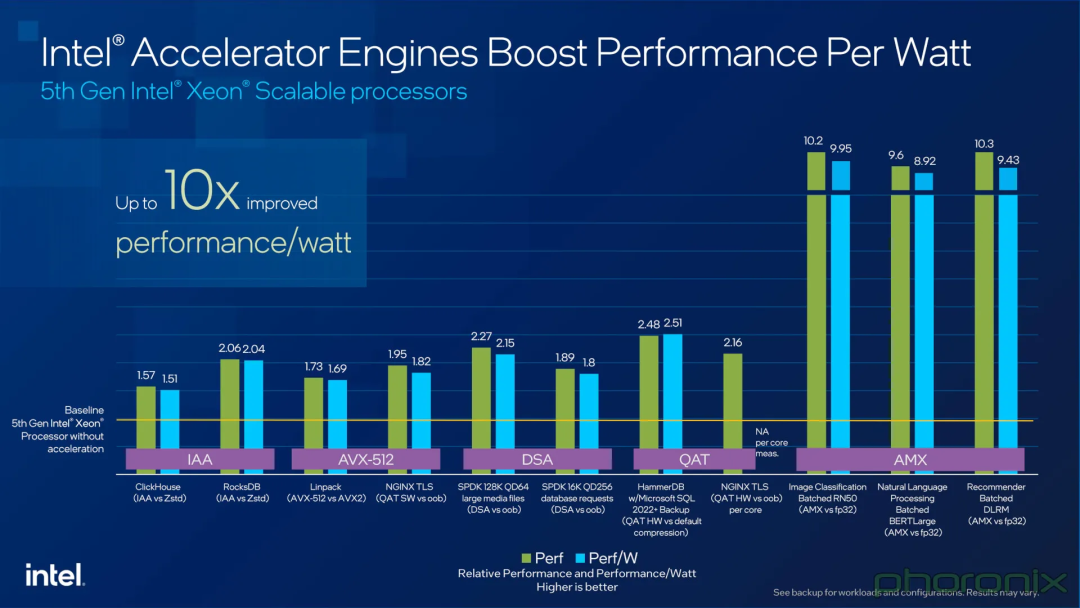
具体而言,与前一代相比,第五代英特尔 至强 可扩展处理器在处理人工智能工作负载方面表现出色,其性能提升了21%,特别是在AI推理任务上,性能增幅更是达到了42%。
此外,它的内存带宽也增加了16%;在执行一般计算任务时,第五代至强 可扩展处理器能够将整体性能提高至多21%,并且在多个客户实际工作负载中实现了每瓦特功耗性能提升高达36%。
也正因“内核”如此强悍,才使得浪潮的服务器在性能上实现了平均21%的提升。
不过有一说一,毕竟AI也不完全就是单纯的模型或大模型的加速,因此上述的CPU优势也还仅是能力的一隅,在各个细分的应用场景中,它还有更大的作为。
AI不完全是大模型
即使在配备了GPU或专用加速器的AI服务器中,CPU的角色也远不止于主控或为加速器提供服务。
而是在AI系统的整个生命周期中扮演着多样化的角色,贯穿从数据采集、预处理、训练、推理、应用等全流程。
先说最关键的AI模型,尤其是模型推理这一环节。
不论是现在占据最强话题热度的大语言模型,还是传统的深度学习模型,抑或是科学计算与人工智能交融形成的AI for Science应用,CPU,特别是内置AI加速能力的英特尔 至强 可扩展处理器,都在推理应用中有不俗战绩。
例如在AlphaFold2掀起的蛋白质折叠预测热潮之中,借助第三代和第四代至强 可扩展处理器不断优化端到端通量能力,就能实现比GPU更具性价比的加速方案,直接拉低AI for Science的入场门槛。

再例如OCR技术应用,也随着至强 可扩展处理器在内置AI加速技术上的演进,被赋予了新的“灵魂”,不但准确率飙升、响应延迟也进一步降低。
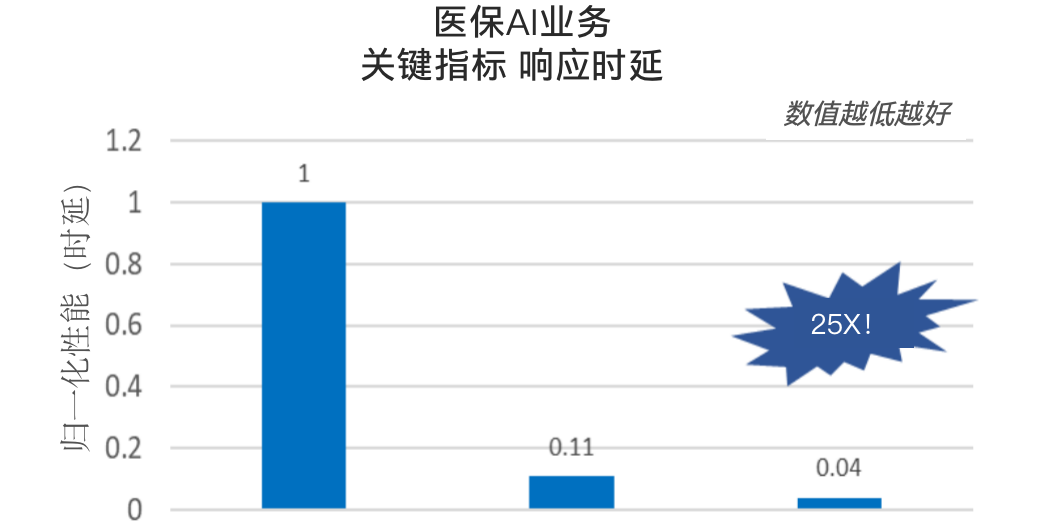
更别提以ChatGLM为代表的通用大模型,以及卫宁、惠每等行业软件或解决方案提供商输出的行业特定场景的大模型应用,它们都提供了有力的实践佐证,能验证至强 在大模型推理上的实力,以及相比加速器芯片更优的成本,以及更易获取,更易部署、优化和使用的优势。
不信你就瞧瞧我们的最“In”AI专区 ,来刷新一下认知。
再说AI全流程中大量涉及数据处理的环节。
实际业务中的AI应用,背后往往需要包含大量数据的知识库作为支撑。
这些数据通过将海量文本语料压缩成密集向量的形式存储,并通过高效的相似度搜索迅速找到与查询最相关的信息,也就是大家所熟知的向量数据库了。
在这方面,专门针对向量和矩阵计算优化的英特尔 AVX-512指令集和英特尔 AMX加速技术有了用武之地,可应对海量、多维向量数据的高并发和实时计算等挑战。
业界知名的向量数据库开发商如腾讯云和星环科技等,底层都选择第五代英特尔 至强 可扩展处理器作为承载和加速的平台。
腾讯云VectorDB与英特尔合作,在第五代至强 平台经软硬件双方面优化后,在提升向量数据库的向量检索效率方面相比基准组提升了约2.3倍,在使用英特尔 AMX 加速数据格式为INT8的测试场景中再次性能提升达约5.8倍。
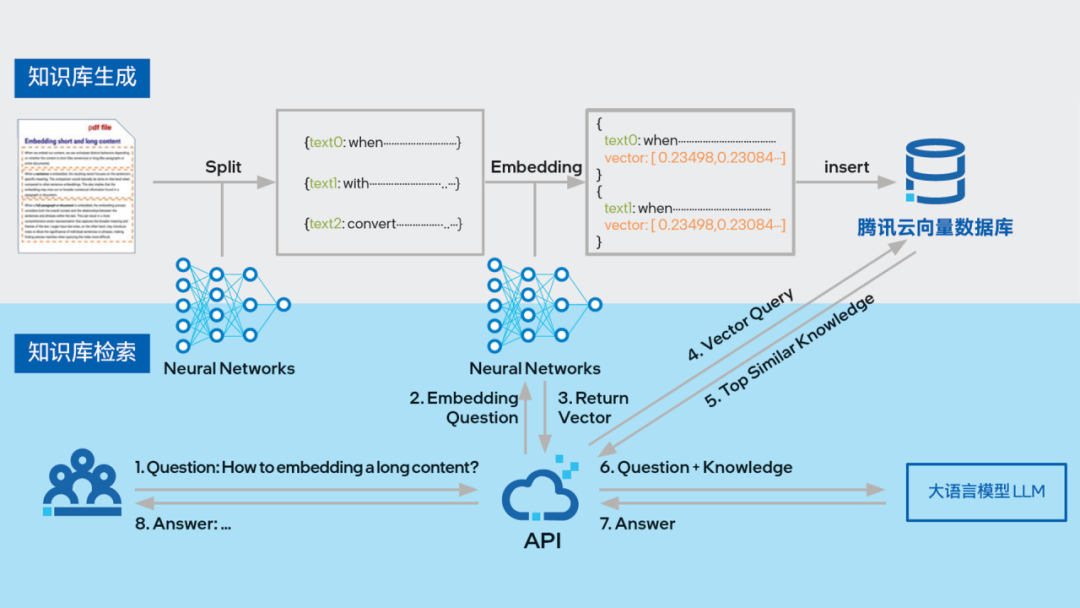
星环科技则基于第五代至强 可扩展处理器推出了Transwarp Hippo 分布式向量数据库解决方案,实现了约2倍的代际性能提升,可有效满足大模型时代海量、高维向量的存储和计算需求。

△ 图:星环科技分布向量数据库Transwarp Hippo产品架构
AI全流程中与数据相关的环节,不止包含可用作大模型外部知识库的向量数据库这一种。还涉及模型训练前数据预处理,训练中的数据调度,模型上线后的持续优化和维护、异常数据的发现和处理等。
众所周知,数据是AI三要素之一,相当于AI的血液和原料,没有优质的数据,再先进的算法和模型也是空中楼阁。但原始数据往往参差不齐,需要通过数据清洗、转换、特征工程等一系列流程,最终才能为AI系统所用。
这些数据处理任务涉及海量逻辑运算,以及同样、甚至更大量级的内存操作,如存取、传输,对处理速度和时延要求都非常高,因此通常也是由最离系统内存最近、更擅长通用计算的CPU来承担。
第五代英特尔 至强 可扩展处理器充分考虑到这些需求,内置多款加速器来为数据处理提供支持,如:
DSA数据流加速器(Data Streaming Accelerator):负责优化数据复制和转换操作,提高网络和存储性能。 IAA存内分析加速器 (In-Memory Analytics Accelerator):提高分析性能,同时卸载CPU内核任务以加速数据库查询吞吐量等工作负载。 QAT数据保护与压缩加速技术(QuickAssist Technology):可显著加速数据压缩、对称和非对称数据加密解密,提高CPU效率和整体系统性能。 DLB动态负载均衡器(Dynamic Load Balancer),帮助防止性能瓶颈并实现低时延控制平面工作负载。
在第五代至强 可扩展处理器的不同细分型号中,对上述加速器有灵活的配置或支持方案,并且还支持通过Intel On Demand按需启用,可以适应不同工作负载的需求。
最后,还特别要提到的对数据隐私、模型和应用安全的更优防护,毕竟所有AI场景都不能以牺牲安全为代价,更是有些AI应用场景对此格外在意,如在金融、医疗行业。
对这些行业场景来说,能用上基于CPU实现的硬件级可信执行环境(TEE)技术来保护敏感数据和代码免受攻击可是非常关键的。
如平安科技,就曾使用英特尔 Software Guard Extensions(英特尔 SGX)构建联邦学习解决方案。
平安科技通过英特尔 SGX的“飞地”内存区域,在本地安全地执行模型训练,而无需共享原始数据。同时SGX支持安全的多方计算协议,如同态加密、安全聚合等,从而在联邦学习中实现了更优的隐私保护。
阿里云则基于最新第五代英特尔 至强 可扩展处理器推出了BigDL-LLM 隐私保护方案。
它在这款全新处理器内置的英特尔 Trust Domain Extension (英特尔 TDX)技术的加持下实现了对分布式节点或 AI管道的更优防护,从而能让客户在不牺牲数据隐私的前提下将更多数据运用到 AI 应用中,有效挖掘数据价值,为客户构建更为高效的隐私保护机器学习方案,助力大模型的广泛应用。
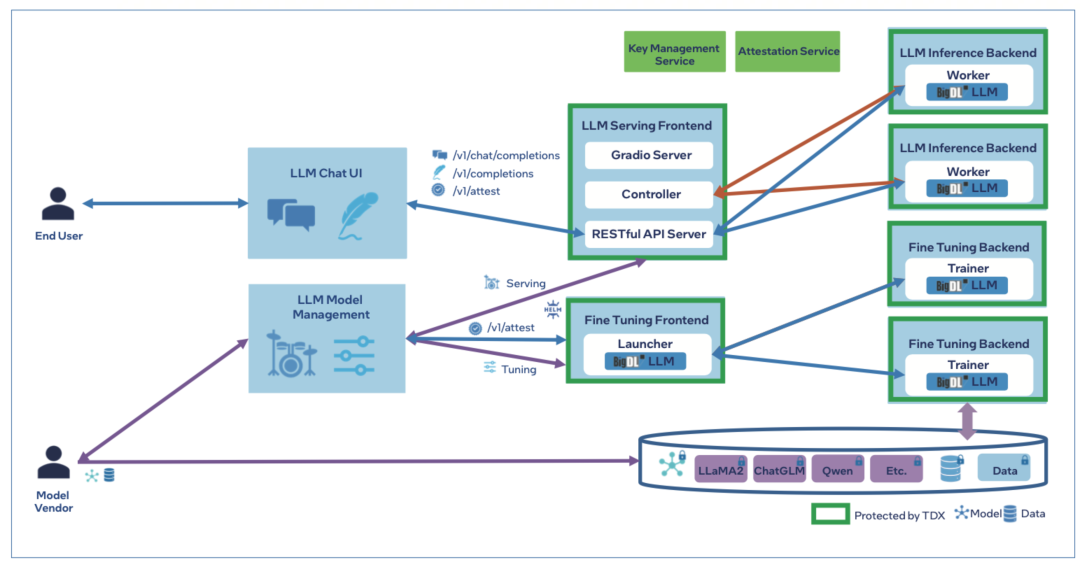
△ 图:采用英特尔 TDX的BigDL-LLM服务和调优架构
要知道,基于 TEE 的联邦学习或隐私保护机器学习技术,可是未来AI在大规模实践中打通和共享多机构数据的一大基座。
通过这种技术,不同机构之间才能在保证数据安全和隐私的前提下,实现数据的共享和联合分析,才能为 AI 的持续发展演进提供更加丰富和全面的数据支持。
搞好AI全流程加速
CPU不能是短板
所以,让我们从单纯的模型加速,将眼界扩展到更全面、多维、流水线化的AI平台应用,不难预见,随着这种平台级应用的成熟与走向实战,我们对小到AI加速服务器,大到AI基础设施的期望也在不断拓展和升级。
仅仅关注AI模型本身以及GPU、专用加速器的性能,会越来越像一个单点化的思维。
未来大家必须更重视整个AI平台中多种硬件与软件的搭配及协同工作,这其中CPU作为主控、加速、辅助的多面手,对于补齐整个平台的短板,提升整个平台的质量至关重要。
这或许就是在如今的技术浪潮下,以第五代英特尔 至强 可扩展处理器为代表的高端CPU,依然会在AI服务器或基础设施市场中赢得一席之地的根因。
毕竟,高端CPU的作用不仅是直接上手加速AI推理,还关系到整个AI平台或系统整体性能的提升,更是提供更加稳定和安全的运行环境来拓展AI的边界,只有这几个环节都照顾到,才能推动AI Everywhere愿景进一步走向现实。
或者简言之,AI如果要真正走向更多的实用场景,又怎么能少得了更强大、更可靠、更全面多能的CPU呢?
文章转载自:量子位
作者:金磊 梦晨
审核编辑:刘清
-
处理器
+关注
关注
68文章
20332浏览量
254981 -
人工智能
+关注
关注
1820文章
50325浏览量
266951 -
GPU芯片
+关注
关注
1文章
307浏览量
6554 -
AI加速器
+关注
关注
1文章
73浏览量
9538
原文标题:最“in”AI | 为什么说GPU再火,AI平台也少不了强力的CPU
文章出处:【微信号:英特尔中国,微信公众号:英特尔中国】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
国产来袭!2nm AI GPU?
内存要取代GPU?HBM之父警告:以英伟达GPU为核心的架构要被颠覆

AI智能体推动芯片需求从GPU扩展至CPU
基于openEuler平台的CPU、GPU与FPGA异构加速实战

手把手教你打造一个专属小智AI机器人,零基础也能玩转AI创客(附详细教程资料及学习路线)

GPU不是AI的唯一解:英伟达用Groq LPU证明,推理赛道需要“另一条腿”

GPU 利用率<30%?这款开源智算云平台让算力不浪费 1%
AI硬件全景解析:CPU、GPU、NPU、TPU的差异化之路,一文看懂!

【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
从 CPU 到 GPU,渲染技术如何重塑游戏、影视与设计?

aicube的n卡gpu索引该如何添加?
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!




评论