 谷歌推出多模态VLOGGER AI
谷歌推出多模态VLOGGER AI

谷歌最新推出的VLOGGER AI技术引起了广泛关注,这项创新的多模态模型能够让静态肖像图“活”起来并“说话”。用户只需提供一张人物肖像照片和一段音频内容,VLOGGER AI就能让图片中的人物仿佛真的在朗读这段音频,面部表情丰富,栩栩如生。
VLOGGER AI作为一种专为虚拟肖像设计的多模态Diffusion模型,其强大能力得益于MENTOR数据库的丰富资源。这个数据库收录了超过80万名人物肖像,以及累计超过2200小时的影片,使得VLOGGER能够生成各种种族、年龄、穿着和姿势的肖像影片,极大增加了其适用性和实用性。
谷歌对VLOGGER AI寄予厚望,将其视为迈向“通用聊天机器人”的重要一步。未来,这种AI技术有望通过语音、手势和眼神交流等方式,以更加自然和人性化的方式与人类进行互动。
这一技术的推出不仅展示了谷歌在人工智能领域的深厚实力,也为虚拟形象、影视制作等领域带来了全新的可能性。未来,我们可以期待看到更多由VLOGGER AI生成的生动、真实的虚拟人物形象,在娱乐、教育、广告等多个领域大放异彩。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
谷歌
+关注
关注
27文章
6259浏览量
111966 -
AI
+关注
关注
91文章
41101浏览量
302576 -
模型
+关注
关注
1文章
3818浏览量
52265
发布评论请先 登录
相关推荐
热点推荐
海康威视推出森林防火多模态智能研判大模型产品
海康威视公共服务行业软件特推出森林防火多模态智能研判大模型产品,依托海康威视观澜大模型能力,对不同等级的火情分类处理,减少90%的无效告警² ,让工作人员告别反复研判的低效工作。
格灵深瞳联合氪信科技推出多模态AI金融安全一体机
12月26日,AI赋能千行百业超级联赛“A超之夜”在广西大学举行。自治区党委书记、自治区人大常委会主任陈刚出席并讲话。自治区主席韦韬出席。活动现场,格灵深瞳联合氪信科技正式发布多模态AI
涂鸦Omni AI Foundation V2.6发布:低代码+多模态,重塑AI硬件创新体验
硬件产品的落地。今天,我们非常高兴地宣布:面向多模态AI硬件的基座平台OmniAIFoundation正式发布V2.6版本。本次升级不仅显著提升了端到端多

集成端侧AI的可穿戴多模态生理参数采集设备是脑机接口家用的未来?
HUIYING集成端侧AI的可穿戴多模态生理参数采集设备系统概述随着对实时生理监测与人机交互需求的增长,传统可穿戴设备在多模态同步采集与端侧

【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片
2)渗透式AI的优势
5、大型多模态模型
多模态模型(LMM)可以被理解成大模型的更高级版本,不仅可以处理文本,还可以处理和理解多种类型的
发表于 09-18 15:31
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
“看图说话+语音问答”的融合交互。
五、结论与未来发展方向如果说 “大模型上云” 是 AI 的 “星辰大海”,那么 “多模态落地端侧” 就是 AI 的 “柴米油盐”—— 后者决定了智
发表于 09-05 17:25
商汤科技多模态通用智能战略思考
时间是最好的试金石,AI领域尤其如此。当行业热议大模型走向时,商汤早已锚定“多模态通用智能”——这是我们以深厚研究积累和实践反复验证的可行路径。
“端云+多模态”新范式:《移远通信AI大模型技术方案白皮书》正式发布
7月28日,移远通信联合智次方研究院正式发布《AI大模型技术方案白皮书》(以下简称“白皮书”)。这份白皮书系统梳理了AI大模型的技术特点、产业发展态势与多元应用场景,以及移远通信“端云+多模态

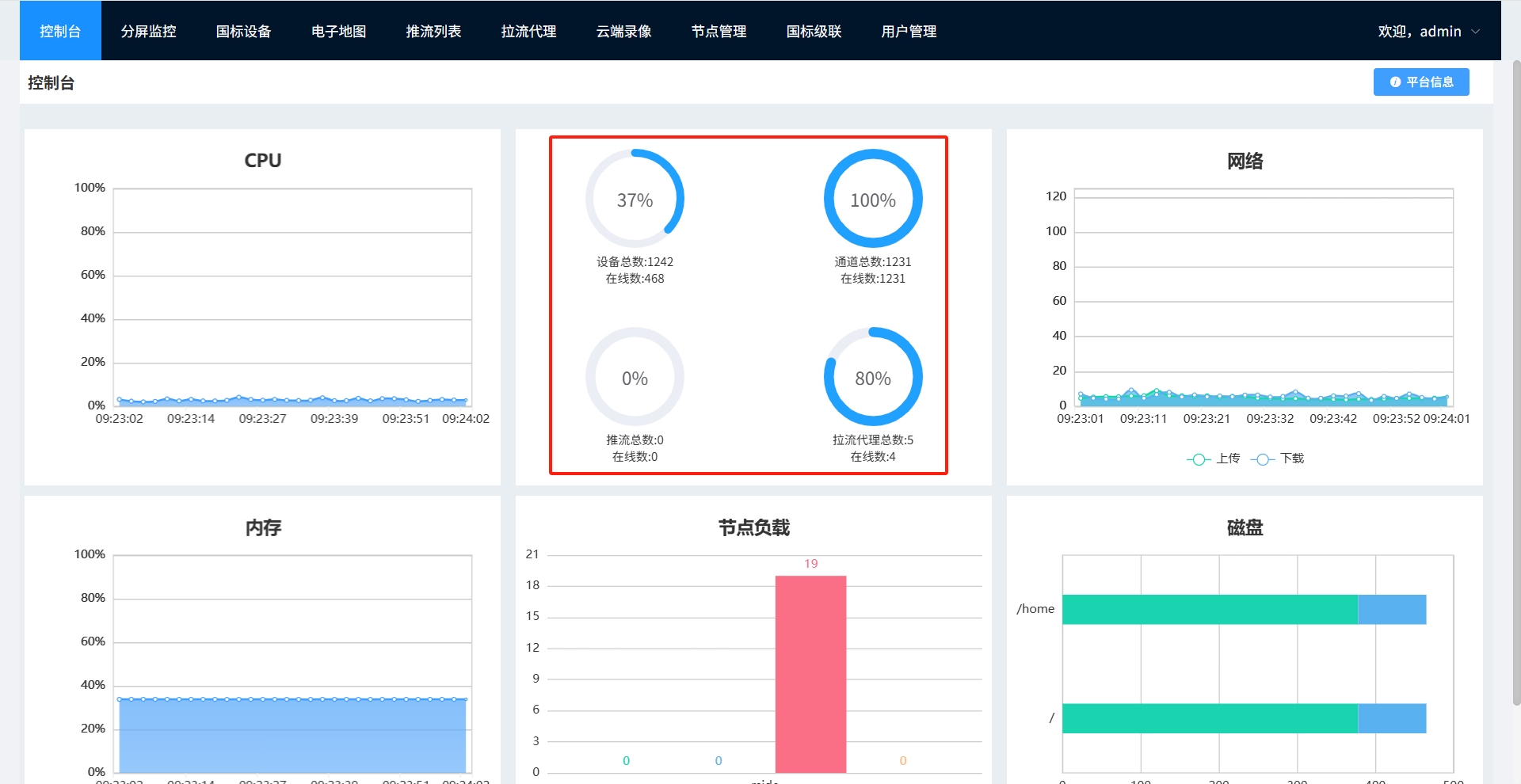
中伟视界:解密GB28181流媒体平台,多模态AI的强大支撑
GB28181流媒体平台作为多模态AI系统的基础数据枢纽,解决了多源异构视频资源的接入与处理问题,提供标准化数据格式,支持各类智能分析与应用场景。其广泛的协议兼容性和强大的视频处理能力
研华科技携手创新奇智推出多模态大模型AI一体机
这是一款基于研华高性能边缘计算平台MIC-733,深度集成创新奇智视觉小模型与多模态大模型的边缘智能终端,通过创新的“视觉识别 + 深度语义理解”融合分析路径,具备强大的本地视频智能分析及大模型深度研判能力。

百度文心快码推出AI原生开发环境工具Comate AI IDE
6月23日图灵诞辰日,Comate AI IDE正式发布,成为行业首个多模态、多智能体协同的独立AI原生开发环境工具。
NVIDIA助力图灵新讯美推出企业级多模态视觉大模型融合解决方案
中国推出企业级多模态视觉大模型融合解决方案,推动先进 AI 模型在交通治理、工业质检、金融风控等领域实现高效识别、精准预警和稳定交付。
润和软件荣登2025多模态AI大模型排行榜单
近日,《互联网周刊》联合eNET研究院、德本咨询、中国社会科学院信息化研究中心共同发布了“2025多模态AI大模型”榜单。江苏润和软件股份有限公司(以下简称“润和软件”)自主研发的“润知”知识处理




评论