 FunASR语音大模型在Arm Neoverse平台上的优化实践流程
FunASR语音大模型在Arm Neoverse平台上的优化实践流程

Arm 架构在服务器领域发展势头前景看好。目前已有许多头部云服务提供商和服务器制造商推出了基于 Arm Neoverse 平台的服务器产品,例如 AWS Graviton、阿里云的倚天 710 系列等。这些厂商提供了完整的软硬件支持和优化,使得大模型推理在基于 Arm 架构的服务器上运行更加便捷和高效。
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量的计算资源,而能效比高的 Arm 架构服务器可以提供更好的性能和效率。
Armv9 新特性提高大模型推理的计算效率
Armv9 架构引入了 SVE2 (Scalable Vector Extension,可扩展向量延伸指令集)。SVE2 是一种可扩展的向量处理技术,它允许处理器同时执行多个数据元素的操作,可以提供更高效的向量计算和人工智能 (AI) 硬件加速,从而加快了 AI 任务的执行速度,提高了能效和性能。这对于在 Arm 架构的服务器上进行大规模 AI 推理和训练任务非常有益,不论是实现更好的用户体验或是更高的计算效率。
SVE2 对 AI 推理引擎的支持有效地使用了 BFloat16 (BF16) 格式,BF16 是一种浮点数格式,它使用 16 位表示浮点数,其中 8 位用于指数部分,7 位用于尾数部分,还有 1 位用于符号位。相比于传统的 32 位浮点数格式(如 FP32),BF16 在表示范围和精度上有所减少,但仍然能够满足大多数 AI 推理任务的需求。
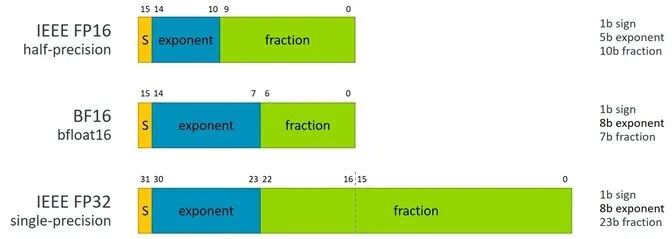
图 1:BFloat16 格式
BF16 格式可以在减少存储和带宽需求之余,同时提供足够的精度,来满足大多数 AI 推理任务的要求。由于 SVE2 提供了针对 BF16 的向量指令,可以在同一条指令中同时处理多个 BF16 数据元素,从而提高计算效率。理论上来说,采用 BF16 可以实现双倍的 FP32 的性能。
SVE2 的矩阵运算在 AI 推理中扮演着重要的角色,它可以显著提高计算效率和性能。比如矩阵乘法 (Matrix Multiplication) 是许多 AI 任务中常见的运算,如卷积运算和全连接层的计算。SVE2 的向量指令可以同时处理多个数据元素,使得矩阵乘法的计算能够以向量化的方式进行,从而提高计算效率。指令 FMMLA 可以实现 FP32 格式下两个 2x2 矩阵乘法运算,指令 BFMMLA 可以通过单指令实现 BF16 格式下 4x2 矩阵和 2x4 矩阵的乘法,UMMLA、SMMLA 等可以实现 INT8 格式下 8x2 矩阵和 2x8 矩阵的矩阵乘法运算。通过 SVE2 的硬件加速功能,AI 推理可以在 Arm 架构中获得更高效的矩阵运算执行,提高计算效率和性能。
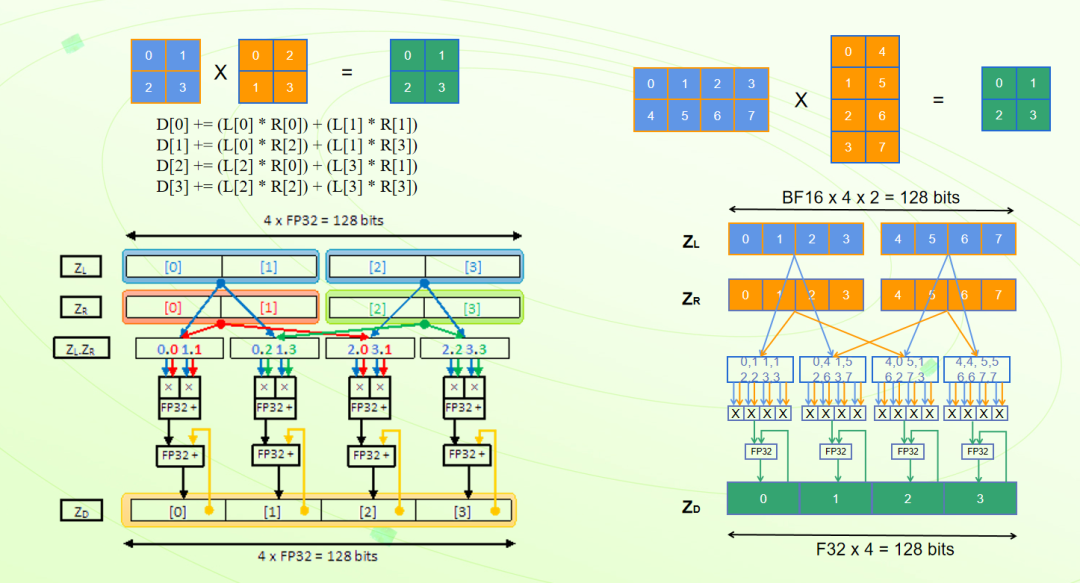
图 2:矩阵乘指令
ACL 实现 PyTorch 的计算加速
PyTorch 可以支持 Arm 架构的硬件加速资源,但需要安装适用于 Arm 架构的 PyTorch 版本,或者是从开源源代码编译支持 Arm 架构硬件加速的 PyTorch 版本。Arm Compute Library (ACL, Arm 计算库) 实现了 Arm 架构的硬件加速资源的优化封装,通过 OneDNN 来使 PyTorch 对 Arm 优化加速调用。下面介绍如何生成带 ACL 加速的 PyTorch 版本。
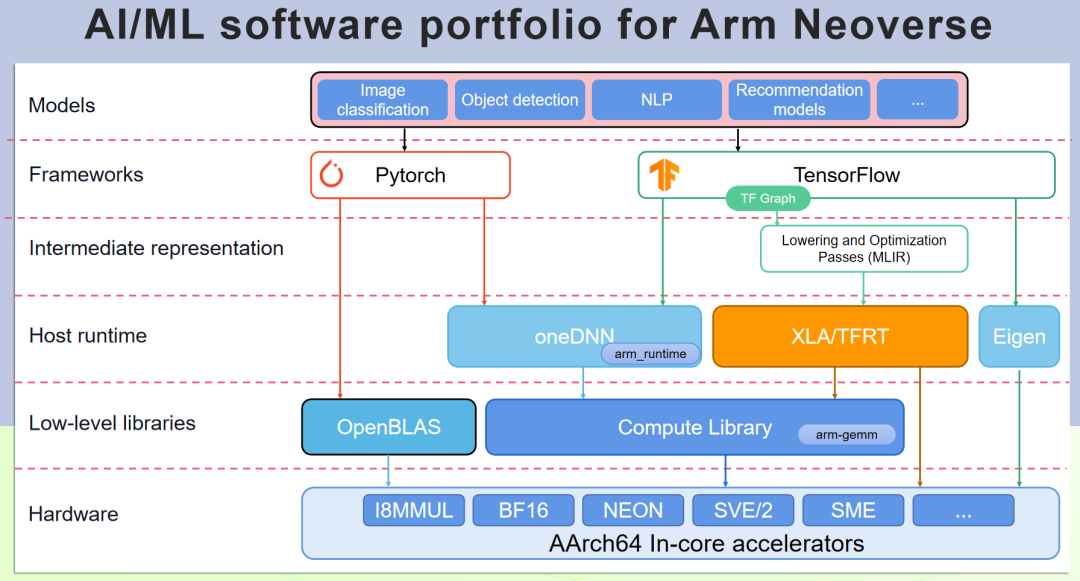
图 3:Arm Neoverse 平台 AI/ML 软件组合
ACL 是开源软件,下载后编译并设定相应的系统路径。
链接:https://github.com/arm-software/ComputeLibrary
# git clone https://github.com/ARM-software/ComputeLibrary.git
# scons arch=armv8.6-a-sve debug=0 neon=1 os=linux opencl=0 build=native -j 32 Werror=false
validation_tests=0 multi_isa=1 openmp=1 cppthreads=0 fixed_format_kernels=1
# export ACL_ROOT_DIR=/path_to_ACL/ComputeLibrary
开源软件 OpenBLAS 也实现了部分 Neon 的加速,PyTorch 同样也要依赖 OpenBLAS,下载相应源代码编译和安装。
链接:https://github.com/OpenMathLib/OpenBLAS
# git clone https://github.com/OpenMathLib/OpenBLAS.git
# cmake & make & make install
获取开源的 PyTorch 代码,下载相应的依赖开源软件,指定使能 ACL 的方法进行编译,获取 PyTorch 的安装包并更新。
# git clone https://github.com/pytorch/pytorch
# git submodule update --init –recursive
# MAX_JOBS=32 PYTORCH_BUILD_VERSION=2.1.0 PYTORCH_BUILD_NUMBER=1 OpenBLAS_HOME=/opt/openblas
BLAS="OpenBLAS" CXX_FLAGS="-O3 -mcpu=neoverse-n2 -march=armv8.4-a" USE_OPENMP=1 USE_LAPACK=1 USE_CUDA=0
USE_FBGEMM=0 USE_DISTRIBUTED=0 USE_MKLDNN=1 USE_MKLDNN_ACL=1 python setup.py bdist_wheel
# pip install --force-reinstall dist/torch-2.x.x-cp310-cp310-linux_aarch64.whl
配置了运行环境,就可以利用 Arm 架构的硬件加速资源来加速 PyTorch 的计算。尽管 PyTorch 可以在 Arm 架构上利用硬件加速资源,但针对具体模型和应用场景,需要对模型和代码进行一些调整以最大程度地发挥硬件的加速优势。
基于 FunASR 的优化实践
FunASR 是阿里巴巴达摩院开发的开源的基于 Paraformer 的大模型语音识别模型,提供包括语音识别 (ASR)、语音端点检测 (VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等在内的多种功能。本文以 FunASR 在 Arm Neoverse 平台上优化的过程做为大模型的优化实践案例。
仓库地址:https://github.com/alibaba-damo-academy/FunASR
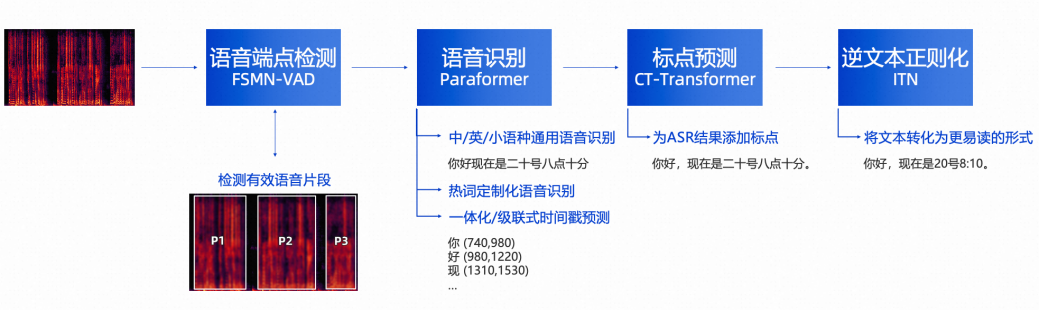
图 4:FunASR
本次优化是基于 ACL v23.08、oneDNN v3.3、PyTorch v2.1 进行,测试平台基于阿里云的 ECS 公有云,包括 C8Y、C8I、C7 等云实例。
为了确保 PyTorch 已经启动 ACL 进行加速,可以加上 “DNNL_VERBOSE=1” 来查看运行的日志输出。
# OMP_NUM_THREADS=16 DNNL_VERBOSE=1 python runtimes.py
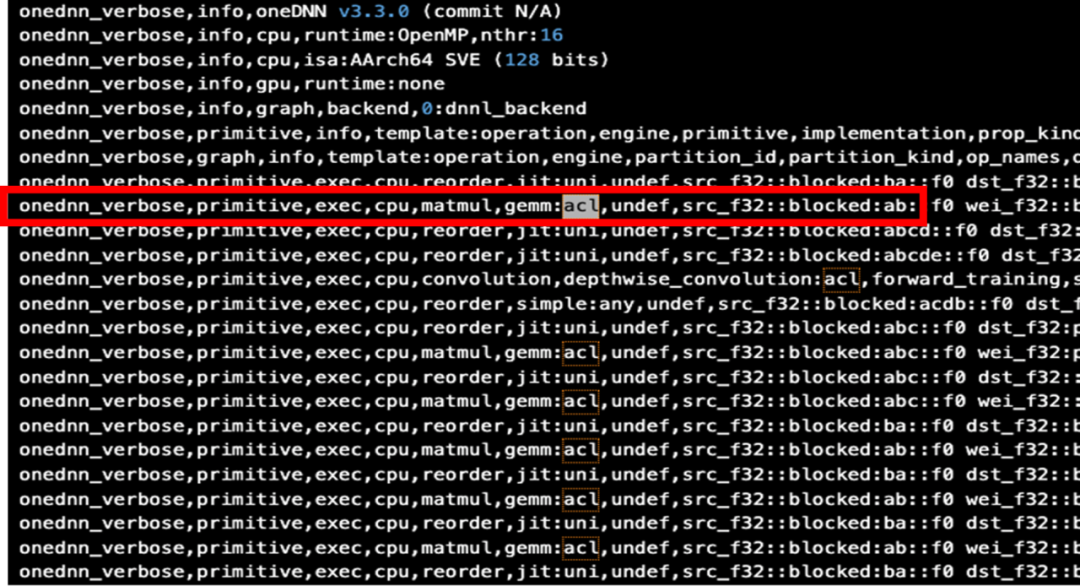
图 5:使能 ACL 的 PyTorch 运行日志
得到如上的输出结果,可以看到已经启用了 ACL。
为了使优化有明确的目标,在运行大模型时,用 PyTorch 的 profiler 做整个模型的数据统计,即在调用大模型之前加上统计操作,为了减少单次运行的统计误差,可以在多次运行之后做统计并输出统计结果,如下面的示例:

默认运行是用 FP32 的格式,如果需要指定 BF16 的格式运行,需要加上 “ONEDNN_DEFAULT_FPMATH_MODE=BF16” 的参数。
# OMP_NUM_THREADS=16 ONEDNN_DEFAULT_FPMATH_MODE=BF16 python profile.py
得到 profile 的统计数据:
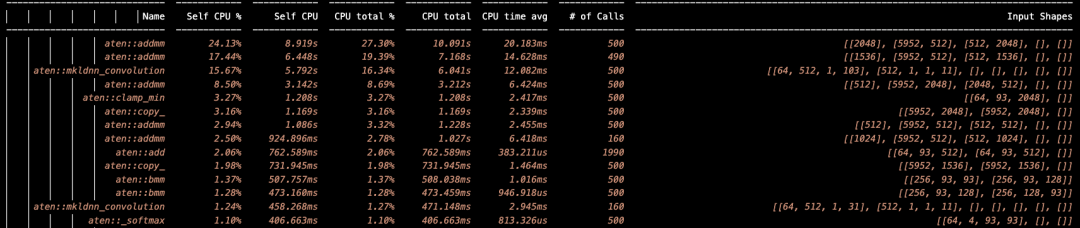
图 6:统计分析日志
分析运行的结果,找出需要优化的算子,在这个示例中,mkldnn_convolution 运行的时间显著较长。
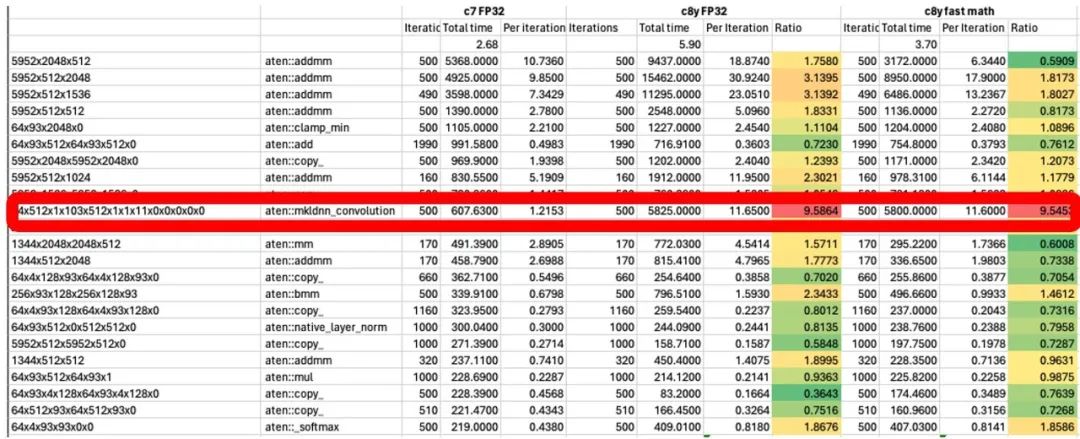
图 7:优化前统计分析
通过分析定位,发现在 OMP 的操作中,数据并没有按照多处理器进行并行数据处理,修复问题后,再次测试,发现 Convolution 的效率大大提升。
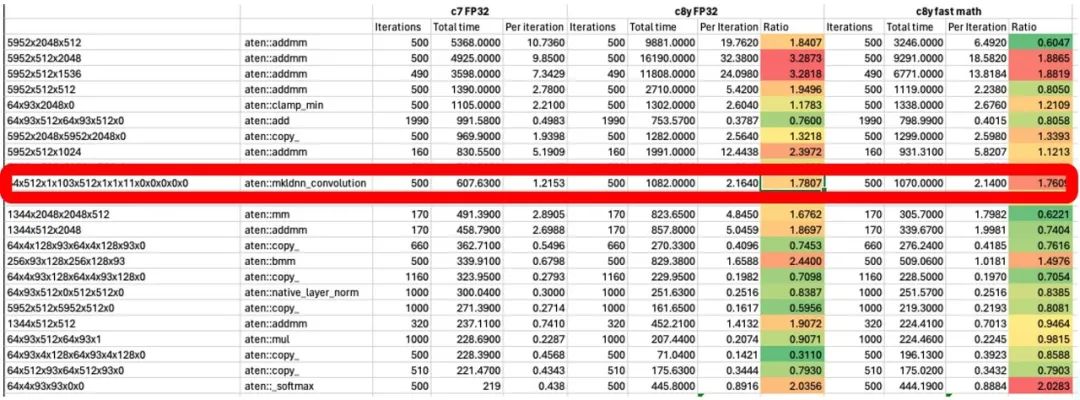
图 8:卷积优化后统计分析
在 Arm 架构处理器中,SVE2 可以对 INT8 进行并行数据处理,比如单指令周期可以做到 16 个 INT8 的乘累加操作,对 INT8 的执行效率非常高,在对模型执行效率有更高要求的场景下,可以用 INT8 来动态量化模型,进一步提高效率。当然,也可以把 INT8 和 BF16 相结合,模型用 INT8 量化,中间计算用 BF16 格式,相较其他平台,有 1.5 倍的效率提升。
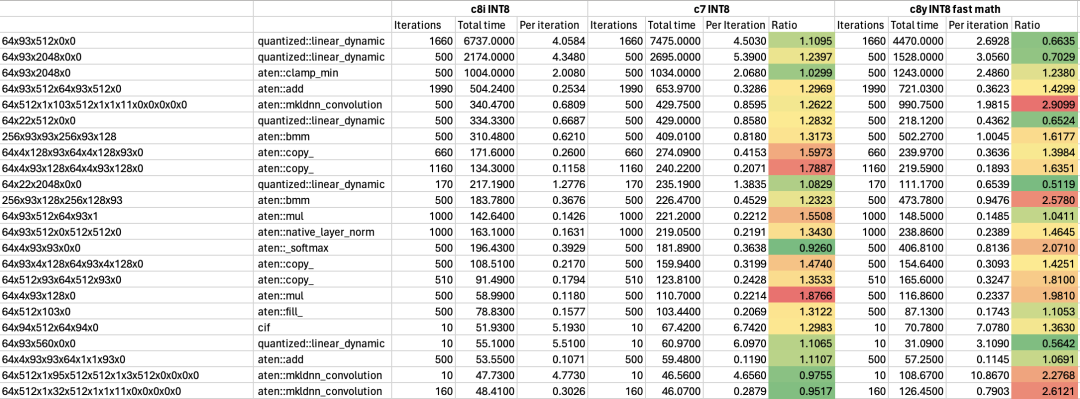
图 9:动态量化优化
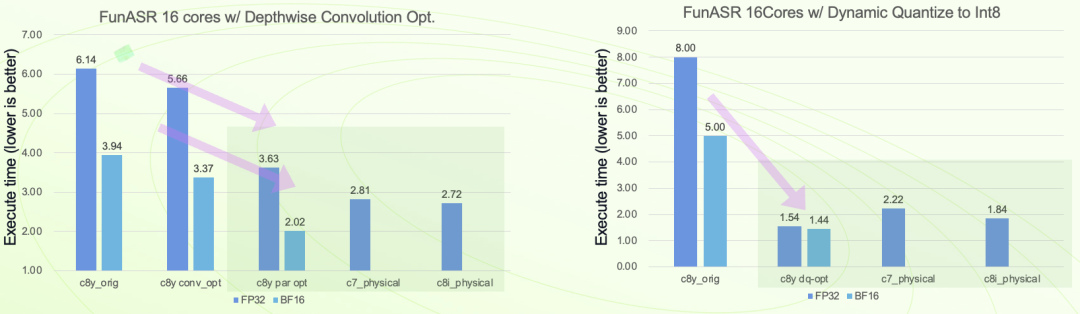
图 10:优化结果对比
综上,通过充分利用 Armv9 架构中的 SVE2 指令、BF16 数据类型等特性,并引入动态量化等技术,能够实现以 FunASR 为例的大模型在 Arm Neoverse 平台的服务器上高效率运行。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20392浏览量
255713 -
ARM
+关注
关注
135文章
9618浏览量
394589 -
语音识别
+关注
关注
39文章
1834浏览量
116370 -
pytorch
+关注
关注
2文章
813浏览量
14958
原文标题:FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大模型优化压缩空气储能系统软件平台解决方案
Arm宣布推出Performix性能分析工具套件

Arm 推出Performix:开创AI智能体性能优化新纪元
2026实测:如何在国内免费平台上将ChatGPT 5.5镜像站设为主力生成模型,搭配其他模型完成事实核查
如何在Arm Neoverse N2平台上提升llama.cpp扩展性能
西门子EDA与Arm携手合作加速系统设计验证进程与软件启动

Arm Neoverse平台集成NVIDIA NVLink Fusion
在NVIDIA DGX Spark平台上对NVIDIA ConnectX-7 200G网卡配置教程
如何把蜂鸟E203的核移植在N4DDR平台上?
3Dfindit上发布世嘉智尼的上万个3D CAD模型,优化用户设计流程
西门子 Veloce CS 助力 Arm Neoverse 计算子系统验证与确认
广和通发布自研端侧语音识别大模型FiboASR
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?
Arm Neoverse N2平台实现DeepSeek-R1满血版部署




评论