 Rambus HBM3内存控制器IP速率达到9.6 Gbps
Rambus HBM3内存控制器IP速率达到9.6 Gbps

- 以下文章转载自【donews】-
在人工智能大模型浪潮的推动下,AI训练数据集正极速扩增。以ChatGPT为例,去年11月发布的GPT-3,使用1750亿个参数构建,今年3月发布的GPT-4使用超过1.5万亿个参数。海量的数据训练,这对算力提出了高需求。
而HBM(高频宽存储器)作为内存的一种技术类型,采用创新的2.5D/3D架构,能够为AI加速器提供具有高内存带宽和低功耗的解决方案,同时凭借极低的延迟和紧凑的封装,HBM已成为AI训练硬件的首选。
TrendForce预估,2024年全球HBM的位元供给有望增长105%;HBM市场规模也有望于2024年达89亿美元,同比增长127%;预计2025年HBM市场规模将会突破100亿美元。
近日,作为业界领先的芯片和IP核供应商, Rambus Inc.(纳斯达克股票代码:RMBS)宣布Rambus HBM3内存控制器IP现在可提供高达9.6 Gbps的性能,可支持HBM3标准的持续演进。
大幅提升AI性能 提供领先支持
众所周知,JEDEC(电子工程器件联合委员会)将DRAM分为标准DDR、移动DDR以及图形DDR三类,HBM则属于图形DDR中的一种。
在设计上,HBM包含了中介层,以及处理器、内存堆栈。HBM通过使用先进的封装方法(如TSV硅通孔技术)垂直堆叠多个DRAM,与GPU通过中介层互联封装在一起,打破了内存带宽及功耗瓶。这也让传输速率成为了HBM的核心参数。
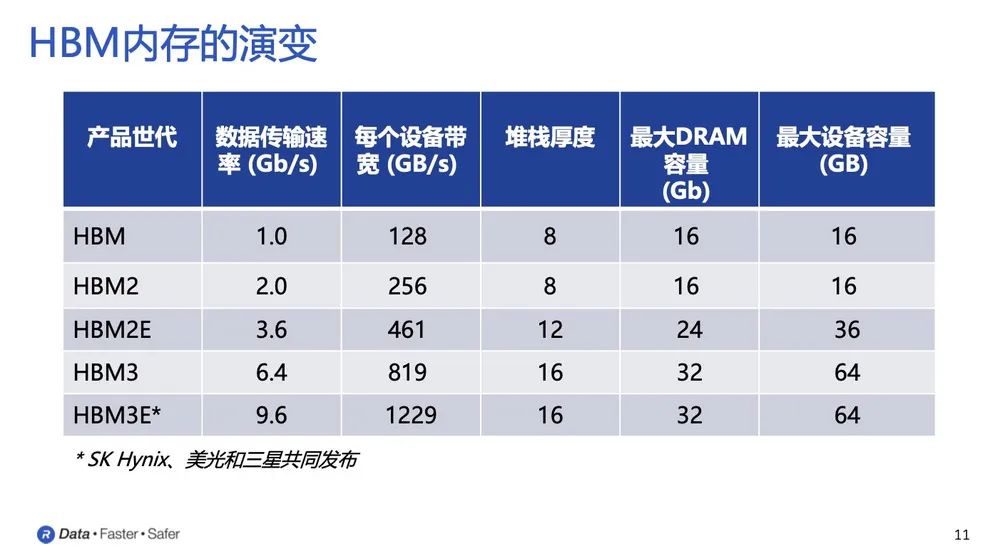
从2014年全球首款HBM产品问世至今,HBM技术已发展至第四代,分别为HBM、HBM2、HBM2e、HBM3,带宽和容量分别从最初128GB/S和1GB提升至819GB/S和24GB,传输速度从1Gbps提高至6.4Gbps。据悉,第五代HBM3E已在路上, 由SK Hynix、美光和三星共同发布,它所支持的数据传输速率达到9.6Gb/s。
对于HBM而言,Rambus并不陌生,早于2016年就入局了HBM市场。此次发布的Rambus HBM3内存控制器IP专为需要高内存吞吐量、低延迟和完全可编程性应用而设计。相比HBM3 Gen1 6.4 Gbps 的数据速率,Rambus HBM3内存控制器的数据速率提高了50%,总内存吞吐量超过1.2 TB/s,适用于推荐系统的训练、生成式AI以及其他要求苛刻的数据中心工作负载。
Rambus 接口IP产品管理和营销副总裁 Joe Salvador介绍称,该控制器是一种高度可配置的模块化解决方案,可根据每个客户对尺寸和性能的独特要求进行定制。目前已与SK海力士、美光、三星完成了一整套的测试。对于选择第三方HBM3 PHY(物理层)的客户,Rambus还提供HBM3控制器的集成与验证服务。
就当前HBM市场发展格局,Joe Salvador坦言道:“目前为止还没有了解到有哪一家竞争对手跟我们一样,已经有经过验证的能够去支持HBM3 9.6Gbps传输速率的内存控制器IP。Rambus HBM3内存控制器将以高达9.6Gb/s的性能,为HBM3提供业界领先的支持。”
同时,Joe Salvador表示,一家企业想进入到HBM行业会面临相应的一些门槛和有诸多的挑战,首先就是对于总体架构设计的复杂度和了解程度不够。Rambus正是得益于积累了多年的技术经验和跟主流内存厂商合作的经验,使得所设计出来的内存控制器可以做到高性能、低功耗,而且对于客户来说成本也相对较低,且具有很好的兼容性。
AI时代 Rambus将全面发力
当前大模型的百花齐放,让HBM也水涨船高。
但面对当前AI发展趋势,Joe Salvador直言道,目前来说,我们无法预知它未来会发展到何种程度。“目前,还没有看到AI相关的应用领域,对于高性能计算、更高的带宽和内存容量的需求有任何下降的趋势。所以在可以预见的将来,这都会一直推动我们持续地创新,以及推动整个行业进一步地创新。”
他还表示,目前可以看到的是,AI的应用场景正在从以前集中在数据中心当中,逐渐地向边缘计算去拓展。对于Rambus来说,这也就意味着我们业务的重心将有可能不再像以前那样全部集中在数据中心当中,而是也会随着市场需求囊括边缘计算的场景。
Rambus 大中华区总经理苏雷补充称,AI向前发展对技术方面的需求,主要就是算力和内存,算力方面可能不会有太多的挑战,目前摆在业界面前的更多是存储的问题。而Rambus是存储方面的专家,可以预见到伴随着AI的新成长,Rambus会在这一轮的科技浪潮中发挥越来越重要的作用,助力AI的成长。
审核编辑:汤梓红
-
存储器
+关注
关注
39文章
7769浏览量
172435 -
Rambus
+关注
关注
0文章
70浏览量
19354 -
人工智能
+关注
关注
1821文章
50511浏览量
267734
原文标题:【媒体报道】Rambus HBM3速率达到9.6 Gbps,大幅提升AI性能
文章出处:【微信号:Rambus 蓝铂世科技,微信公众号:Rambus 蓝铂世科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Rambus重磅推出集成TDM功能的PCIe 7.0交换机IP
Rambus推出基于LPDDR的SOCAMM2服务器模块芯片组
使用ls - addsw命令创建了一个 dpsw,运行测试过程中数据包速率达到1.2Gbps时,dpsw不会遇到缓冲区丢弃如何解决?
Cadence在CES 2026成功演示3nm eUSB2V2 PHY IP解决方案
消息称英伟达HBM4订单两家七三分,独缺这一家
Texas Instruments CDCFR83A:Direct Rambus时钟发生器的技术解析
深入解析 MIC5162:高性能 DDR 内存总线终端控制器
高速通信利器:TLK10002 10 - Gbps 双信道多速率收发器解析
AI大算力的存储技术, HBM 4E转向定制化

CDCFR83A 直接 Rambus™ 时钟发生器文档总结
澜起科技推出CXL® 3.1内存扩展控制器,助力下一代数据中心基础设施性能升级
Cadence推出LPDDR6/5X 14.4Gbps内存IP系统解决方案



评论