 HPC领域的一款大杀器-HBX-G500大带宽加速卡
HPC领域的一款大杀器-HBX-G500大带宽加速卡

HBX-G500是一款为AI、计算和网络领域设计的高性能可编程加速器卡。它配备了多通道的高带宽存储和高效能计算能力,以及先进的高速接口解决方案,特别适用于运行大型模型。即便在小批量数据处理时,它的性能也能媲美A100和H100。
该加速器卡搭载了两组PCIe GEN5接口,并配备了两个400GbE和一个200Gbe网络接口,以及32GB的GDDR6存储单元。
它还具备一个包含超过80个节点的2DNOC网络和2560个高度可配置的MLP计算核心,以支持密集型计算任务。2DNOC不仅连接了高速接口和存储单元,而且还连接了Fabric的80个节点,使得用户可以更专注于功能开发。总线路由问题可以简单地通过NOC连接来解决。
板卡功能:
两路PCIe Gen5 ,其中PCIe Gen5X16支持系统接口,PCIeGen5X4可同时支持RC/EP
两路网口,速率可达400Gbe以及200Gbe,且支持向下速率兼容
32GBGDDR6,市面上为数不多的支持GDDR6的FPGA板卡,支持16通路访问,内存带宽可达3.5Tbps
FPGA可支持达1500K LE
FPGA支持2560高性能计算核心(MLP)
每个MLP最大支持32个乘法器,可根据数据位宽的变化做调整
专属内嵌的LRAM/BRAM可缓存数据或者快速反馈结
支持整型(INT16/INT8/INT4)、浮点(FP24/FP16)、BFP
INT8总算力约61Tops
支持通用串行总线(USB)JTAG配置、PCIe加载
支持上电自加载,1GB QSPI闪存 板卡规格:
尺寸:高度:111.15mm 长度:275mm
工作电压:外部两路+12VDC
适用AI应用的架构特性:
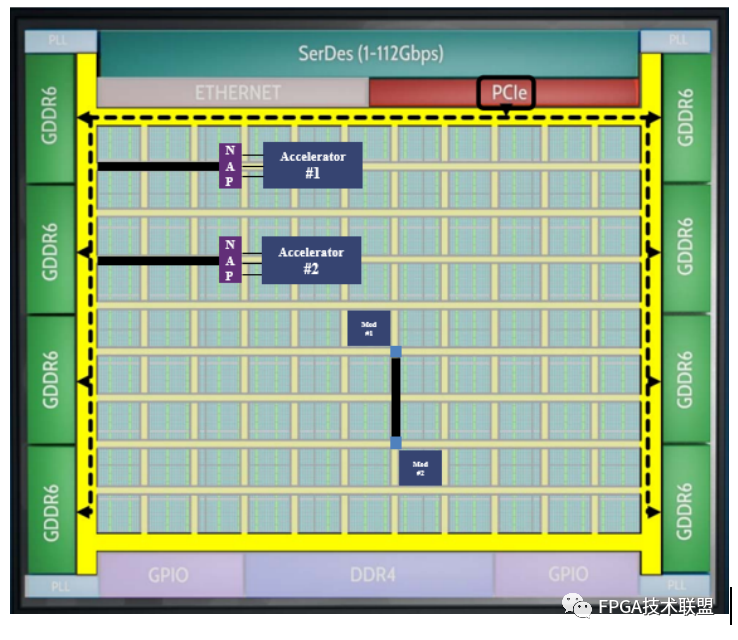
2D NOC的高效路由架构让用户可以集中精力于开发:
它支持广泛采用的AXI4标准接口。
NOC的工作频率可达2Ghz,数据传输宽度为256位。
主机通过PCIe接口,可以直接通过NOC的黄色区域访问16条通道的GDDR6存储。
主机通过PCIe,同样可以通过NOC的黄色区域直接访问连接在NAP上的任意功能单元。
功能单元能够通过NOC直接访问存储资源(GDDR6或DDR)。
不同功能单元之间可以通过NOC进行高效互联。
审核编辑:刘清
-
FPGA
+关注
关注
1664文章
22571浏览量
640736 -
JTAG
+关注
关注
6文章
417浏览量
75334 -
QSPI
+关注
关注
0文章
55浏览量
13440 -
PCIe接口
+关注
关注
0文章
130浏览量
10662 -
GDDR6
+关注
关注
0文章
52浏览量
11634
原文标题:HPC领域的一款大杀器---HBX-G500大带宽加速卡
文章出处:【微信号:傅里叶的猫,微信公众号:傅里叶的猫】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
BMA220:一款高性能的三轴加速度传感器
AMD正式推出Instinct MI350P PCIe GPU加速卡
瀚博半导体载天VA16加速卡成功适配DeepSeek-V4大模型
选择AMD Alveo V80加速卡的五大理由
AMD Alveo MA35D媒体加速卡的AMA SDK 1.4.0版本发布
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN标准嵌入式开发板

高速信号处理设计方案:413-基于双XCVU9P+C6678的100G光纤加速卡
昆仑芯R200 AI加速卡技术规格解析

迈向云端算力巅峰:昆仑芯K200 AI加速卡全面解读

深圳光量子工厂启示:PCI 加速卡为何偏向 25MHz 2016 有源晶振?

算力密度翻倍!江原D20加速卡发布,一卡双芯重构AI推理标杆

虚拟电厂加速卡不是噱头!万点规模VPP的性能分水岭
新品 | LLM-8850 Card, AX8850边缘设备AI加速卡

智算加速卡是什么东西?它真能在AI战场上干掉GPU和TPU!




评论