 小模型也能进行上下文学习!字节&华东师大联合提出自进化文本识别器
小模型也能进行上下文学习!字节&华东师大联合提出自进化文本识别器

大语言模型(LLM)能够以一种无需微调的方式从少量示例中学习,这种方式被称为 "上下文学习"(In-context Learning)。目前只在大模型上观察到上下文学习现象,那么,常规大小的模型是否具备类似的能力呢?GPT4、Llama等大模型在非常多的领域中都表现出了杰出的性能,但很多场景受限于资源或者实时性要求较高,无法使用大模型。为了探索小模型的上下文学习能力,字节和华东师大的研究团队在场景文本识别任务上进行了研究。
场景文本识别(Scene Text Recognition)的目标是将图像中的文本内容提取出来。实际应用场景中,场景文本识别面临着多种挑战:不同的场景、文字排版、形变、光照变化、字迹模糊、字体多样性等,因此很难训练一个能应对所有场景的统一的文本识别模型。一个直接的解决办法是收集相应的数据,然后在特定场景下对模型进行微调。但是这一过程需要重新训练模型,当场景变多、领域任务变得复杂时,实际的训练、存储、维护资源则呈几何倍增长。如果文本识别模型也能具备上下文学习能力,面对新的场景,只需少量标注数据作为提示,就能提升在新场景上的性能,那么上面的问题就迎刃而解。然而,场景文本识别是一个资源敏感型任务,将大模型当作文本识别器非常耗费资源,并且通过初步的实验,研究人员发现传统的训练大模型的方法在场景文本识别任务上并不适用。
为了解决这个问题,来自字节和华东师大的研究团队提出了自进化文本识别器,ESTR(Ego-Evolving Scene Text Recognizer),一个融合了上下文学习能力的常规大小文本识别器,无需微调即可快速适应不同的文本识别场景。ESTR配备了一种上下文训练和上下文推理模式,不仅在常规数据集上达到了SOTA的水平,而且可以使用单一模型提升在各个场景中的识别性能,实现对新场景的快速适应,甚至超过了经过微调后专用模型的识别性能。ESTR证明,常规大小的模型足以在文本识别任务中实现有效的上下文学习能力。ESTR在各种场景中无需微调即可表现出卓越的适应性,甚至超过了经过微调后的识别性能。

论文地址:https://arxiv.org/pdf/2311.13120
方法
图1介绍了ESTR的训练和推理流程。
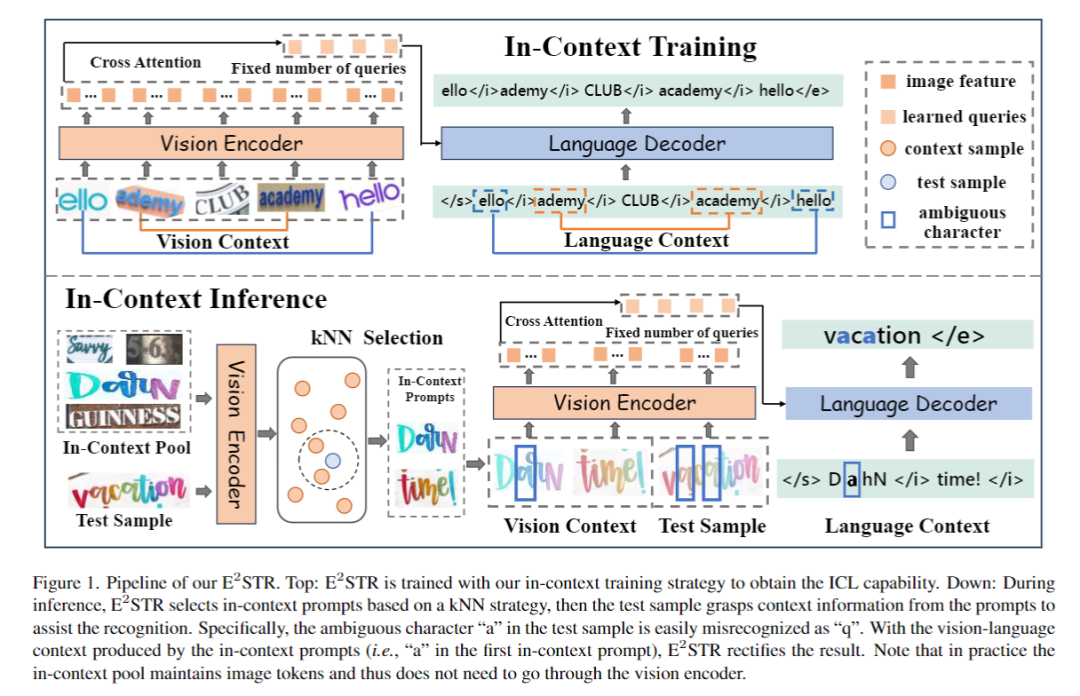
1.基础文本识别训练
基础文本识别训练阶段采用自回归框架训练视觉编码器和语言解码器:
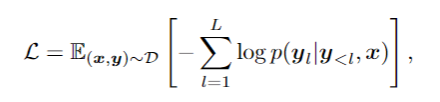
2.上下文训练
上下文训练阶段ESTR 将根据文中提出的上下文训练范式进行进一步训练。在这一阶段,ESTR 会学习理解不同样本之间的联系,从而从上下文提示中获益。
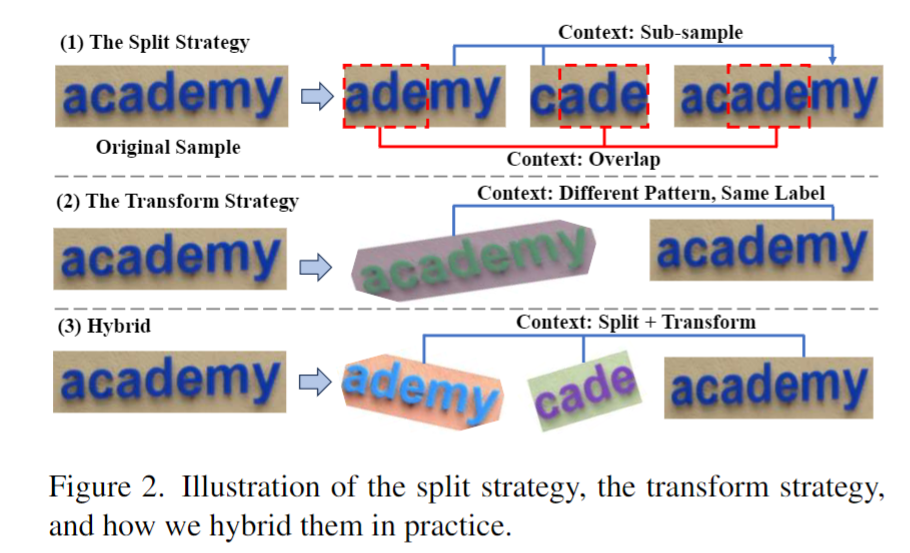
如图2所示,这篇文章提出 ST 策略,在场景文本数据中进行随机的分割和转换,从而生成一组 "子样本"。子样本在视觉和语言方面都是内在联系的。这些内在联系的样本被拼接成一个序列,模型从这些语义丰富的序列中学习上下文知识,从而获取上下文学习的能力。这一阶段同样采用自回归框架进行训练:
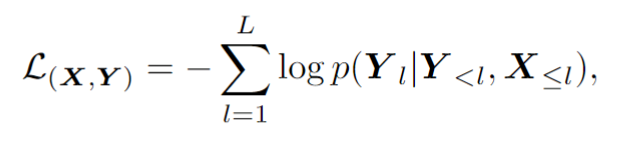
3.上下文推理
针对一个测试样本,该框架会从上下文提示池中选择 个样本,这些样本在视觉隐空间与测试样本具有最高的相似度。具体来说,这篇文章通过对视觉token序列做平均池化,计算出图像embedding 。然后,从上下文池中选择图像嵌入与 的余弦相似度最高的前 N 个样本,从而形成上下文提示。
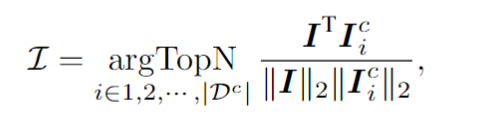
上下文提示和测试样本拼接在一起送入模型,ESTR便会以一种无训练的方式从上下文提示中学得新知识,提升测试样本的识别准确率。值得注意的是,上下文提示池只保留了视觉编码器输出的token,使得上下文提示的选择过程非常高效。此外,由于上下文提示池很小,而且ESTR不需要训练就能直接进行推理,因此额外的消耗也降到了最低限度。
实验
实验从三个角度进行:
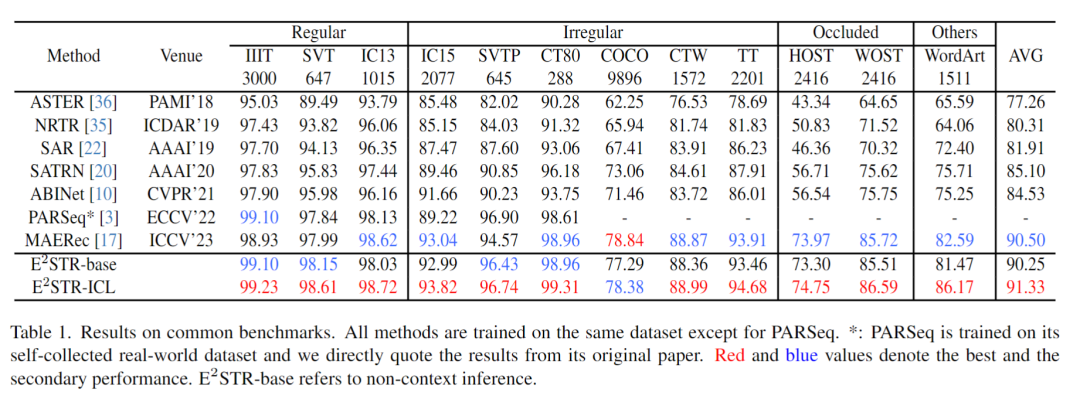
1.传统数据集
从训练集中随机抽取很少的样本(1000个,训练集 0.025% 的样本数量)组成上下文提示池,在12个常见的场景文本识别测试集中进行的测试,结果如下:
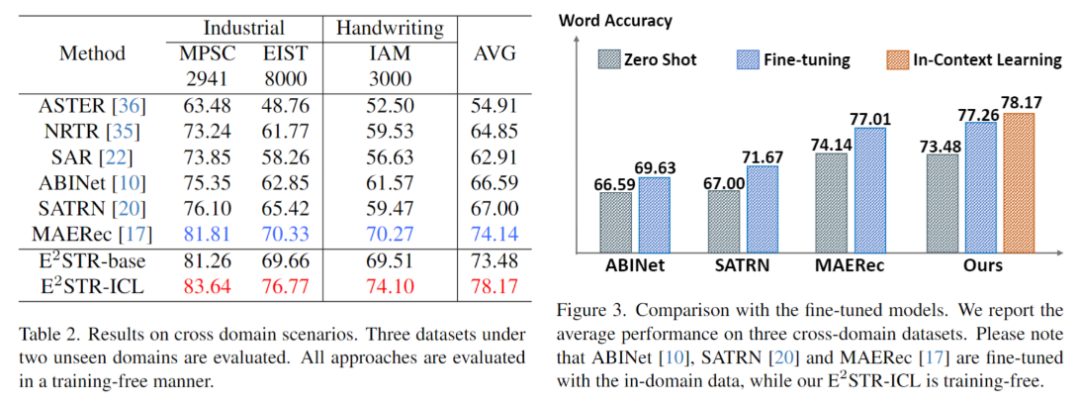
2.跨域场景
跨域场景下每个测试集仅提供100个域内训练样本,无训练和微调对比结果如下。ESTR甚至超过了SOTA方法的微调结果。
3.困难样本修正
研究人员收集了一批困难样本,对这些样本提供了10%~20%的标注,对比ESTR的无训练学习方法和SOTA方法的微调学习方法,结果如下:
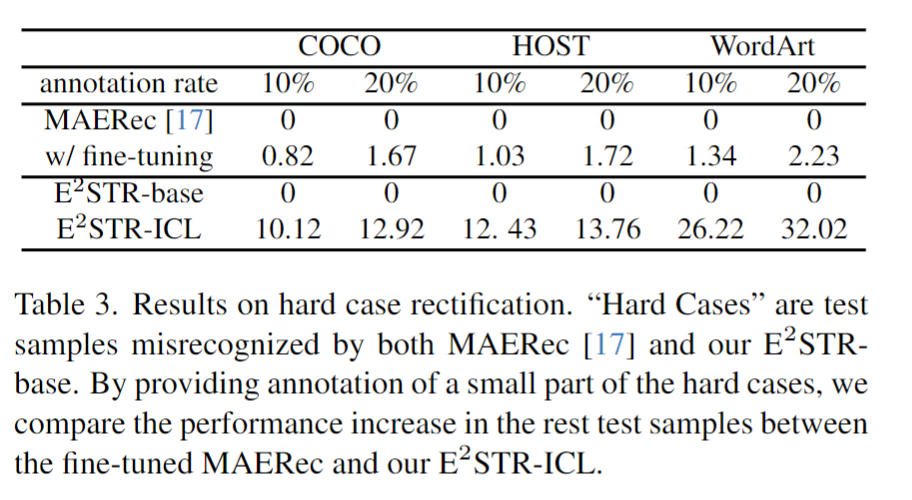
可以发现,ESTR-ICL大大降低了困难样本的错误率。
未来展望
ESTR证明了使用合适的训练和推理策略,小模型也可以拥有和LLM类似的In-context Learning的能力。在一些实时性要求比较强的任务中,使用小模型也可以对新场景进行快速的适应。更重要的是,这种使用单一模型来实现对新场景快速适应的方法使得构建统一高效的小模型更近了一步。
-
模型
+关注
关注
1文章
3831浏览量
52285 -
识别器
+关注
关注
0文章
27浏览量
7873 -
大模型
+关注
关注
2文章
3796浏览量
5276
原文标题:小模型也能进行上下文学习!字节&华东师大联合提出自进化文本识别器
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
宁畅AI服务器全栈适配DeepSeek V4大模型
安信可AI语音模组支持MCP模型上下文协议
工作流大模型节点说明
什么是大模型,智能体...?大模型100问,快速全面了解!

NVIDIA BlueField-4为推理上下文记忆存储平台提供强大支持

深入解析NVIDIA Nemotron 3系列开放模型
大语言模型如何处理上下文窗口中的输入

请问riscv中断还需要软件保存上下文和恢复吗?
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
HarmonyOSAI编程编辑区代码续写
HarmonyOS AI辅助编程工具(CodeGenie)代码续写
鸿蒙NEXT-API19获取上下文,在class中和ability中获取上下文,API迁移示例-解决无法在EntryAbility中无法使用最新版

新知|Verizon与AT&amp;amp;T也可以手机直接连接卫星了

Transformer架构中编码器的工作流程




评论