 我们能否扩展现有的预训练 LLM 的上下文窗口
我们能否扩展现有的预训练 LLM 的上下文窗口

在大家不断升级迭代自家大模型的时候,LLM(大语言模型)对上下文窗口的处理能力,也成为一个重要评估指标。 比如 OpenAI 的 gpt-3.5-turbo 提供 16k token 的上下文窗口选项,AnthropicAI 的更是将 Claude 处理 token 能力提升到 100k。大模型处理上下文窗口是个什么概念,就拿 GPT-4 支持 32k token 来说,这相当于 50 页的文字,意味着在对话或生成文本时,GPT-4 最多可以记住 50 页左右内容。 一般来讲,大语言模型处理上下文窗口大小的能力是预定好的。例如,Meta AI 发布的 LLaMA 模型,其输入 token 大小必须少于 2048。 然而,在进行长对话、总结长文档或执行长期计划等应用程序中,经常会超过预先设置的上下文窗口限制,因而,能够处理更长上下文窗口的 LLM 更受欢迎。 但这又面临一个新的问题,从头开始训练具有较长上下文窗口的 LLM 需要很大的投入。这自然引出一个疑问:我们能否扩展现有的预训练 LLM 的上下文窗口? 一种直接的方法是对现有的预训练 Transformer 进行微调,以获得更长的上下文窗口。然而,实证结果表明,使用这种方式训练的模型对长上下文窗口的适应速度非常慢。经过 10000 个批次的训练后,有效上下文窗口的增加仍然非常小,仅从 2048 增加到 2560(实验部分的表 4 可以看出)。这表明这种方法在扩展到更长的上下文窗口上效率低下。 本文中,来自 Meta 的研究者引入了位置插值(Position Interpolation,PI)来对某些现有的预训练 LLM(包括 LLaMA)的上下文窗口进行扩展。结果表明,LLaMA 上下文窗口从 2k 扩展到 32k,只需要小于 1000 步的微调。  论文地址:https://arxiv.org/pdf/2306.15595.pdf 该研究的关键思想不是进行外推(extrapolation),而是直接缩小位置索引,使得最大位置索引与预训练阶段的上下文窗口限制相匹配。换句话说,为了容纳更多的输入 token,该研究在相邻的整数位置上插值位置编码,利用了位置编码可以应用于非整数位置的事实,与在训练过的位置之外进行外推相比,后者可能导致灾难性的数值。
论文地址:https://arxiv.org/pdf/2306.15595.pdf 该研究的关键思想不是进行外推(extrapolation),而是直接缩小位置索引,使得最大位置索引与预训练阶段的上下文窗口限制相匹配。换句话说,为了容纳更多的输入 token,该研究在相邻的整数位置上插值位置编码,利用了位置编码可以应用于非整数位置的事实,与在训练过的位置之外进行外推相比,后者可能导致灾难性的数值。 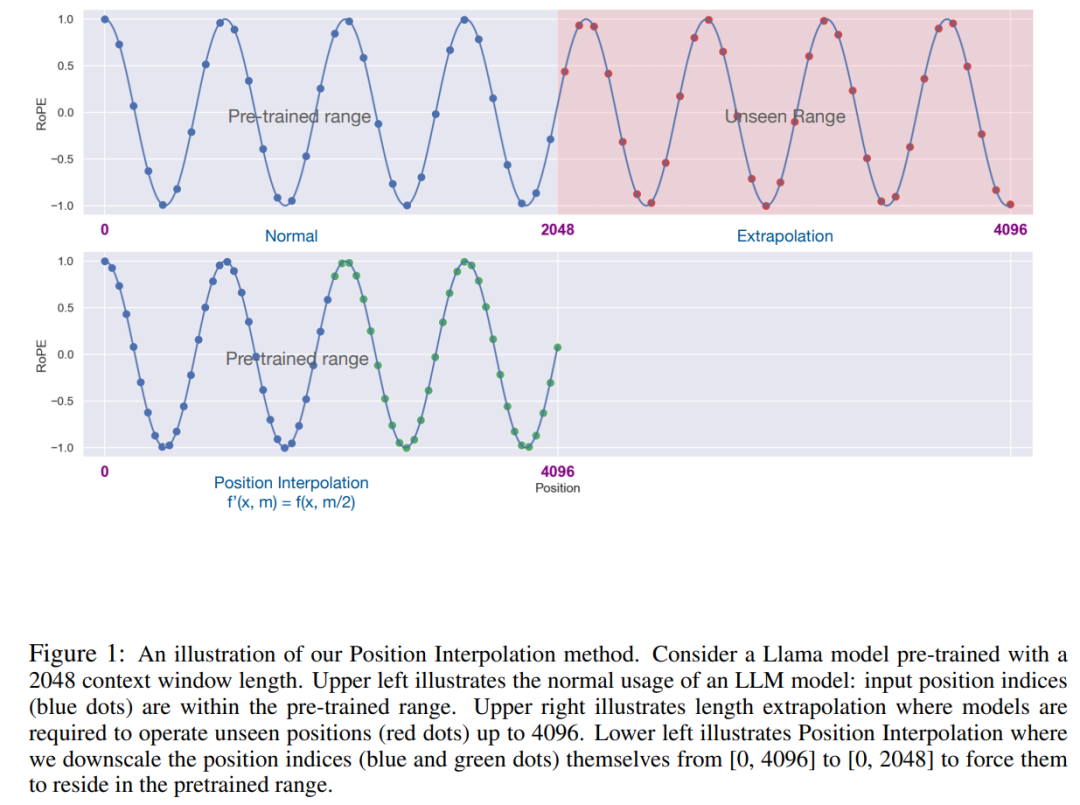 PI 方法将基于 RoPE(旋转位置编码)的预训练 LLM(如 LLaMA)的上下文窗口大小扩展到最多 32768,只需进行最小的微调(在 1000 个步骤内),这一研究在需要长上下文的各种任务上性能较好,包括密码检索、语言建模以及从 LLaMA 7B 到 65B 的长文档摘要。与此同时,通过 PI 扩展的模型在其原始上下文窗口内相对保持了较好的质量。 方法 在我们比较熟悉的 LLaMA、ChatGLM-6B、PaLM 等大语言模型中,都有 RoPE 身影,该方法由追一科技苏剑林等人提出,RoPE 通过绝对编码的方式实现了相对位置编码。 虽然 RoPE 中的注意力得分只取决于相对位置,但它的外推性能并不好。特别是,当直接扩展到更大的上下文窗口时,困惑度可能会飙升到非常高的数字 (即 > 10^3)。 本文采用位置插值的方法,其与外推方法的比较如下。由于基函数 ϕ_j 的平滑性,插值更加稳定,不会导致野值。
PI 方法将基于 RoPE(旋转位置编码)的预训练 LLM(如 LLaMA)的上下文窗口大小扩展到最多 32768,只需进行最小的微调(在 1000 个步骤内),这一研究在需要长上下文的各种任务上性能较好,包括密码检索、语言建模以及从 LLaMA 7B 到 65B 的长文档摘要。与此同时,通过 PI 扩展的模型在其原始上下文窗口内相对保持了较好的质量。 方法 在我们比较熟悉的 LLaMA、ChatGLM-6B、PaLM 等大语言模型中,都有 RoPE 身影,该方法由追一科技苏剑林等人提出,RoPE 通过绝对编码的方式实现了相对位置编码。 虽然 RoPE 中的注意力得分只取决于相对位置,但它的外推性能并不好。特别是,当直接扩展到更大的上下文窗口时,困惑度可能会飙升到非常高的数字 (即 > 10^3)。 本文采用位置插值的方法,其与外推方法的比较如下。由于基函数 ϕ_j 的平滑性,插值更加稳定,不会导致野值。 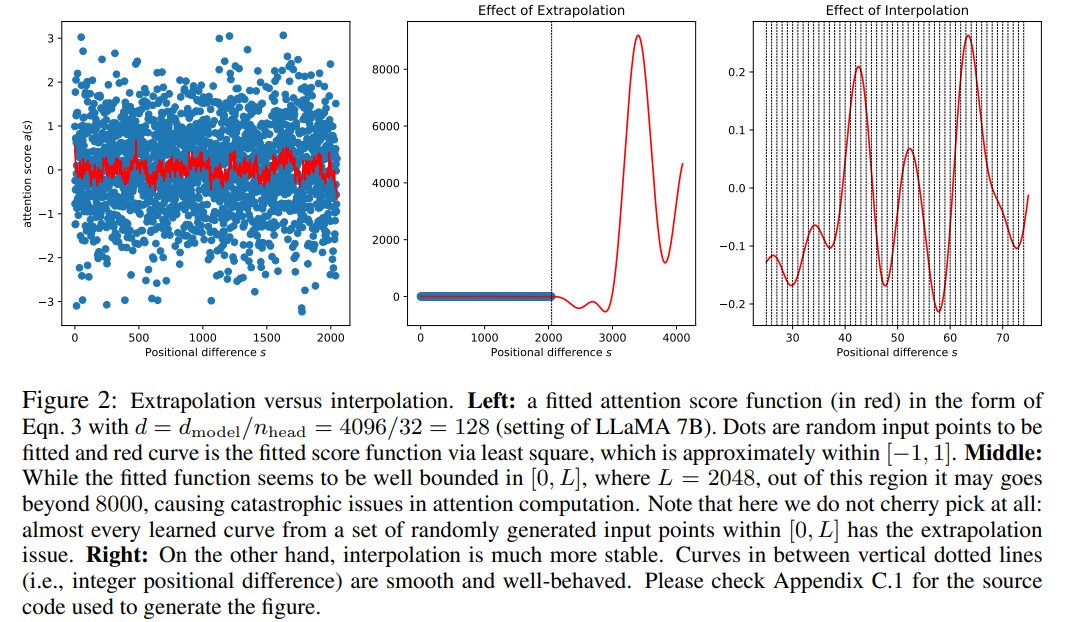 该研究将 RoPE f 替换为 f ′,得到如下公式
该研究将 RoPE f 替换为 f ′,得到如下公式  该研究将在位置编码上的转换称为位置插值。这一步将位置索引从 [0, L′ ) 缩减到 [0, L) ,以匹配计算 RoPE 前的原始索引范围。因此,作为 RoPE 的输入,任意两个 token 之间的最大相对距离已从 L ′ 缩减到 L。通过在扩展前后对位置索引和相对距离的范围进行对齐,减轻了由于上下文窗口扩展而对注意力分数计算产生的影响,这使得模型更容易适应。 值得注意的是,重新缩放位置索引方法不会引入额外的权重,也不会以任何方式修改模型架构。 实验 该研究展示了位置插值可以有效地将上下文窗口扩展到原始大小的 32 倍,并且这种扩展只需进行几百个训练步骤即可完成。 表 1 和表 2 报告了 PI 模型和基线模型在 PG-19 、 Arxiv Math Proof-pile 数据集上的困惑度。结果表明使用 PI 方法扩展的模型在较长的上下文窗口大小下显著改善了困惑度。
该研究将在位置编码上的转换称为位置插值。这一步将位置索引从 [0, L′ ) 缩减到 [0, L) ,以匹配计算 RoPE 前的原始索引范围。因此,作为 RoPE 的输入,任意两个 token 之间的最大相对距离已从 L ′ 缩减到 L。通过在扩展前后对位置索引和相对距离的范围进行对齐,减轻了由于上下文窗口扩展而对注意力分数计算产生的影响,这使得模型更容易适应。 值得注意的是,重新缩放位置索引方法不会引入额外的权重,也不会以任何方式修改模型架构。 实验 该研究展示了位置插值可以有效地将上下文窗口扩展到原始大小的 32 倍,并且这种扩展只需进行几百个训练步骤即可完成。 表 1 和表 2 报告了 PI 模型和基线模型在 PG-19 、 Arxiv Math Proof-pile 数据集上的困惑度。结果表明使用 PI 方法扩展的模型在较长的上下文窗口大小下显著改善了困惑度。 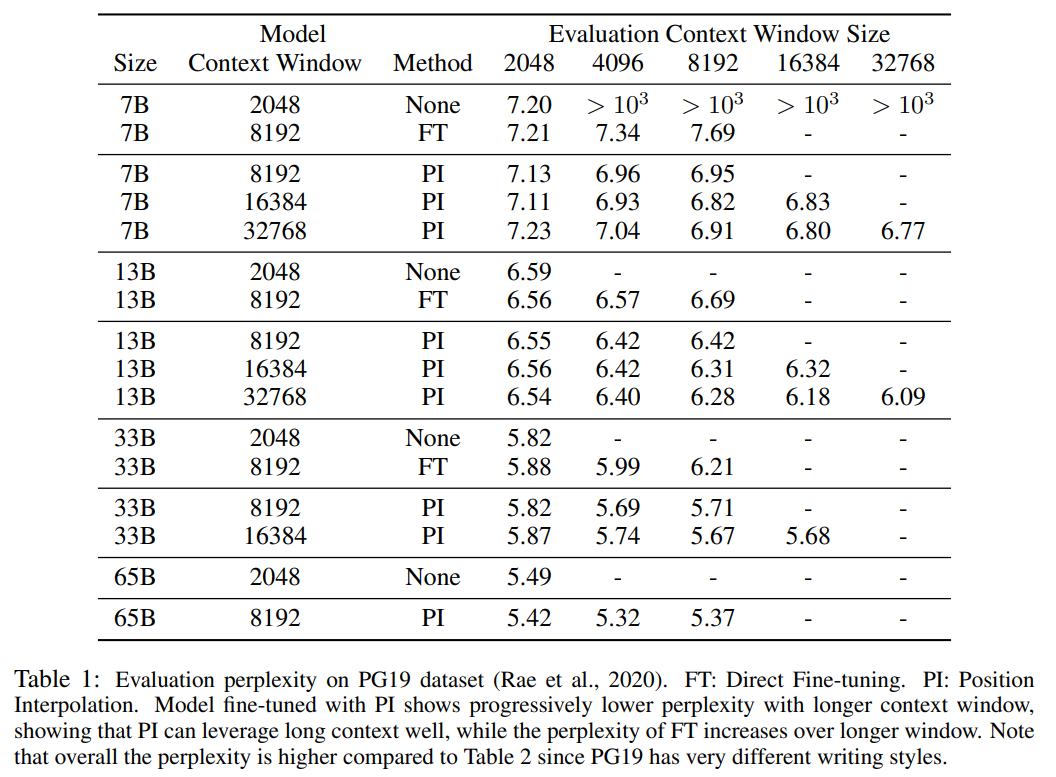
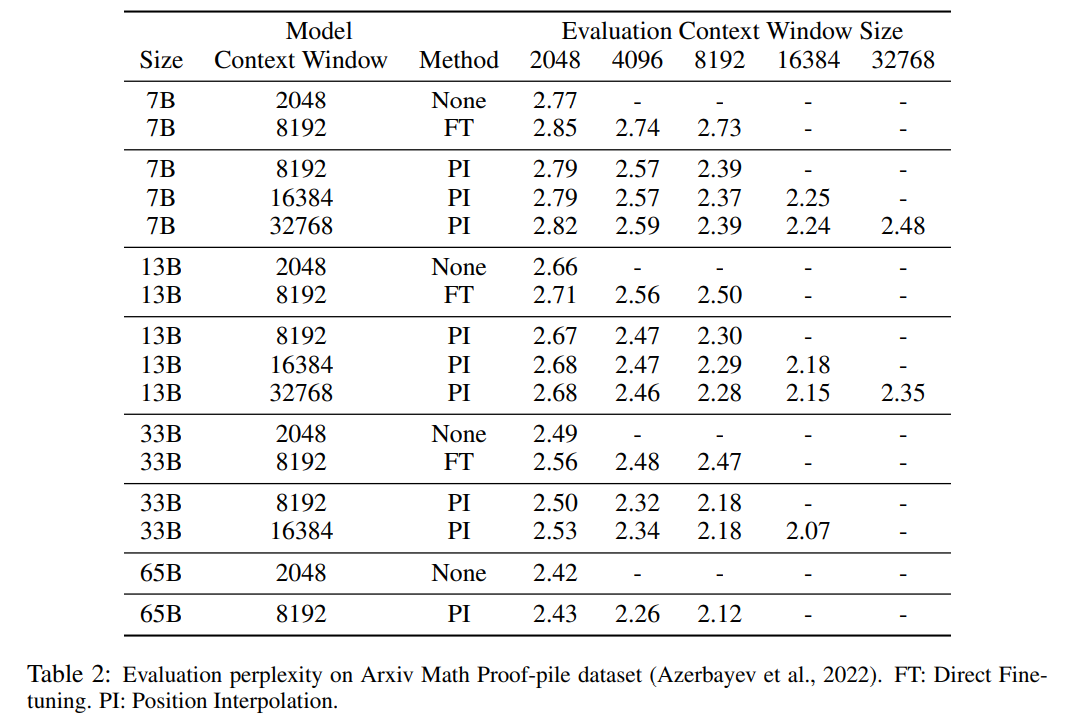 表 3 报告了在 PG19 数据集上使用 PI 方法,将 LLaMA 7B 模型扩展到 8192 和 16384 上下文窗口大小时的困惑度与微调步数之间的关系。 由结果可得,在没有微调的情况下(步数为 0),模型可以展现出一定的语言建模能力,如将上下文窗口扩展到 8192 时的困惑度小于 20(相比之下,直接外推方法的困惑度大于 10^3)。在 200 个步骤时,模型的困惑度超过了 2048 上下文窗口大小下原始模型的困惑度,表明模型能够有效利用比预训练设置更长的序列进行语言建模。在 1000 个步骤时可以看到模型稳步改进,并取得了更好的困惑度。
表 3 报告了在 PG19 数据集上使用 PI 方法,将 LLaMA 7B 模型扩展到 8192 和 16384 上下文窗口大小时的困惑度与微调步数之间的关系。 由结果可得,在没有微调的情况下(步数为 0),模型可以展现出一定的语言建模能力,如将上下文窗口扩展到 8192 时的困惑度小于 20(相比之下,直接外推方法的困惑度大于 10^3)。在 200 个步骤时,模型的困惑度超过了 2048 上下文窗口大小下原始模型的困惑度,表明模型能够有效利用比预训练设置更长的序列进行语言建模。在 1000 个步骤时可以看到模型稳步改进,并取得了更好的困惑度。 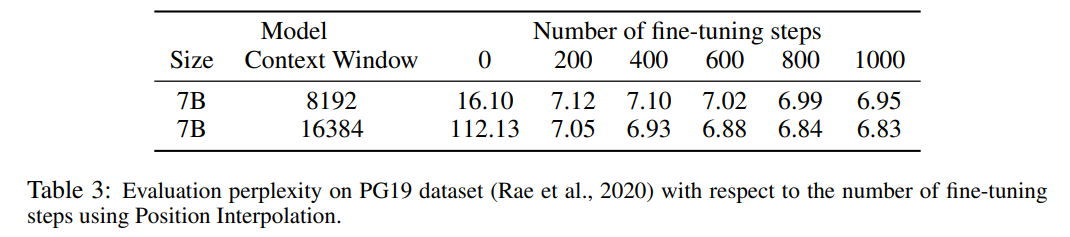 下表表明,通过 PI 扩展的模型在有效上下文窗口大小方面都成功地实现了扩展目标,即仅通过微调 200 个步骤后,有效上下文窗口大小达到最大值,在 7B 和 33B 模型大小以及最高 32768 上下文窗口的情况下保持一致。相比之下,仅通过直接微调扩展的 LLaMA 模型的有效上下文窗口大小仅从 2048 增加到 2560,即使经过 10000 多个步骤的微调,也没有明显加速窗口大小增加的迹象。
下表表明,通过 PI 扩展的模型在有效上下文窗口大小方面都成功地实现了扩展目标,即仅通过微调 200 个步骤后,有效上下文窗口大小达到最大值,在 7B 和 33B 模型大小以及最高 32768 上下文窗口的情况下保持一致。相比之下,仅通过直接微调扩展的 LLaMA 模型的有效上下文窗口大小仅从 2048 增加到 2560,即使经过 10000 多个步骤的微调,也没有明显加速窗口大小增加的迹象。 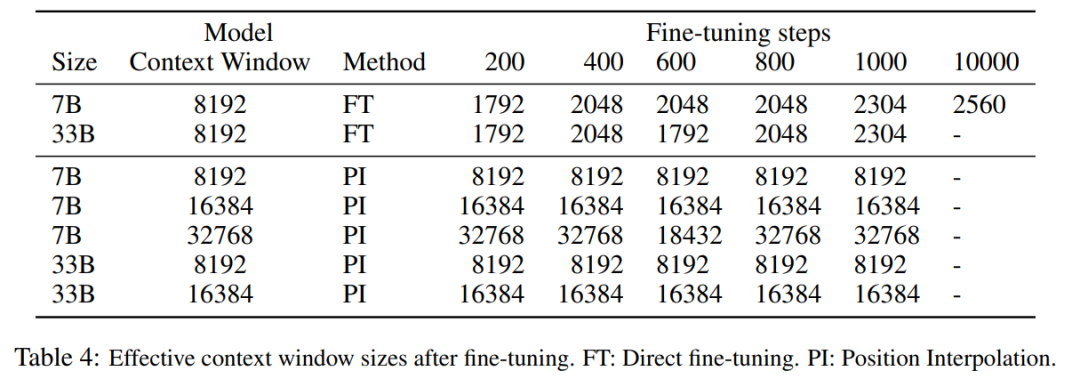 表 5 显示扩展到 8192 的模型在原始基准任务上产生了可比较的结果,而该基准任务是针对更小的上下文窗口设计的,对于 7B 和 33B 模型大小,在基准任务中的退化最多达到 2%。
表 5 显示扩展到 8192 的模型在原始基准任务上产生了可比较的结果,而该基准任务是针对更小的上下文窗口设计的,对于 7B 和 33B 模型大小,在基准任务中的退化最多达到 2%。 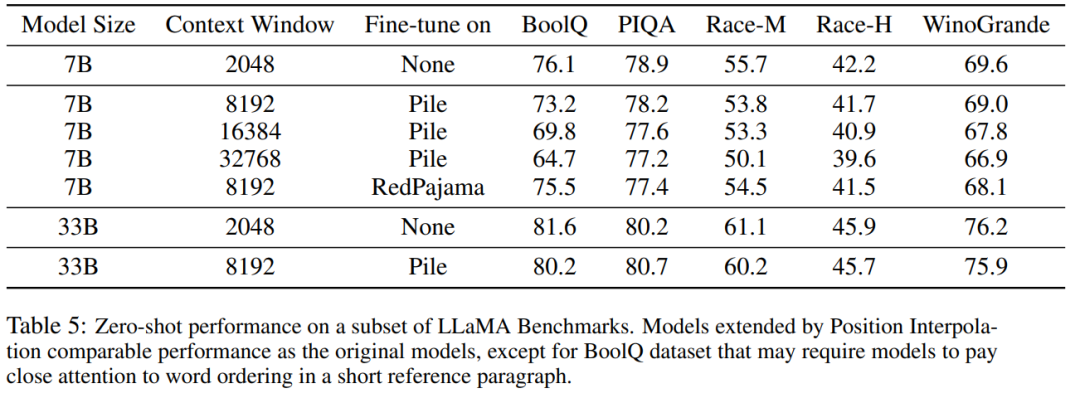 表 6 表明,具有 16384 上下文窗口的 PI 模型,可以有效地处理长文本摘要任务。
表 6 表明,具有 16384 上下文窗口的 PI 模型,可以有效地处理长文本摘要任务。 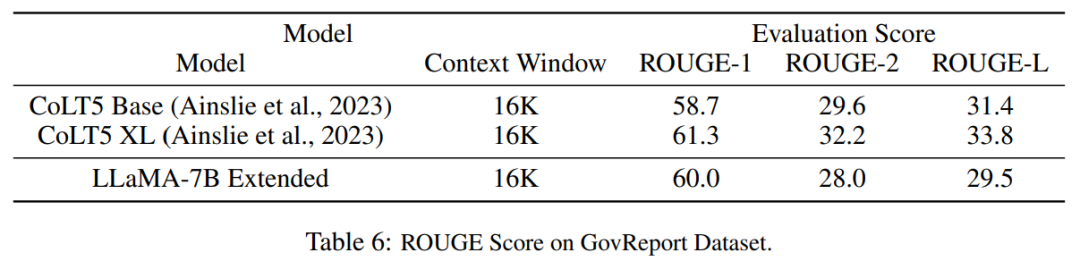
-
编码
+关注
关注
6文章
1015浏览量
56643 -
窗口
+关注
关注
0文章
66浏览量
11231 -
模型
+关注
关注
1文章
3648浏览量
51692 -
LLM
+关注
关注
1文章
340浏览量
1256
原文标题:不到1000步微调,将LLaMA上下文扩展到32K,田渊栋团队最新研究
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
关于进程上下文、中断上下文及原子上下文的一些概念理解
进程上下文与中断上下文的理解
基于多Agent的用户上下文自适应站点构架
基于交互上下文的预测方法
基于Pocket PC的上下文菜单实现
基于Pocket PC的上下文菜单实现
基于上下文相似度的分解推荐算法
初学OpenGL:什么是绘制上下文
如何分析Linux CPU上下文切换问题
Linux技术:什么是cpu上下文切换

SystemView上下文统计窗口识别阻塞原因
DeepSeek推出NSA机制,加速长上下文训练与推理
大语言模型如何处理上下文窗口中的输入






 工商网监
工商网监
评论