 请问一下DSP数学能否在AI领域战胜GPU呢?
请问一下DSP数学能否在AI领域战胜GPU呢?

AI芯片初创公司Lemurian Labs发明了一种专为AI加速设计的新型对数数字格式,并正在构建一种芯片,利用它为数据中心AI工作负载服务。
Lemurian的CEO Jay Dawani说:“2018年,我正在为机器人训练模型,部分是卷积,部分是Transformer,部分是强化学习。在1万个Nvidia V100 GPU上训练这个模型需要6个月时间……模型呈指数级增长,但很少有人有足够的算力来尝试训练,很多想法就这样被放弃了。我试图为那些有伟大想法但却苦于没有算力的普通的ML工程师构建模型。”
对Lemurian首款芯片的模拟显示,根据H100最新的MLPerf推理基准测试结果,Lemurian的新数字系统与专门设计的芯片相结合,其性能将优于Nvidia的H100。在离线模式下,Lemurian芯片在MLPerf版本的GPT-J中每个芯片每秒可处理17.54次推理(Nvidia H100在离线模式下每秒可处理13.07次推理)。Dawani说,Lemurian的模拟结果可能在真实芯片性能的10%以内,但他的团队打算今后从软件中榨取更多性能。他说,软件优化加上稀疏性可以将性能再提高3-5倍。
对数数字系统
Lemurian的秘诀在于该公司提出的新数字格式,称之为PAL(parallel adaptive logarithms)。
Dawani说:“作为一个行业,我们开始急于采用8位整数量化,因为从硬件的角度来看,这是我们所拥有的最有效的东西。但从来没有软件工程师说过我想要8位整数!”
对于今天的LLM推理而言,INT8的精度已被证明是不够的,业界已转向FP8。但Dawani解释说,AI工作负载的性质意味着数字经常处于亚正常范围(接近零的区域),FP8可以表示的数字较少,因此精度较低。FP8在亚正常范围内的覆盖率存在差距,这也是许多训练方案需要BF16和FP32等更高精度数据类型的原因。
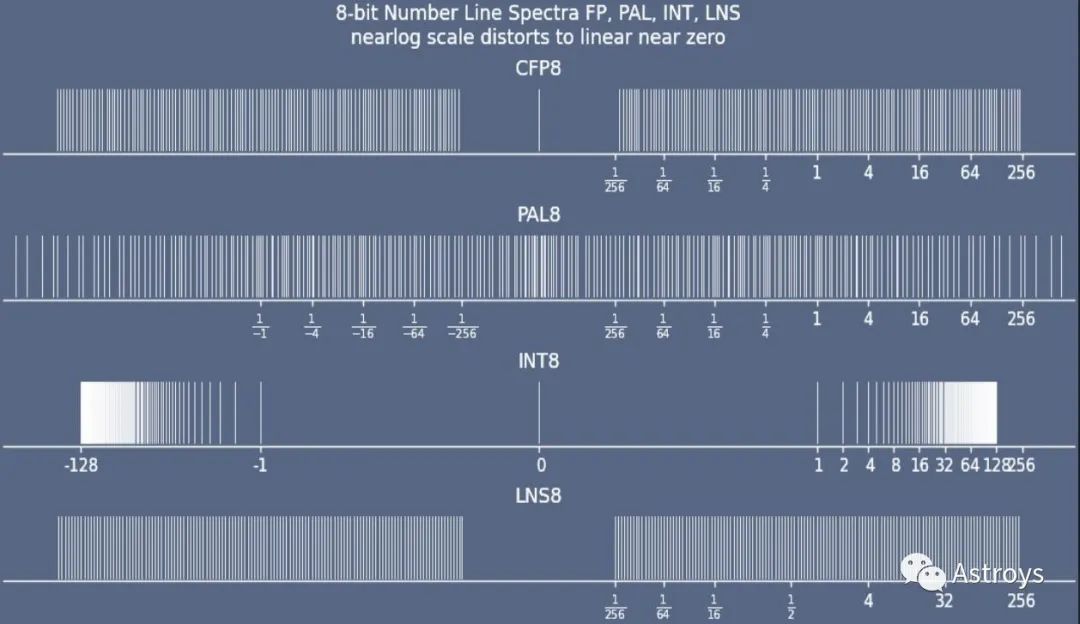
比较各种数字格式的覆盖范围。与CFP8(configurable floating point 8)、INT8(integer 8)和现有LNS8(logarithmic number system 8)相比,Lemurian的8位对数数据类型PAL8在亚正常范围的覆盖率更高。
Dawani的联合创始人Vassil Dimitrov提出了一个想法,即通过使用多基数和多指数来扩展现有的LNS(logarithmic number system),该系统已在DSP中使用了几十年。
Dawani说:“我们交错表示多个指数,以重现浮点的精度和范围。这样就能提供更好的覆盖范围……它自然而然地形成了一个锥形轮廓,在重要的地方,即在亚正常范围内,具有非常高的精度带。” 这个精度带可以进行偏置,以覆盖所需的区域,这与浮点运算的原理类似,但Dawani说,它允许对偏置进行比浮点运算更精细的控制。
Lemurian开发了从PAL2到PAL64的PAL格式,其中14位格式与BF16相当。与FP8相比,PAL8的精度提高了约一个比特,大小约为INT8的1.2倍。Dawani希望其它公司也能采用这些格式。
他说:“我希望更多的人使用它,因为我认为是时候摆脱浮点运算了。PAL可以应用于目前浮点运算的任何应用,从DSP到HPC以及两者之间,而不仅仅是AI,尽管这是我们目前的重点。我们更有可能与其它为这些应用构建芯片的公司合作,帮助他们采用我们的格式。”
对数加法器
由于对数加法器简化了乘法运算,因此在大部分为乘法运算的DSP工作负载中,对数加法器已使用了很长时间。LNS表示的两个数的乘法就是这两个对数的加法。然而,将两个LNS数字相加却比较困难。DSP传统上使用LUT (large lookup table) 来实现加法运算,虽然效率相对较低,但如果所需的大部分运算都是乘法运算,这种方法已经足够好了。
对于AI工作负载来说,矩阵乘法需要乘法和加法。Dawani说,Lemurian的秘诀之一就是“在硬件上解决了对数加法”。
他说:“我们完全摒弃了LUT,创建了一个纯对数加法器。我们有一个比浮点精确得多的精确加法器。我们仍在进行更多优化,看看能否使它更便宜、更快速。它的PPA(power, performance, area)已经比FP8高出两倍多。” Lemurian已经为这款加法器申请了多项专利。
他说:“DSP界以研究工作负载并从数值上理解它在寻找什么著称,然后加以利用并将其转化为芯片。这与我们正在做的事没有什么不同。我们并没有构建一个只做一件事的ASIC,而是研究了整个神经网络空间的数值,并构建了一个具有适度灵活性的特定领域架构。”
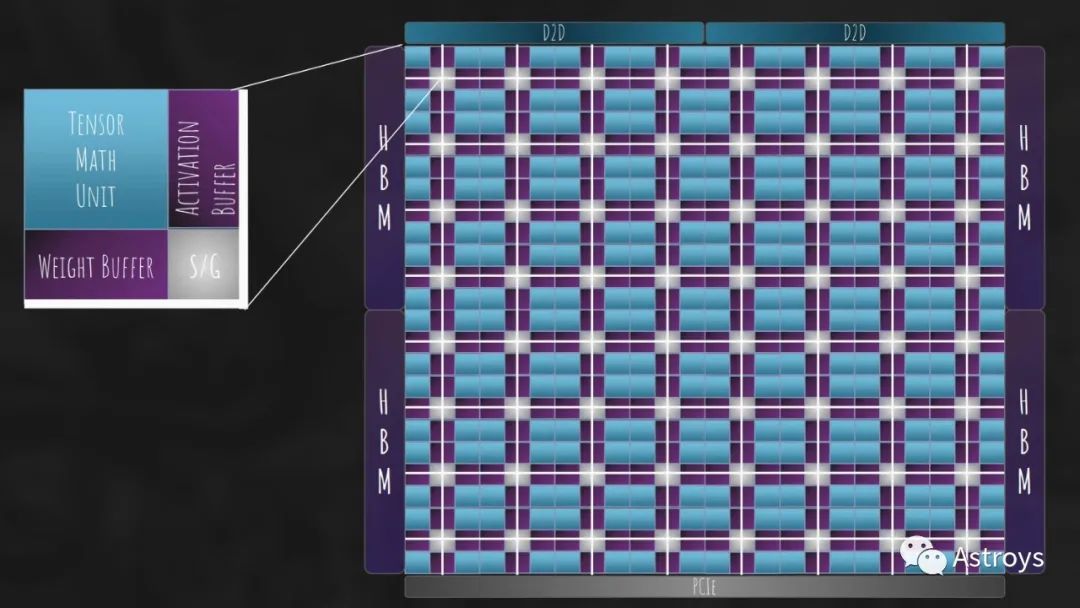
Lemurian数据流架构的高级视图。该芯片是围绕该公司的对数数字系统设计的。
软件堆栈
以高效的方式实现PAL格式需要硬件和软件。
Dawani说:“我们花了很多心思去思考如何让硬件更容易编程,因为除非你能首先提高工程师的生产力,否则任何架构都不会成功。我宁愿有一个糟糕的硬件架构和一个优秀的软件堆栈,而不是相反。”
他说,Lemurian在开始考虑硬件架构之前,就已经构建了大约40%的编译器。如今,Lemurian的软件堆栈已经开始运行,Dawani希望保持它的完全开放性,这样用户就可以编写自己的内核和融合程序。
软件堆栈包括Lemurian的混合精度对数量化器Paladynn,它可以将浮点和整数工作负载映射到PAL格式,同时保持精度。
他说:“我们采用了神经架构搜索中的许多想法,并将其应用于量化,因为我们想让这部分变得简单。”
Dawani说,虽然卷积神经网络的量化相对容易,但transformer却并非如此。激活函数中存在异常值,需要更高的精度,因此transformer总体上可能需要更复杂的混合精度方法。不过,Dawani说,他正在关注多项研究工作,这些工作表明,到Lemurian的芯片上市时,transformer可能就不再流行了。
未来的AI工作负载可能会遵循Google的Gemini等公司设定的路径,即运行非确定的步数。他说,这打破了大多数硬件和软件堆栈的假设。
他说:“如果你事先不知道你的模型需要运行多少步,你该如何安排它,你需要在多少计算上安排它?你需要的是更动态的东西,这影响了我们的很多想法。”
该芯片将是一款300W的数据中心加速器,配备128GB HBM3,可提供3.5POPS的密集算力(稀疏性将稍后推出)。总体而言,Dawani的目标是打造一款性能优于H100的芯片,并使其价格与Nvidia上一代A100相当。目标应用包括内部AI服务器(任何行业)和一些二级或专业云公司(非超大规模公司)。
审核编辑:刘清
-
dsp
+关注
关注
561文章
8277浏览量
368490 -
HPC
+关注
关注
0文章
350浏览量
25083 -
GPU芯片
+关注
关注
1文章
307浏览量
6563 -
AI芯片
+关注
关注
17文章
2168浏览量
36871
原文标题:DSP数学能否在AI领域战胜GPU?
文章出处:【微信号:Astroys,微信公众号:Astroys】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
GPU不是AI的唯一解:英伟达用Groq LPU证明,推理赛道需要“另一条腿”

想請教一下,在哪兒可以找到教材,使用Mixly 來作進一步修改AI 小智聊天機寸的程式在ESP32 開發板
重磅合作!Quintauris 联手 SiFive,加速 RISC-V 在嵌入式与 AI 领域落地
AI硬件全景解析:CPU、GPU、NPU、TPU的差异化之路,一文看懂!

如何看懂GPU架构?一分钟带你了解GPU参数指标




评论