 迈尔微视MRDVS发布多模态避障相机S2
迈尔微视MRDVS发布多模态避障相机S2

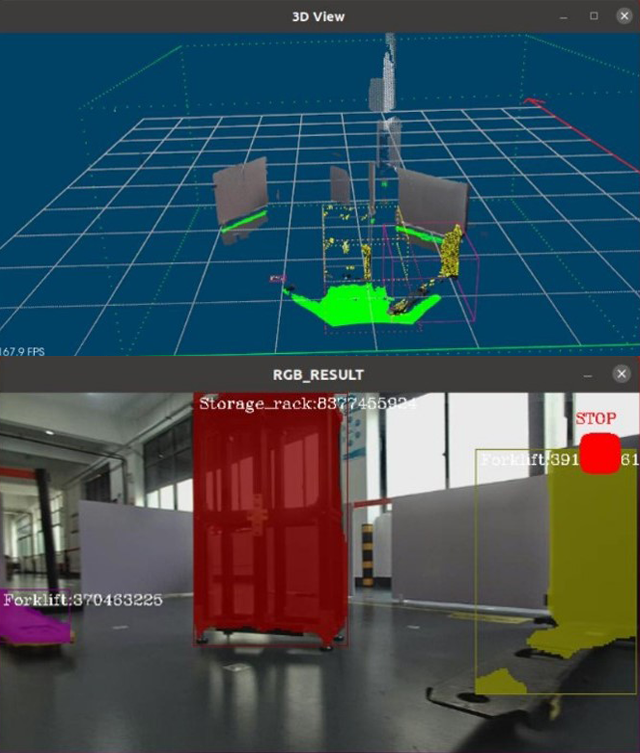
S2是迈尔微视MRDVS专为移动机器人避障应用研发的工业级多模态相机。通过获取前方障碍物距离及纹理信息,结合AI算法对障碍物进行识别分类,提升移动机器人避障准确性。
S2
多模态避障相机
轻巧尺寸,不可小觑
S2设计紧凑,仅120g重,可安装在各类移动机器人实现避障应用。
超广视野,一眼即知 90°*70°、120°*30°视野角度可选,灵敏探测3D范围内的障碍物。

环境在变,清晰不变
940nm光源,可在100Klux强光下正常运行,应用环境不设限。
网口传输,稳定可靠
传输距离远,安装不受限。
S2
避障能力全面升级
全面守护,全能适配 专为移动机器人打造,适配多种AGV/AMR车型。
3D视野,更安全
可探测3D范围内障碍物,有效提升移动机器人安全性能。
AI决策,更智能
语义识别:智能识别人、物体信息,分类形成避障方案。
目标追踪:跟踪动态障碍物,预判潜在风险。
作为移动机器人3D视觉专家,迈尔微视立足客户需求以3D视觉+AI算法,赋能移动机器人。
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
移动机器人
+关注
关注
2文章
820浏览量
34948 -
3D视觉
+关注
关注
4文章
493浏览量
29334
原文标题:迈尔微视MRDVS发布多模态避障相机S2
文章出处:【微信号:robotinside2014,微信公众号:移动机器人产业联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
调整语调匹配用户情绪。
2. 医疗影像诊断:图像+文本的多模态分析
图像编码 :用ResNet提取CT影像的病灶特征,生成1024维视觉向量。
文本编码 :用BioBERT处理电子病历中的症状描述,生成
发表于 05-01 17:46
TOF激光雷达在汽车避障上的应用
ToF激光雷达已成为L2+至L4级自动驾驶避障的必选硬件,尤其在AEB、自动泊车、盲区监测、全天候安全上不可替代。随着固态dToF成本下探与量产普及,正从高端车型快速下探至主流乘用车,成为汽车安全的“第三只眼”。

汽车多摄像头系统利器:S2D13P04相机接口IC
汽车多摄像头系统利器:S2D13P04相机接口IC 在汽车电子领域,多摄像头系统的应用越来越广泛,对于相机接口IC的需求也日益增长。今天就来
固态激光雷达参数以及避障视频
Class I 安全标准
➢ 使用寿命 10000h
1.2 应用场景
➢ 机器人避障
➢ 智能设备避障
➢ 家用服务机器人/扫地机器人的导航及避
发表于 03-27 14:14
无人机激光避障和360度避障哪个好?
无人机激光避障和360度避障没有绝对的”更好“之分,预算允许,优先选择同时搭载激光雷达和全向视觉的无人机,安全性能最强。

浅析未来三年无人机避障雷达的发展方向
未来三年(2026–2029),无人机避障雷达将围绕4D 成像化、AI 深度融合、多传感器协同、极致小型化低功耗、全天候与标准化五大方向快速迭代,核心目标是实现全天候、全向、高精度、低延迟、低成本的自主

无人机动态环境自适应避障系统平台的应用与未来发展
无人机动态环境自适应避障系统平台的应用与未来发展 北京华盛恒辉无人机动态环境自适应避障系统是一种融合多传感器感知、智能决策与实

商汤科技正式发布并开源全新多模态模型架构NEO
商汤科技正式发布并开源了与南洋理工大学S-Lab合作研发的全新多模态模型架构 —— NEO,为日日新SenseNova 多

核心剖析:Vitrox S2 EX与QX1的扫描技术路径及其衍生优势
在3D AXI领域,扫描方式是决定设备性能根基的核心。Vitrox的S2 EX与QX1在扫描策略上的根本性差异,直接导致了二者在吞吐能力与洞察深度上的分野。理解其扫描原理,是厘清其应用场景的关键
盘点割草机器人六大避障传感器
电子发烧友网综合报道 割草机器人的避障技术是其智能化水平的核心体现,主要通过传感器技术、环境感知算法和路径规划方法实现安全、高效的自主作业。随着智能化水平提升,割草机器人避障正从单一传
AGV机器人如何实现毫秒级避障?深度解析多传感器融合的核心技术
一、AGV多传感器融合实时避障系统介绍 1.简介 传感器融合技术是机器人实现全覆盖避障的关键,其原理仿效人脑综合处理信息的方式:通过协调多种



评论