 NeurIPS 2023 | 全新的自监督视觉预训练代理任务:DropPos
NeurIPS 2023 | 全新的自监督视觉预训练代理任务:DropPos


论文标题:
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions
论文链接:https://arxiv.org/pdf/2309.03576
代码链接:https://github.com/Haochen-Wang409/DropPos
今天介绍我们在自监督视觉预训练领域的一篇原创工作,目前 DropPos 已被 NeurIPS 2023 接收,相关代码已开源,有任何问题欢迎在 GitHub 提出。

TL;DR
我们提出了一种全新的自监督代理任务 DropPos,首先在 ViT 前向过程中屏蔽掉大量的 position embeddings(PE),然后利用简单的 cross-entropy loss 训练模型,让模型重建那些无 PE token 的位置信息。这个及其简单的代理任务就能在多种下游任务上取得有竞争力的性能。

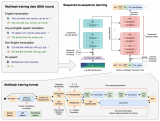
Motivation
在 MoCo v3 的论文中有一个很有趣的现象:ViT 带与不带 position embedding,在 ImageNet 上的分类精度相差无几。

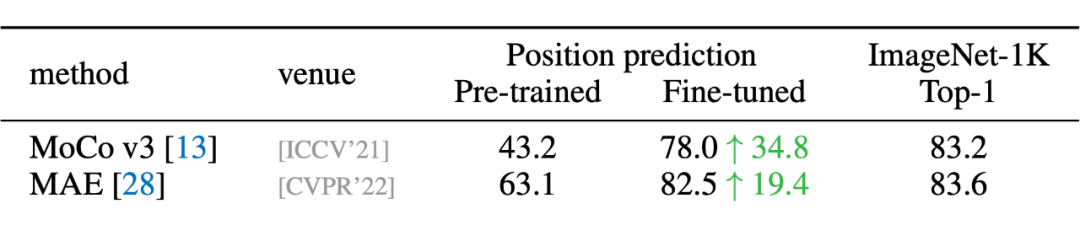
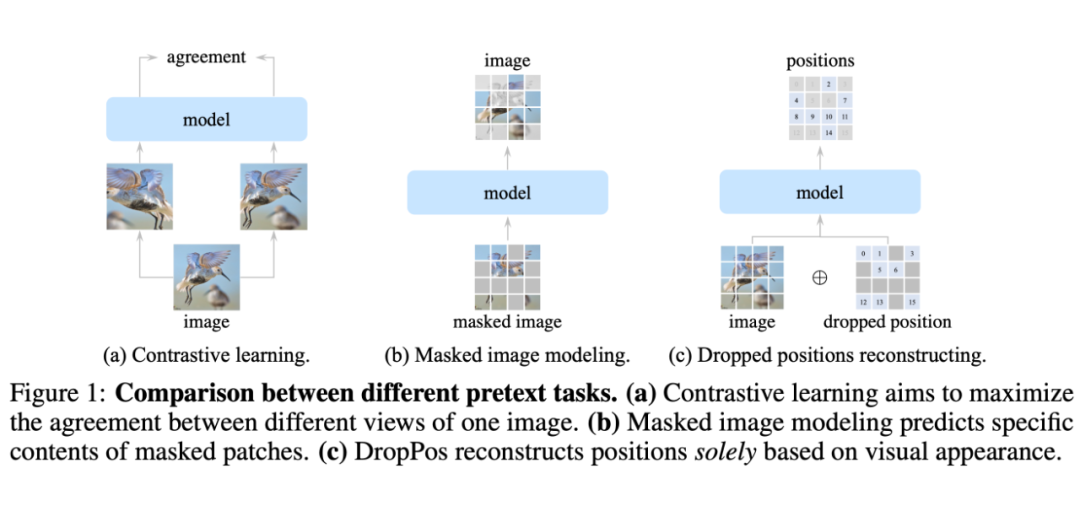
- 对比 CL,DropPos 不需要精心设计的数据增强(例如 multi-crop)。
- 对比 MIM,DropPos 不需要精心设计的掩码策略和重建目标。

Method

- 如果简单地把所有 PE 丢弃,让模型直接重建每个 patch 的位置,会导致上下游的 discrepency。因为下游任务需要 PE,而上游预训练的模型又完全没见过 PE。
- ViT 对于 long-range 的建模能力很强,这个简单的位置重建任务可能没办法让模型学到非常 high-level 的语义特征。
-
看上去相似的不同 patch(例如纯色的背景)的位置无需被精准重建,因此决定哪些 patch 的位置需要被重建非常关键。
- 针对问题一,我们采用了一个简单的随机丢弃策略。每次训练过程中丢弃 75% 的 PE,保留 25% 的 PE。
- 针对问题二,我们采取了高比例的 patch mask,既能提高代理任务的难度,又能加快训练的速度。
- 针对问题三,我们提出了 position smoothing 和 attentive reconstruction 的策略。
3.1 DropPos 前向过程

3.2 Objective
我们使用了一个最简单的 cross-entropy loss 作为预训练的目标函数:
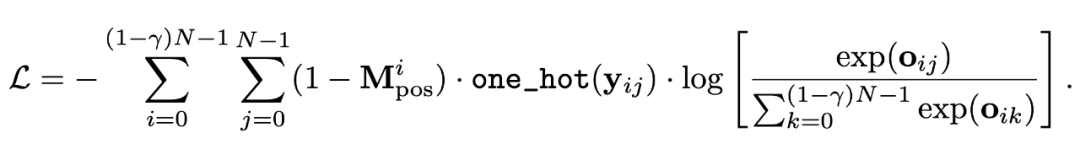
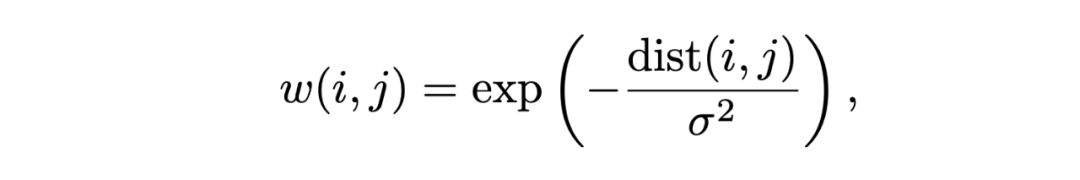
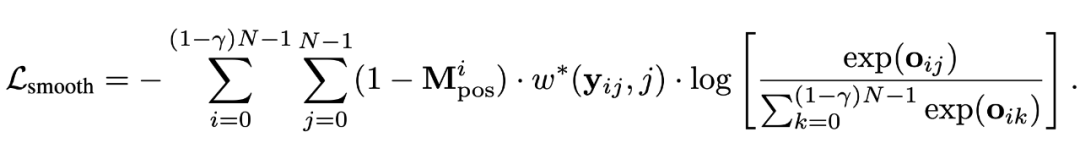 此处,w(i, j) 表示当真实位置为 i,而预测位置为 j 时,平滑后的 position target。
此外,我们还让 sigma 自大变小,让模型一开始不要过分关注精确的位置重建,而训练后期则越来越关注于精准的位置重建。
3.2.2 Attentive Reconstruction
我们采用 [CLS] token 和其他 patch 的相似度作为亲和力矩阵,作为目标函数的额外权重。
此处,w(i, j) 表示当真实位置为 i,而预测位置为 j 时,平滑后的 position target。
此外,我们还让 sigma 自大变小,让模型一开始不要过分关注精确的位置重建,而训练后期则越来越关注于精准的位置重建。
3.2.2 Attentive Reconstruction
我们采用 [CLS] token 和其他 patch 的相似度作为亲和力矩阵,作为目标函数的额外权重。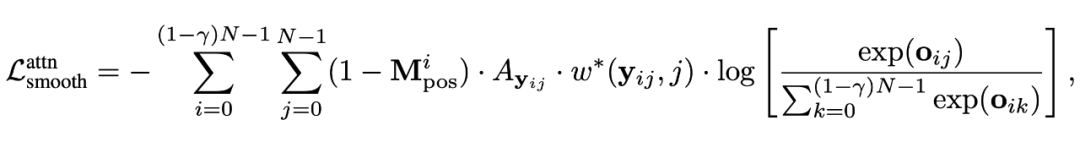
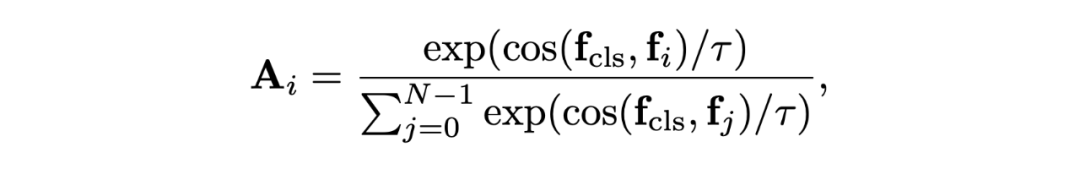 其中 f 为不同 token 的特征,tau 为超参数,控制了 affinity 的平滑程度。
其中 f 为不同 token 的特征,tau 为超参数,控制了 affinity 的平滑程度。

Experiments
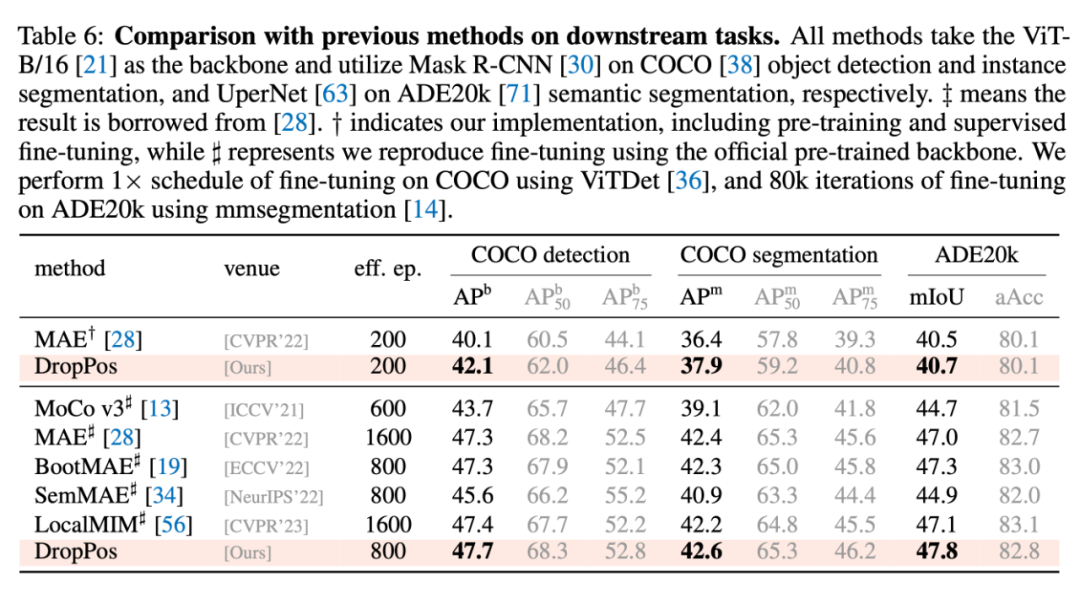
4.1 与其他方法的对比

4.2 消融实验
本文主要有四个超参:patch mask ratio(gamma),position mask ratio(gamma_pos),sigma,和 tau。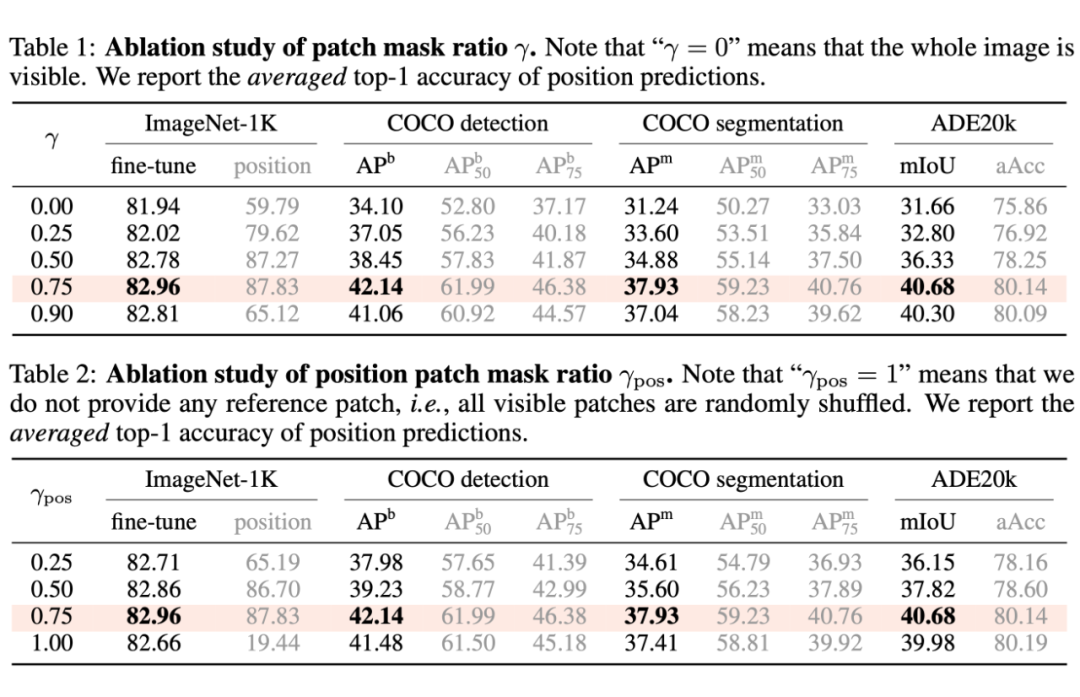
 由表,我们可以得出一些比较有趣的结论:
由表,我们可以得出一些比较有趣的结论:
- 一般来说,更高的 position 重建精度会带来更高的下游任务性能。
- 上述结论存在例外:当 sigma = 0 时,即不做位置平滑时,位置预测精度高,而下游任务表现反而低;当 tau = inf 时,即不做 attentive reconstruction 时,位置预测精度高,而下游表现反而低。
-
因此,过分关注于预测每一个 patch 的精确的位置,会导致局部最优,对于下游任务不利。

原文标题:NeurIPS 2023 | 全新的自监督视觉预训练代理任务:DropPos
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2951文章
48267浏览量
419654
原文标题:NeurIPS 2023 | 全新的自监督视觉预训练代理任务:DropPos
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
百度发布文心5.1:预训练成本降至行业6%
5月9日,百度正式发布新一代基础大模型文心5.1。该模型基于百度自研的"多维弹性预训练"技术,在大幅压缩参数规模的同时,实现了基础能力的显著提升。目前,文心5.1已在百度千帆模型广场及文心一言官网同步上线,面向企业用户与开发者开
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
标注的图文对(如网页中的图片和alt文本)进行自监督训练。
多实例学习 :将同一场景的多模态数据视为一个\"包\",只需标注包的类别,无需标注每个模态的具体对应关系。
2. 计算资源
发表于 05-01 17:46
人工智能多模态与视觉大模型开发实战 - 2026必会
和训练,模型可以逐渐提升对图像的理解能力,实现对各种视觉任务的精准处理。
此外,视觉大模型的发展还得益于大规模数据集和强大计算资源的支持。海量标注数据为模型提供了丰富的学习样本,使其能
发表于 04-15 16:06
NVIDIA Vera Rubin平台开启代理式AI前沿
七款全新芯片全面投产,旨在通过为 AI 各阶段(从预训练、后训练、测试时扩展,到智能体式推理)提供全面优化的可配置 AI 基础设施,扩展全球最大 AI 工厂的规模。
数据传输拖慢训练?三维一体调度让AI任务提速40%
、模型三者割裂,资源调度与数据流转不同步,训练任务频繁卡顿;更无奈的是,优化了算法、升级了硬件,却因底层传输与调度低效,始终无法突破训练效率瓶颈。 在AI模型规模越来越大、数据量呈爆炸式增长的今天,数据传输与资源协同效率,早已
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
、GPU加速训练(可选)
双轨教学:传统视觉算法+深度学习方案全覆盖
轻量化部署:8.6M超轻OCR模型,适合嵌入式设备集成
无监督学习:无需缺陷样本即可训练高精度检测模型
持续更新:
发表于 12-04 09:28
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
、GPU加速训练(可选)
双轨教学:传统视觉算法+深度学习方案全覆盖
轻量化部署:8.6M超轻OCR模型,适合嵌入式设备集成
无监督学习:无需缺陷样本即可训练高精度检测模型
持续更新:
发表于 12-03 13:50
思必驰与上海交大联合实验室五篇论文入选NeurIPS 2025
近日,机器学习与计算神经科学领域全球顶级学术顶级会议NeurIPS 2025公布论文录用结果,思必驰-上海交大联合实验室共有5篇论文被收录。NeurIPS(Conference on Neural
基于大规模人类操作数据预训练的VLA模型H-RDT
近年来,机器人操作领域的VLA模型普遍基于跨本体机器人数据集预训练,这类方法存在两大局限:不同机器人本体和动作空间的差异导致统一训练困难;现有大规模机器人演示数据稀缺且质量参差不齐。得益于近年来VR

信捷视觉平台全新升级
当机器视觉的精准遇上AI的智能,会碰撞出怎样的火花?信捷视觉平台全新升级——XINJE VISION STUDIO 3.7 + Vision AI算法平台双剑合璧,覆盖从规则化检测到复杂场景分析的全链路需求,助力多行业智造升级!
科通技术与RealSense签署代理协议
近日,科通技术与RealSense, Inc.正式签署代理协议,成为其中国区代理商。此次合作标志着双方在3D视觉领域的战略布局迈入新阶段。
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
1Whisper简介Whisper是OpenAI开源的,识别语音识别能力已达到人类水准自动语音识别系统。Whisper作为一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在

EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
Whisper是OpenAI开源的,识别语音识别能力已达到人类水准自动语音识别系统。Whisper作为一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。
CPU密集型任务开发指导
CPU密集型任务是指需要占用系统资源处理大量计算能力的任务,需要长时间运行,这段时间会阻塞线程其它事件的处理,不适宜放在主线程进行。例如图像处理、视频编码、数据分析等。
基于多线程并发机制处理CPU
发表于 06-19 06:05



评论