 基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?
基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?

 论文标题:Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts
论文标题:Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts论文链接:
https://openreview.net/forum?id=j8IiQUM33s
此外,团队还提出了一种名为混合自编码器 (MixedAE) 的简单而有效的方法,将图像混合应用于 MAE 数据增强。MixedAE 在各种下游任务(包括图像分类、语义分割和目标检测)上实现了最先进的迁移性能,同时保持了显著的效率。这是第一个从任务设计的角度将图像混合作为有效数据增强策略应用于基于纯自编码器结构的 Masked Image Modeling (MIM) 的研究。该工作已被 CVPR 2023 会议接收。

论文链接:
https://arxiv.org/abs/2303.17152
研究背景
在机器学习领域,预训练模型已经成为一种流行的方法,可以提高各种下游任务的性能。然而,研究发现,自监督预训练存在的负迁移现象。诺亚 AI 基础理论团队的前期工作 SDR (AAAI 2022) [1] 首次指出自监督预训练的负迁移问题,并提供初步解决方案。具体来说,负迁移是指在预训练过程中使用的数据与下游任务的数据分布不同,导致预训练模型在下游任务上的性能下降。在自监督学习中,模型在无标签数据上进行预训练,学习数据的潜在特征和表示。然而,当预训练数据与下游任务的数据分布存在显著差异时,模型可能学到与下游任务无关或甚至有害的特征。
 相关工作1. 自监督预训练的负迁移现象
相关工作1. 自监督预训练的负迁移现象
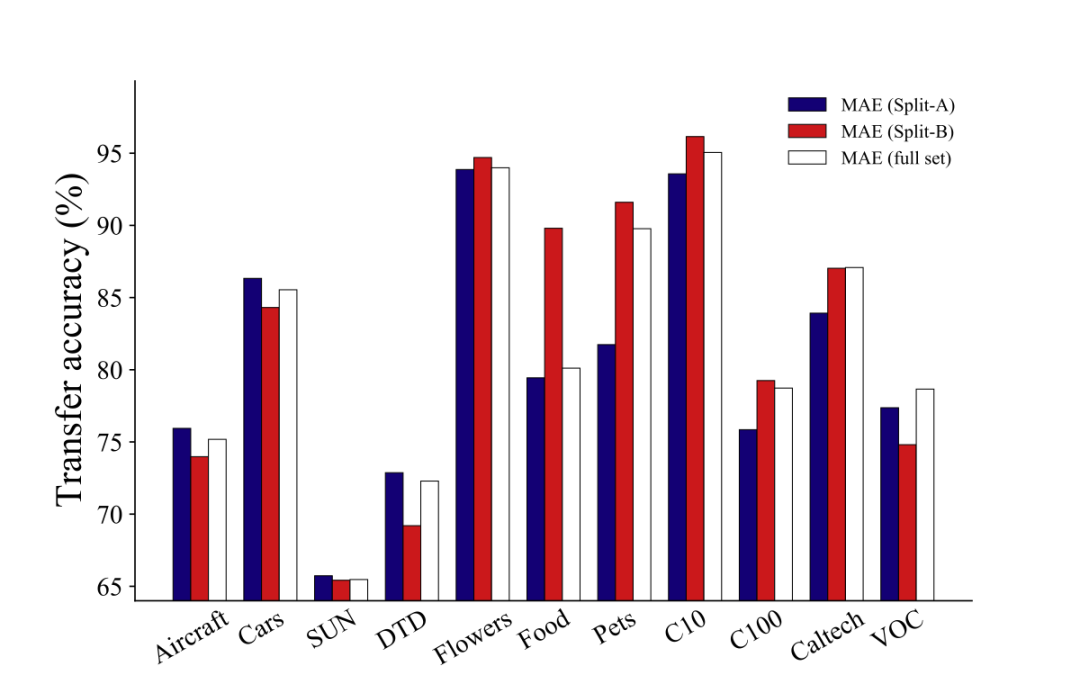
▲图一:我们用ImageNet的两个子集,Split-A和Split-B,训练两个MAE模型,和全量数据集训练的模型相比较,后者仅在2个数据集上达到了最优。这说明,增大数据量并不总是带来更强的迁移效果。
以目前较为流行的自监督学习算法 MAE 为例,我们评估了使用不同语义数据进行预训练的 MAE 模型在迁移性能上的表现。我们将 ImageNet 数据集分为两个不相交的子集 Split-A 和 Split-B,根据 WordNet 树中标签的语义差异进行划分。Split-A 主要包含无生命物体(如汽车和飞机),而 Split-B 则主要涉及有机体(如植物和动物)。接着,我们在 Split-A、Split-B 和完整的 ImageNet 数据集上分别进行了 MAE 预训练,并在 11 个下游任务上评估了这三个模型的性能。如图一所示,在仅含 2 个语义丰富数据集(Caltech,VOC)的情况下,基于完整 ImageNet 训练的 MAE 获得了最佳的迁移效果;在非生物下游数据集 (Aircraft,Cars,SUN,DTD) 上,Split-A 的表现更佳;而在包含 Flowers,Food,Pets,CIFAR10,CIFAR100 等数据集上,Split-B 的表现更优。这表明,当下游任务与预训练数据分布不同时,与任务无关的预训练信息可能导致负迁移,从而限制了 MAE 模型的可扩展性。换言之,若一个 MAE 模型的预训练数据去除了与下游任务数据集相似度较低的部分,则其性能可能优于包含这些无关数据的预训练模型。这突显了开发针对特定下游任务的定制化预训练方法以避免负迁移现象的重要性。2. 自监督数据增强难题在自监督预训练中,与依赖数据增强的对比学习不同,我们发现传统数据增强手段可能会削弱 MAE 的模型性能。以图像混合增强(Image Mixing)为例,设随机变量 X1 和 X2 表示两个输入图像,M 表示随机生成的掩码,我们可以证明混合输入 σmix({X1,X2},M) 与重构目标 X1 之间的互信息 (MI) 不小于 MAE 输入 σmae(X1,M) 与 X1 之间的互信息(详见论文附录)。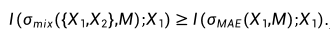 因此,简单的图像混合增强会提升模型输入与重构目标之间的互信息。尽管这对监督学习和对比学习有益,但它却简化了 MAE 的图像重构任务,因为掩码操作 (masking) 的根本目的恰恰是降低模型输入和重构目标之间的互信息,以减少图像信号的冗余。这表明以 MAE 为代表的掩码图像建模对数据增强具有与传统判别式训练范式不同的偏好,进而带来了 MAE 自监督学习中的数据增强难题。
因此,简单的图像混合增强会提升模型输入与重构目标之间的互信息。尽管这对监督学习和对比学习有益,但它却简化了 MAE 的图像重构任务,因为掩码操作 (masking) 的根本目的恰恰是降低模型输入和重构目标之间的互信息,以减少图像信号的冗余。这表明以 MAE 为代表的掩码图像建模对数据增强具有与传统判别式训练范式不同的偏好,进而带来了 MAE 自监督学习中的数据增强难题。
 方法1. MoCEMixture of Cluster-conditional Expert (MoCE) 通过数据聚类和显式地使用具有相似语义的图像来训练每个专家,以实现针对特定任务的定制自监督预训练。MoCE 的过程分为三个阶段,具体如下:1. 首先,我们使用预先训练好的 MAE 模型对整个数据集进行聚类。每张图片被分到不同的聚类中,并记录每个聚类的中心点,形成矩阵 C。2. 然后,受 Mixture-of-Experts (MoE) 多专家模型的启发,我们构建了基于聚类先验的 MoCE 模型。与目前常用的视觉多专家模型将每个图像的 token 路由到某个专家不同,MoCE 让每个专家负责训练一组相似的聚类图片,使得每个专家在不同语义数据上得到显式训练。具体来说,现有的视觉多专家模型基于 ViT 构建,将原先某些 Transformer Block 中的单个 MLP 层扩展为多个 MLP 层,每个 MLP 被称作一个专家 (expert)。同时引入一个门控网络 (gate network),该门控网络决定每个 token 应该去往哪个专家。MoCE 多专家层的核心改变是门控网络的输入:
方法1. MoCEMixture of Cluster-conditional Expert (MoCE) 通过数据聚类和显式地使用具有相似语义的图像来训练每个专家,以实现针对特定任务的定制自监督预训练。MoCE 的过程分为三个阶段,具体如下:1. 首先,我们使用预先训练好的 MAE 模型对整个数据集进行聚类。每张图片被分到不同的聚类中,并记录每个聚类的中心点,形成矩阵 C。2. 然后,受 Mixture-of-Experts (MoE) 多专家模型的启发,我们构建了基于聚类先验的 MoCE 模型。与目前常用的视觉多专家模型将每个图像的 token 路由到某个专家不同,MoCE 让每个专家负责训练一组相似的聚类图片,使得每个专家在不同语义数据上得到显式训练。具体来说,现有的视觉多专家模型基于 ViT 构建,将原先某些 Transformer Block 中的单个 MLP 层扩展为多个 MLP 层,每个 MLP 被称作一个专家 (expert)。同时引入一个门控网络 (gate network),该门控网络决定每个 token 应该去往哪个专家。MoCE 多专家层的核心改变是门控网络的输入: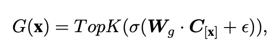 这里,C[x] 表示 token x 所属图片所在的聚类中心(我们在第一步已经完成了聚类),而不是原先的 token 嵌入。这样,属于同一个聚类的图片的 tokens 都会被路由到同一个专家,从而显式地区分每个专家在语义上的差异。为了稳定训练并增强门控网络的置信度,我们提出了两个额外的正则化损失,并在实验中发现了它们的有效性。3. 当下游任务到达时,我们引入了一个搜索模块来选择最适合用于迁移学习的专家。具体而言,我们重复利用第一步提到的聚类模块,找到与下游数据集最相似的聚类,然后找到该聚类所训练的专家,将其单独提取出来,舍弃其他专家进行迁移。这样,在下游任务中,我们始终使用一个正常大小的 ViT 模型。2. MixedAEMixed Autoencoder (MixedAE) 提出辅助代理任务——同源识别(Homologous recognition),旨在显示要求每个图像块识别混合图像中的同源图像块以缓解图像混合所导致的互信息上升,从而实现物体感知的自监督预训练。MixedAE 的过程分为三个阶段,具体如下:1. 混合阶段:在给定混合系数 r 的情况下,将输入图像随机划分为不同的图像组,并根据 r 对每个图像组进行随机混合,生成混合图像。2. 识别阶段:鉴于 Vision Transformer 中全局自注意力的使用,在重构过程中,各个图像块不可避免地与来自其他图像的异源图像块发生交互,从而导致互信息的上升。因此我们提出同源自注意力机制 (Homologous attention),通过部署一个简单的 TopK 采样操作,要求每个图像块显示识别并仅与同源图像块做自注意力计算,以抑制互信息的上升。
这里,C[x] 表示 token x 所属图片所在的聚类中心(我们在第一步已经完成了聚类),而不是原先的 token 嵌入。这样,属于同一个聚类的图片的 tokens 都会被路由到同一个专家,从而显式地区分每个专家在语义上的差异。为了稳定训练并增强门控网络的置信度,我们提出了两个额外的正则化损失,并在实验中发现了它们的有效性。3. 当下游任务到达时,我们引入了一个搜索模块来选择最适合用于迁移学习的专家。具体而言,我们重复利用第一步提到的聚类模块,找到与下游数据集最相似的聚类,然后找到该聚类所训练的专家,将其单独提取出来,舍弃其他专家进行迁移。这样,在下游任务中,我们始终使用一个正常大小的 ViT 模型。2. MixedAEMixed Autoencoder (MixedAE) 提出辅助代理任务——同源识别(Homologous recognition),旨在显示要求每个图像块识别混合图像中的同源图像块以缓解图像混合所导致的互信息上升,从而实现物体感知的自监督预训练。MixedAE 的过程分为三个阶段,具体如下:1. 混合阶段:在给定混合系数 r 的情况下,将输入图像随机划分为不同的图像组,并根据 r 对每个图像组进行随机混合,生成混合图像。2. 识别阶段:鉴于 Vision Transformer 中全局自注意力的使用,在重构过程中,各个图像块不可避免地与来自其他图像的异源图像块发生交互,从而导致互信息的上升。因此我们提出同源自注意力机制 (Homologous attention),通过部署一个简单的 TopK 采样操作,要求每个图像块显示识别并仅与同源图像块做自注意力计算,以抑制互信息的上升。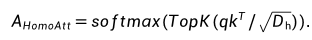 3. 验证阶段:为了验证同源自注意力的准确性,我们提出同源对比损失 (Homologous contrasitve)。对于任意查询图像块 (query patch),我们将其同源图像块视为正样本,异源图像块作为负样本,以促进同源图像块特征的相似度,从而显示要求图像块识别并仅和同源图像块做自注意力计算。最后,同源对比损失将和原始图像重构损失一起以多任务形式优化网络参数进行自监督预训练。
3. 验证阶段:为了验证同源自注意力的准确性,我们提出同源对比损失 (Homologous contrasitve)。对于任意查询图像块 (query patch),我们将其同源图像块视为正样本,异源图像块作为负样本,以促进同源图像块特征的相似度,从而显示要求图像块识别并仅和同源图像块做自注意力计算。最后,同源对比损失将和原始图像重构损失一起以多任务形式优化网络参数进行自监督预训练。

实验分析
1. MoCE我们在之前提到的 11 个下游分类数据集和检测分割任务上做了实验。实验结果表明,MoCE 在多个下游任务中的性能超过了传统的 MAE 预训练方法。具体而言,在图像分类任务中,MoCE 相较于 MAE 实现了更高的准确率。在目标检测和分割任务中,MoCE 也取得了更好的表现,包括更高的 mIoU 和 AP 指标。这些实验结果表明,MoCE 通过利用相似语义图像进行聚类并为每个专家进行任务定制的自监督预训练,能够在各种下游任务中提高迁移性能。
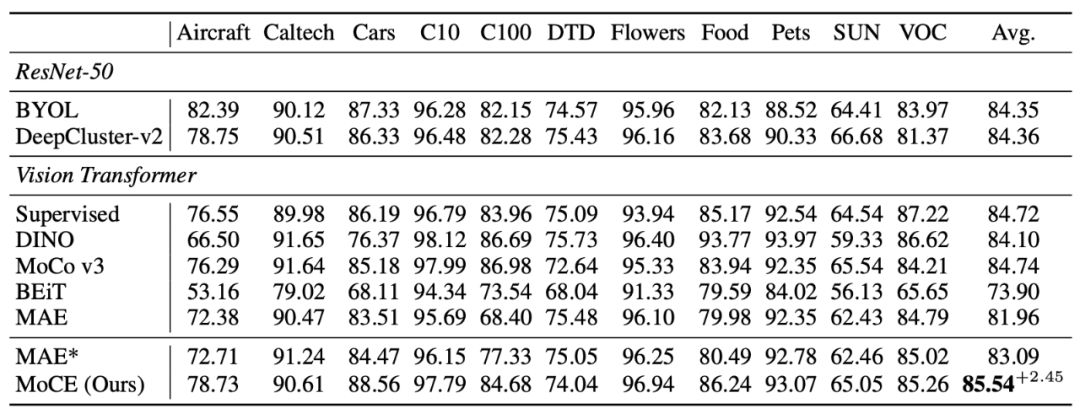 ▲表一:MoCE在细粒度数据集上有较大提升,在类别比较宽泛的任务上也有少量提升。2. MixedAE
▲表一:MoCE在细粒度数据集上有较大提升,在类别比较宽泛的任务上也有少量提升。2. MixedAE在 14 个下游视觉任务(包括图像分类、语义分割和物体检测)的评估中,MixedAE 展现了最优的迁移性能和卓越的计算效率。相较于 iBOT,MixedAE 实现了约 2 倍预训练加速。得益于图像混合所带来的物体感知预训练,MixedAE 在下游密集预测任务上取得更显著的性能提升。注意力图可视化结果表明,MixedAE 能比 MAE 更准确完整地识别图像前景物体,从而实现优异的密集预测迁移性能。
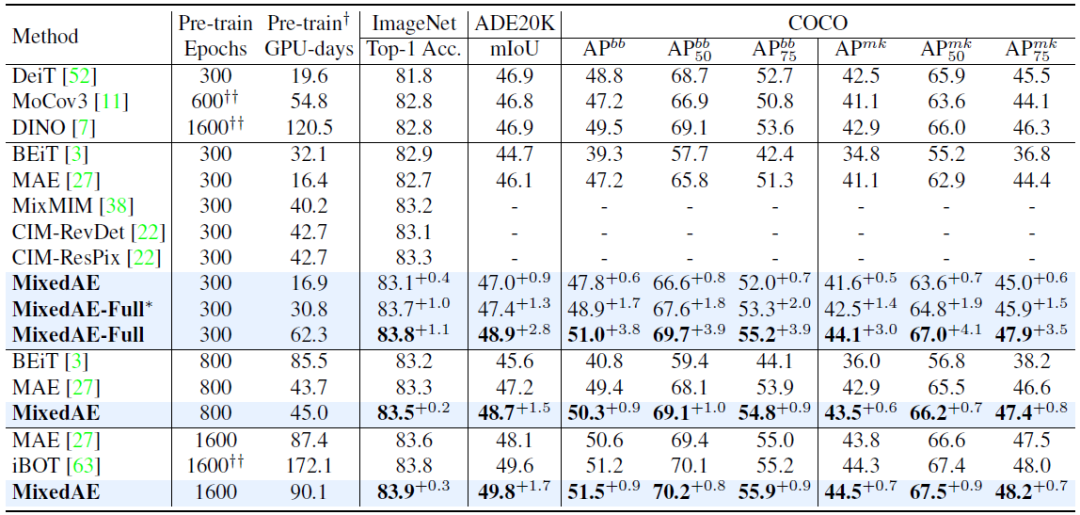 ▲表二:MixedAE在不同训练代价下均获得当前最优结果,展现了卓越的计算效率。
▲表二:MixedAE在不同训练代价下均获得当前最优结果,展现了卓越的计算效率。
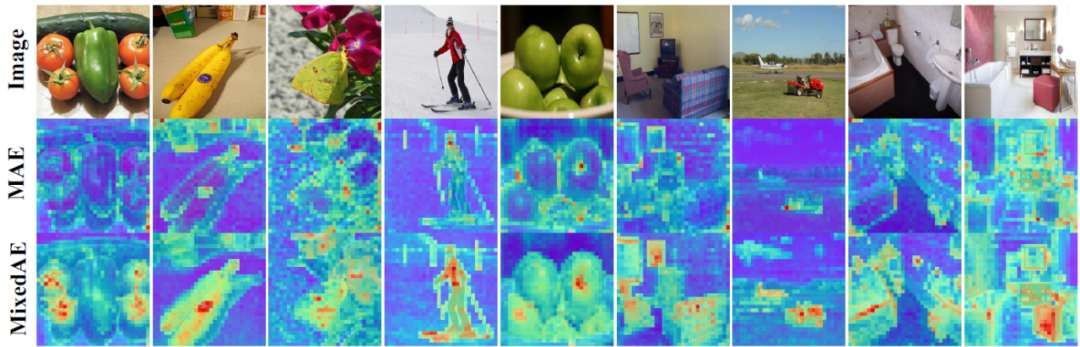
▲图二:注意力图可视化。得益于ImageNet的单实例假设[2]以及物体感知的自监督预训练,MixedAE可以更准确完整地发现图像前景物体,从而实现更好的密集预测迁移性能。
 作者介绍结合 MoCE 和 MixedAE 的研究发现,我们揭示了自监督预训练中数据之谜:数据量不再是唯一关键因素,而是如何利用数据和进行定制化预训练和数据增广更为关键。MoCE 通过数据聚类和专家定制训练,显著提高了针对特定下游任务的迁移性能。MixedAE 则通过一种简单有效的图像混合方法,实现了在各种下游任务中的最先进迁移性能。这些研究发现不仅为自监督预训练领域提供了新的视角,还为开发更为高效、可扩展和定制化的预训练方法提供了指导和启示。我们希望这些探索是一个有效利用更多数据量的途径,并为研究者们提供新的思路。
作者介绍结合 MoCE 和 MixedAE 的研究发现,我们揭示了自监督预训练中数据之谜:数据量不再是唯一关键因素,而是如何利用数据和进行定制化预训练和数据增广更为关键。MoCE 通过数据聚类和专家定制训练,显著提高了针对特定下游任务的迁移性能。MixedAE 则通过一种简单有效的图像混合方法,实现了在各种下游任务中的最先进迁移性能。这些研究发现不仅为自监督预训练领域提供了新的视角,还为开发更为高效、可扩展和定制化的预训练方法提供了指导和启示。我们希望这些探索是一个有效利用更多数据量的途径,并为研究者们提供新的思路。

参考文献
[1] Task-customized Self-supervised Pre-training with Scalable Dynamic Routing, AAAI 2022.
[2] MultiSiam: Self-supervised Multi-instance Siamese Representation Learning for Autonomous Driving, ICCV 2021.
·
原文标题:基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
-
物联网
+关注
关注
2951文章
48282浏览量
419769
原文标题:基础模型自监督预训练的数据之谜:大量数据究竟是福还是祸?
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
百度发布文心5.1:预训练成本降至行业6%
零基础手写大模型资料2026
AI Ceph 分布式存储教程资料大模型学习资料2026
HM博学谷狂野AI大模型第四期
Edge Impulse 唤醒词模型训练 | 技术集结

求助:AI服务器SSD掉电数据丢失,12V电压暴跌至8.5V,这究竟是主控问题还是PLP电容ESR不够低?
什么是大模型,智能体...?大模型100问,快速全面了解!

自动驾驶大模型的训练数据有什么具体要求?

模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题

基于大规模人类操作数据预训练的VLA模型H-RDT

EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
嵌入式AI技术漫谈:怎么为训练AI模型采集样本数据
数据标注与大模型的双向赋能:效率与性能的跃升




评论