 ICCV 2023 | 面向视觉-语言导航的实体-标志物对齐自适应预训练方法
ICCV 2023 | 面向视觉-语言导航的实体-标志物对齐自适应预训练方法

本文是 ICCV 2023 入选 Oral 论文 Grounded Entity-Landmark Adaptive Pre-training for Vision-and-Language Navigation 的解读。本论文是某智能人机交互团队在视觉-语言导航(Vision-and-Language Navigation, VLN)领域的最新工作。该工作构建了 VLN 中首个带有高质量实体-标志物对齐标注的数据集,并提出实体-标志物对齐的自适应预训练方法,从而显著提高了智能体的导航性能。
ICCV 是“计算机视觉三大顶级会议”之一,ICCV 2023 于今年 10 月 2 日至 6 日在法国巴黎举行,本届会议共收到全球 8260 篇论文投稿,2161 篇被接收,接收率为 26.16%,其中 152 篇论文被选为口头报告展示(Oral Presentation),Oral 接收率仅为 1.8%。

论文题目:
Grounded Entity-Landmark Adaptive Pre-training for Vision-and-Language Navigation
论文地址:
https://arxiv.org/abs/2308.12587开源数据集:
https://pan.baidu.com/s/12WTzZ05T8Uxy85znn28dfQ?pwd=64t7代码地址:
https://github.com/csir1996/vln-gela

引言
视觉-语言导航(Vision-and-Language Navigation, VLN)任务旨在构建一种能够用自然语言与人类交流并在真实 3D 环境中自主导航的具身智能体。自提出以来,VLN 越来越受到计算机视觉、自然语言处理和机器人等领域的广泛关注。 如图 1 所示,将自然语言指令中提过的标志物(物体或者场景)对应到环境中能够极大的帮助智能体理解环境和指令,由此跨模态对齐是 VLN 中的关键步骤。然而,大多数可用的数据集只能提供粗粒度的文本-图像对齐信号,比如整条指令与整条轨迹的对应或者子指令与子路径之间的对应,而跨模态对齐监督也都停留在句子级别(sentence-level)。因此,VLN 需要更细粒度(entity-level)的跨模态对齐数据和监督方法以促进智能体更准确地导航。
为解决以上问题,我们提出了一种面向 VLN 的实体-标志物自适应预训练方法,主要工作与贡献如下:
1. 我们基于 Room-to-Room(R2R)数据集 [1] 标注实体-标志物对齐,构建了第一个带有高质量实体-标志物对齐标注的 VLN 数据集,命名为 GEL-R2R;
2. 我们提出一种实体-标志物自适应预训练 (Grounded Entity-Landmark Adaptive,GELA) 方法,利用 GEL-R2R 数据集显式监督 VLN 模型学习实体名词和环境标志物之间的细粒度跨模态对齐;
3. 我们构建的 GELA 模型在两个 VLN 下游任务上取得了最佳的导航性能,证明了我们数据集和方法的有效性和泛化性。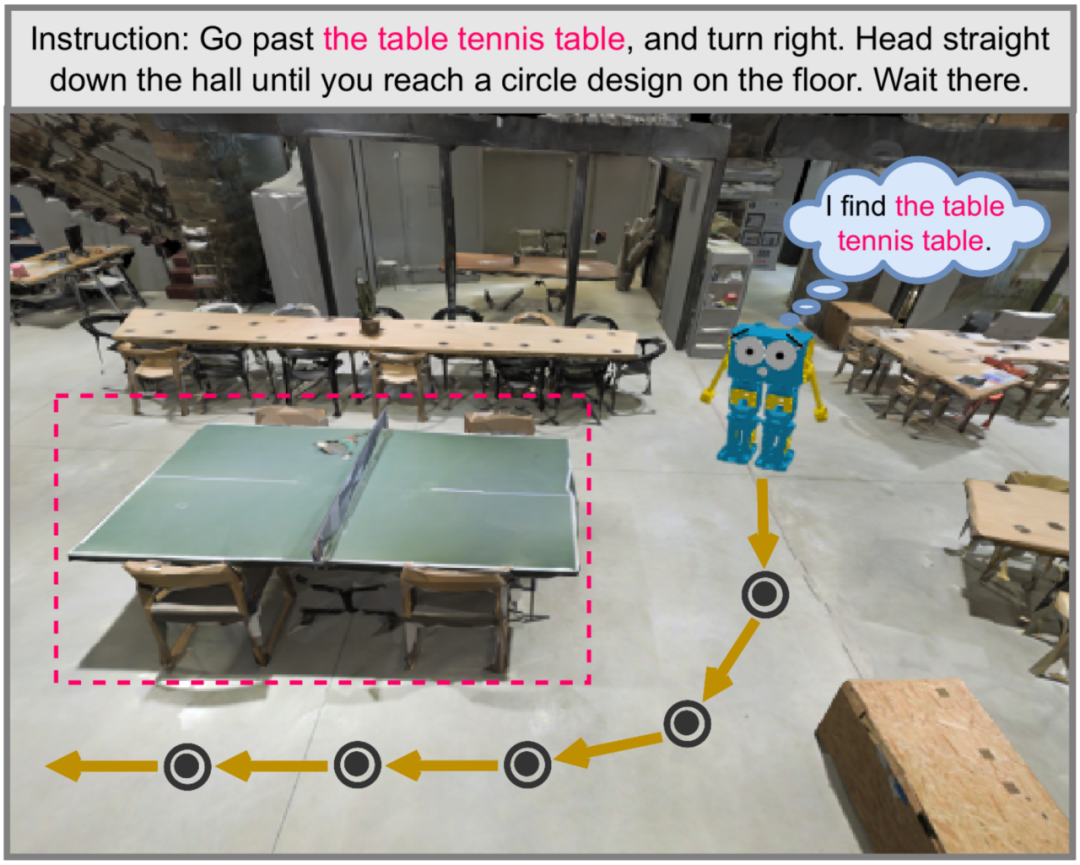 ▲图1. 具身智能体在3D真实环境中的导航示例
▲图1. 具身智能体在3D真实环境中的导航示例

GEL-R2R数据集
为了建立指令中实体短语与其周围环境中相应标志物之间的对齐,我们在 R2R 数据集的基础上进行了实体-标志物对齐的人工标注,整个流程包括五个阶段:
1. 原始数据准备。我们从 Matterport3D 模拟器中采集每个可导航点的全景图。为了提高标注的效率和准确性,我们在全景图中标注下一个动作方向,并根据 FG-R2R 数据集 [2] 将每个全景图与相应的子指令进行对应;
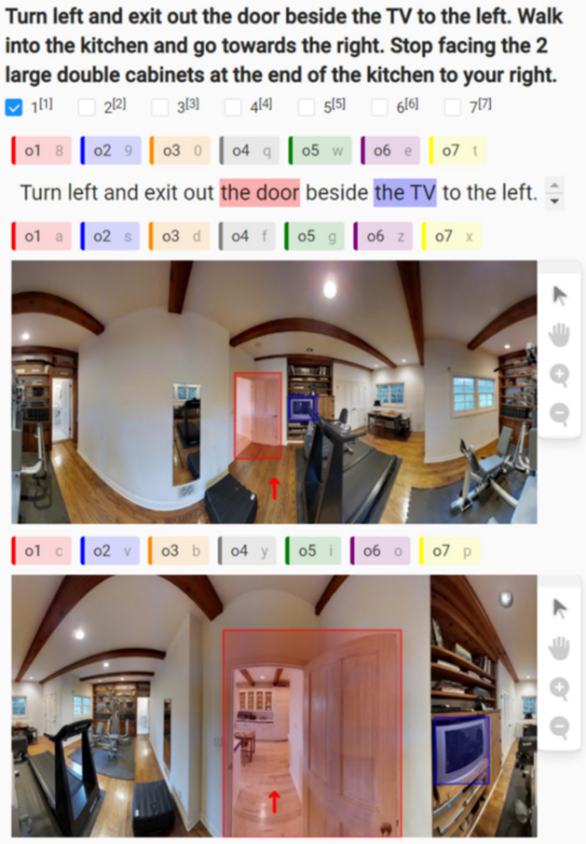
2. 标注工具开发。我们基于 Label-Studio 开发了一个跨模态标注平台,如图 2 所示;
3. 标注指南建立。为确保标注的一致性,我们经过预标注之后建立了四个准则来标准化标注指南:
-
对齐准则:指令中的实体短语应与全景图中的标志物准确匹配
-
自由文本准则:标注自由文本而不是类别
-
文本共指准则:指代相同标志物的实体短语用相同的标签标注
-
唯一标志物准则:对于一个实体短语,在全景图中只应标注一个对应的标志物
4. 数据标注与修订;
5. 数据整合与处理。
 ▲图3. GEL-R2R数据集统计分析
▲图3. GEL-R2R数据集统计分析

GELA方法
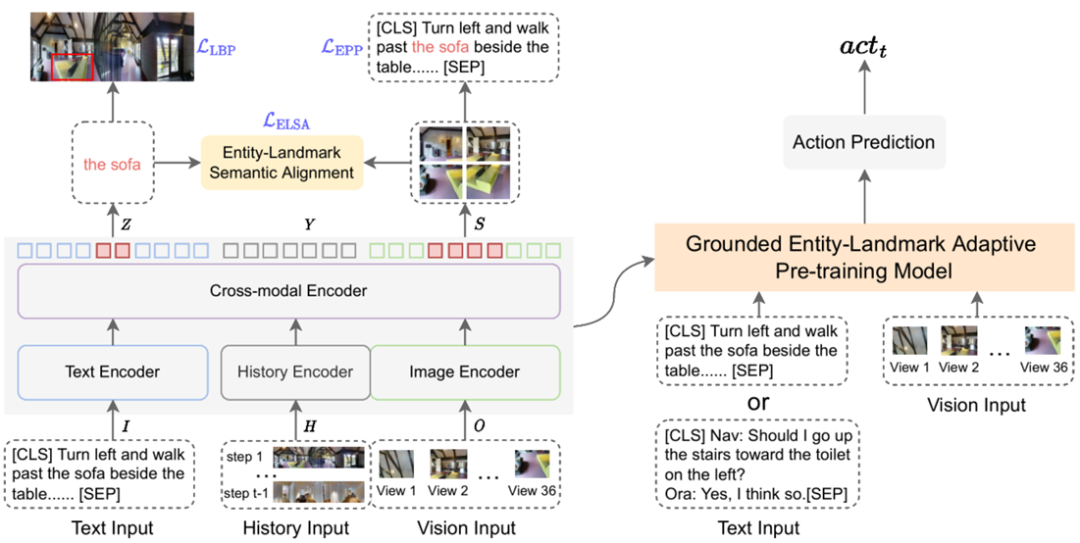 ▲图4. GELA方法概览
▲图4. GELA方法概览
如图 4 所示,方法流程分为三个阶段:预训练(pre-training)、自适应预训练(adaptive pre-training)和微调(fine-tuning)。我们直接在预训练模型 HAMT [3] 的基础上进行自适应预训练,HAMT 模型由文本编码器、图像编码器、历史编码器和跨模态编码器构成。我们将跨模态编码器输出的文本向量、历史向量和图像向量分别记为 Z、Y 和 S。我们设计了三种自适应预训练任务:
1. 实体短语预测。在这个任务中,我们通过标注的环境标志物预测其对应的实体短语在指令中的位置。首先将人工标注的实体位置转化为 L+1 维的掩码向量 (与 维度相同),并将人工标注的标志物边界框转化为 37 维的掩码向量 (与 维度相同)。然后,我们将标志物图像 patch 的特征平均化,并将其输入一个两层前馈网络(Feedforward Network, FFN)中,预测指令序列中 token 位置的概率分布,用掩码向量 作监督,具体损失函数为:
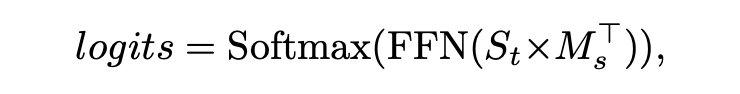

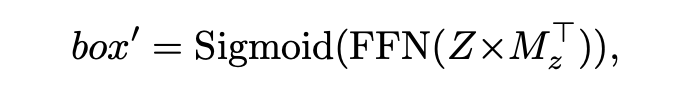
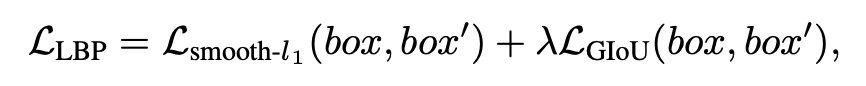
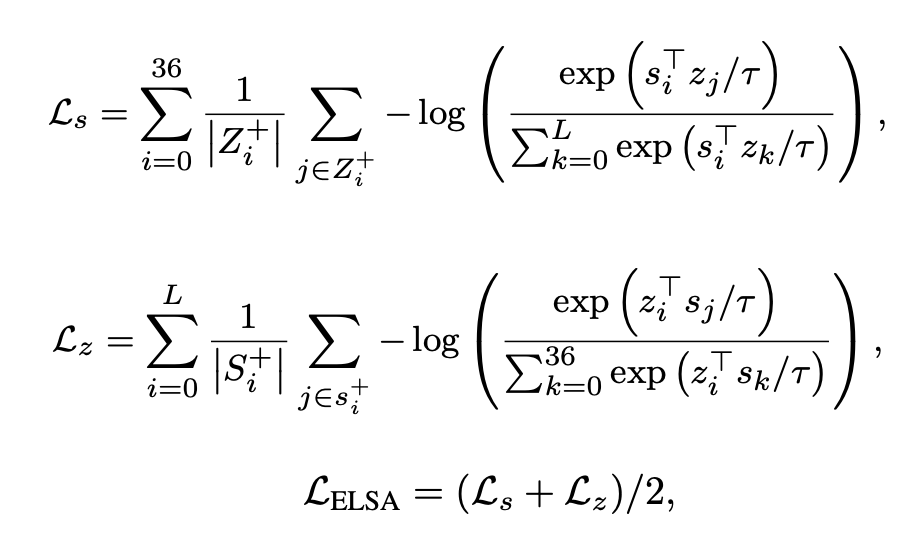 自适应预训练最终的损失函数为:
自适应预训练最终的损失函数为:
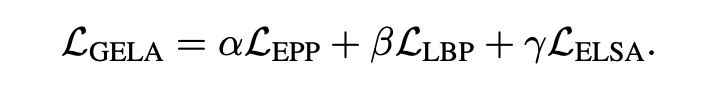

实验结果
如图 5 所示,GELA 模型在 R2R 数据集上与先前 SOTA 模型的性能进行比较。GELA 模型在所有子集上的主要指标(SR 和 SPL)均优于所有其他模型。具体地,在已知验证集上,GELA 的性能与 HAMT 模型相当,而在未知验证集和测试集上,GELA 模型分别取得了 5% 、2% (SR) 和 4% 、2% (SPL) 的提高。因此,GELA 模型具有更好的未知环境泛化能力,这主要是由于 GELA 模型在学习实体-标志物对齐后,具有较强的语义特征捕捉能力。
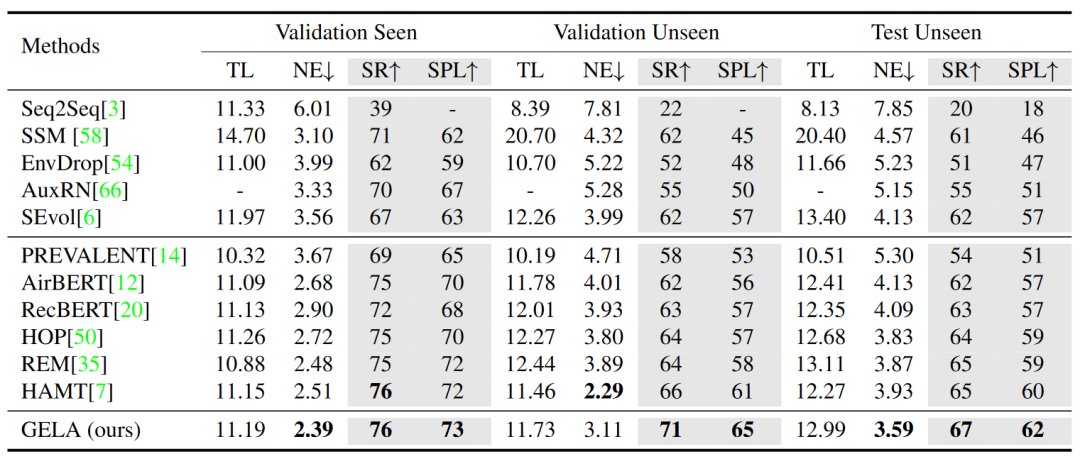 ▲ 图5. R2R数据集上的性能对比
我们同样在 CVDN 数据集上对比了 GELA 模型与先前 SOTA 模型的性能,如图 6 所示,该数据集使用以米为单位的目标进度 (Goal Progress,GP) 作为关键性能指标。结果表明,GELA 模型在验证集和测试集上的性能都明显优于其他模型。因此,GELA 模型对不同的 VLN 下游任务具有良好的泛化能力。
▲ 图5. R2R数据集上的性能对比
我们同样在 CVDN 数据集上对比了 GELA 模型与先前 SOTA 模型的性能,如图 6 所示,该数据集使用以米为单位的目标进度 (Goal Progress,GP) 作为关键性能指标。结果表明,GELA 模型在验证集和测试集上的性能都明显优于其他模型。因此,GELA 模型对不同的 VLN 下游任务具有良好的泛化能力。
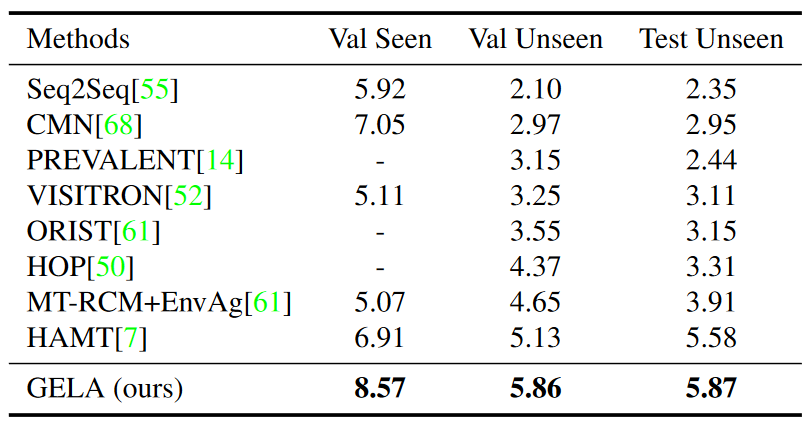 ▲图6. CVDN数据集上的性能对比
▲图6. CVDN数据集上的性能对比

参考文献
[1] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S ̈ underhauf, Ian D. Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In CVPR, pages 3674–3683, 2018.
[2] Yicong Hong, Cristian Rodriguez Opazo, Qi Wu, and Stephen Gould. Sub-instruction aware vision-and-language navigation. In EMNLP, pages 3360–3376, 2020.
[3] Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation. In NeurIPS, pages 58345847, 2021.
·
原文标题:ICCV 2023 | 面向视觉-语言导航的实体-标志物对齐自适应预训练方法
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
-
物联网
+关注
关注
2951文章
48303浏览量
419946
原文标题:ICCV 2023 | 面向视觉-语言导航的实体-标志物对齐自适应预训练方法
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
[GLAD] GLAD:大气像差与自适应光学
关于C语言对齐的一些总结
中南大学:新型生物传感器,精准检测cTnI和IL-6标志物

面向视觉语言导航的任务驱动式地图学习框架MapDream介绍

摩尔线程新一代大语言模型对齐框架URPO入选AAAI 2026

基于大规模人类操作数据预训练的VLA模型H-RDT

谷歌如何打造卓越自适应应用
基于FPGA LMS算法的自适应滤波器设计
无刷直流电机自适应模糊PID控制系统
CYW43907使用AP功能时是否具有自适应功能?
无刷直流电机双闭环模糊自适应控制方法研究
暨南大学:铁电极化调控的自供电、高灵敏PEC型肿瘤标志物传感技术



评论