 LoRA继任者ReLoRA登场,通过叠加多个低秩更新矩阵实现更高效大模型训练效果
LoRA继任者ReLoRA登场,通过叠加多个低秩更新矩阵实现更高效大模型训练效果

本文是一篇专注于减轻大型Transformer语言模型训练代价的工作。作者提出了一种基于低秩更新的ReLoRA方法。过去十年中深度学习发展阶段中的一个核心原则就是不断的“堆叠更多层(stack more layers),因此作者希望探索能否同样以堆叠的方式来提升低秩适应的训练效率,实验结果表明,ReLoRA在改进大型网络的训练方面更加有效。

论文链接: https://arxiv.org/abs/2307.05695 代码仓库: https://github.com/guitaricet/peft_pretraining
一段时间以来,大模型(LLMs)社区的研究人员开始关注于如何降低训练、微调和推理LLMs所需要的庞大算力,这对于继续推动LLMs在更多的垂直领域中发展和落地具有非常重要的意义。目前这一方向也有很多先驱工作,例如从模型结构上创新的RWKV,直接替换计算量较大的Transformer架构,改用基于RNN范式的新架构。还有一些方法从模型微调阶段入手,例如在原有LLMs中加入参数量较小的Adapter模块来进行微调。还有微软提出的低秩自适应(Low-Rank Adaptation,LoRA)方法,LoRA假设模型在任务适配过程中对模型权重的更新量可以使用低秩矩阵进行估计,因而可以用来间接优化新加入的轻量级适应模块,同时保持原有的预训练权重不变。目前LoRA已经成为大模型工程师必备的一项微调技能,但本文作者仍然不满足于目前LoRA所能达到的微调效果,并进一步提出了一种可叠加的低秩微调方法,称为ReLoRA。
本文来自马萨诸塞大学洛厄尔分校的研究团队,作者团队将ReLoRA应用在具有高达350M参数的Transformer上时,展现出了与常规神经网络训练相当的性能。此外,本文作者还观察到ReLoRA的微调效率会随着模型参数规模的增加而不断提高,这使得其未来有可能成为训练超大规模(通常超过1B参数)LLMs的新型手段。
一、引言虽然目前学术界和工业界都在不断推出自家的各种基座模型,但不可否认的是,完全预训练一个具有初等推理能力的LLMs仍然需要非常庞大的算力,例如大家熟知的LLaMA-6B模型[1]就需要数百个GPU才能完成训练,这种规模的算力已经让绝大多数学术研究小组望而却步了。在这种背景下,参数高效微调(PEFT)已经成为了一个非常具有前景的LLMs研究方向。具体来说,PEFT方法可以在消费级GPU(例如RTX 3090或4090)上对十亿级语言或扩散模型进行微调。因此本文重点关注PEFT中的低秩训练技术,尤其是LoRA方法。作者思考到,过去十年中深度学习发展阶段中的一个核心原则就是不断的“堆叠更多层(stack more layers)”,例如ResNet的提出可以使我们将卷积神经网络的深度提升到100层以上,并且也获得了非常好的效果。因此本文探索能否同样以堆叠的方式来提升低秩适应的训练效率呢?
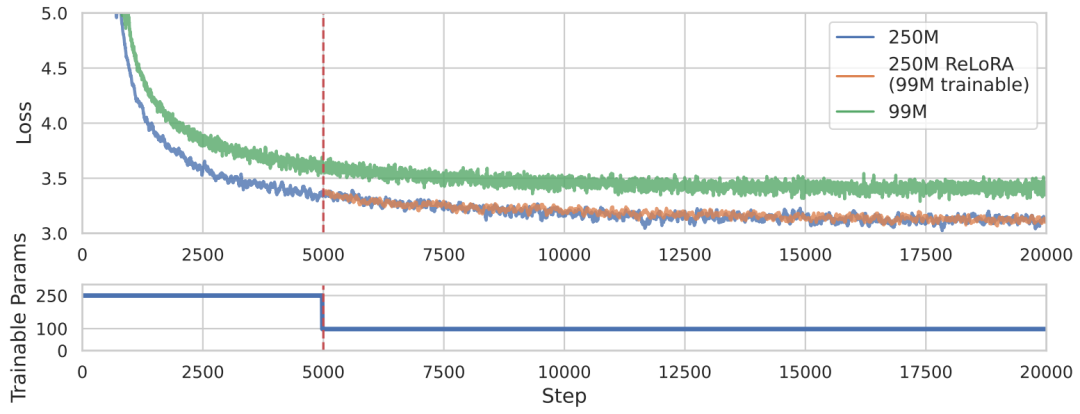
本文提出了一种基于低秩更新的ReLoRA方法,来训练和微调高秩网络,其性能优于具有相同可训练参数数量的网络,甚至能够达到与训练100M+规模的完整网络类似的性能,对比效果如上图所示。具体来说,ReLoRA方法包含(1)初始化全秩训练、(2)LoRA 训练、(3)参数重新启动、(4)锯齿状学习率调度(jagged learning rate schedule)和(5)优化器参数部分重置。作者选择目前非常火热的自回归语言模型进行实验,并且保证每个实验所使用的GPU计算时间不超过8天。二、本文方法作者首先从两个矩阵之和的秩入手,通常来说,矩阵相加的后秩的上界会比较紧凑,对于矩阵,,然后存在矩阵,,使得矩阵之和的秩高于或。作者希望利用这一特性来制定灵活的参数高效训练方法,然后从LoRA算法开始入手,LoRA可以将模型权重的更新量 分解为一组低秩矩阵乘积 ,如下式所示,其中 是固定缩放因子。
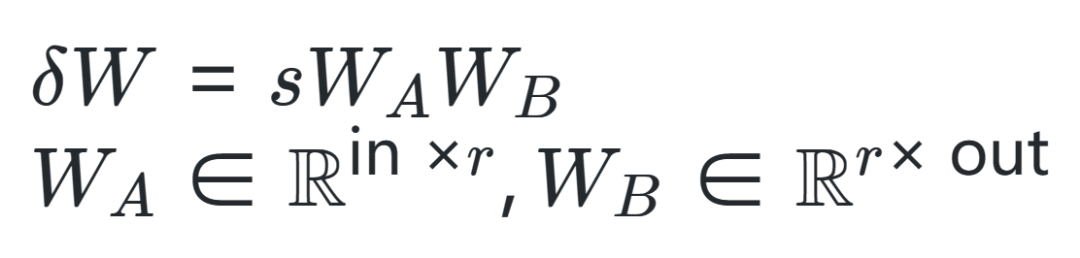
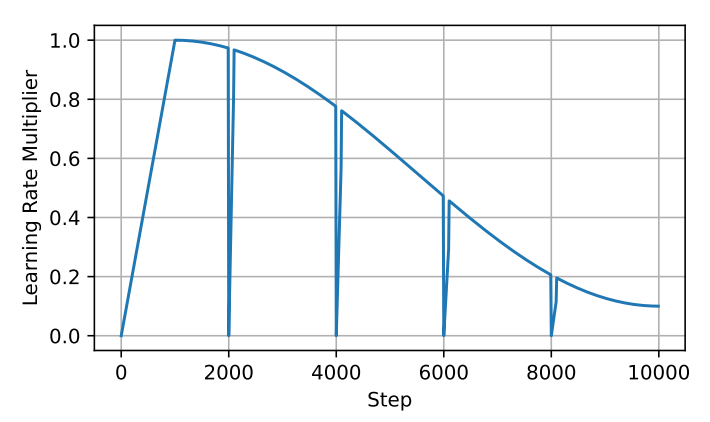
在具体操作时,LoRA通常是加入新的可学习参数 和 来实现,这些参数可以在训练后合并回原始参数中。因此,尽管上述方程允许我们在训练阶段中实现总参数更新量高于任意单个矩阵的秩,但其仍然受到的限制。因此作者想到通过不断叠加这一过程来突破限制达到更好的训练效果。这首先需要对LoRA过程进行重新启动,就可以在训练阶段不断合并每次得到的 和 来得到累加的权重更新量,计算公式如下:但是,想要对已经完成的LoRA过程重新启动并不容易,这需要对优化器进行精细的调整,如果调整不到位,会导致模型在重启后立即与之前的优化方向出现分歧。例如Adam优化器在更新时主要由先前步骤中所累积梯度的一阶矩和二阶矩引导。实际上,梯度矩平滑参数 和 通常非常高,因而在重新启动时的秩上界为 ,相应的梯度矩 和 都是满秩的,在合并参数后就会使用先前的旧梯度来优化 朝向与 相同的子空间方向。 为了解决这个问题,作者提出了ReLoRA方法,ReLoRA在合并和重新启动期间可以对优化器进行部分重置,并在随后的预热中过程中将学习率设置为0。具体来说,作者提出了一种锯齿状学习率调度算法,如下图所示,在每次对ReLoRA参数进行重置时,都会将学习率设置为零,并执行快速(50-100 步)学习率预热使其回到与重置前相同的水平范围内。
ReLoRA通过序列叠加的方式仅训练一小组参数就可以实现与全秩训练相当的性能,并且遵循LoRA方法的基础原则,即保持原始网络的冻结权重并添加新的可训练参数。乍一看,这种方式可能显得计算效率低下,但我们需要清楚的是,这种方法可以通过减小梯度和优化器状态的大小,来显著提高显存效率。例如Adam优化器状态消耗的显存通常是模型权重占用的两倍。通过大幅减少可训练参数的数量,ReLoRA可以在相同的显存条件下使用更大的batchsize大小,从而最大限度地提高硬件效率,ReLoRA的整体操作细节如下图所示。

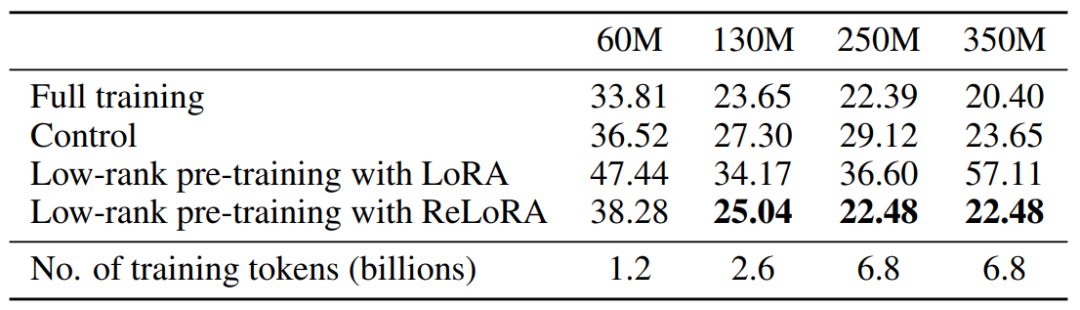
三、实验效果为了清晰的评估ReLoRA方法的性能,作者将其应用在各种规模大小(60M、130M、250M 和 350M)的Transformer模型上,并且都在C4数据集上进行训练和测试。为了展现ReLoRA方法的普适性,作者重点考察NLP领域的基础语言建模任务。模型架构和训练超参数设置基本与LLaMA模型保持一致。与LLaMA不同的是,作者在实验中将原始的注意力机制(使用float32进行 softmax计算)替换为了Flash注意力[2],并且使用bfloat16精度进行计算,这样操作可以将训练吞吐量提高50-100%,且没有任何训练稳定性问题。此外,使用ReLoRA方法训练的模型参数规模相比LLaMA要小得多,最大的模型参数才仅有350M,使用8个RTX4090上训练了一天时间就可以完成。 下图展示了本文方法与其他方法的性能对比效果,可以看到ReLoRA显着优于低秩LoRA方法,证明了我们提出的修改的有效性。此外,ReLoRA还实现了与满秩训练(Full training)相当的性能,并且我们可以观察到,随着网络规模的增加,性能差距逐渐缩小。有趣的是,ReLoRA 唯一无法超过的基线模型是仅具有60M参数的最小模型。这一观察结果表明,ReLoRA在改进大型网络的训练方面更加有效,这与作者最开始研究探索一种改进大型网络训练方法的目标是一致的。
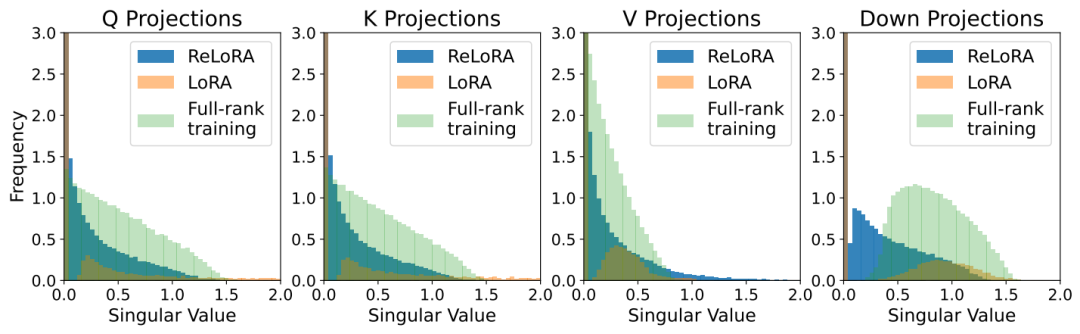
此外,为了进一步判断ReLoRA是否能够通过迭代低秩更新来实现相比LoRA更高的秩更新训练,作者绘制了ReLoRA、LoRA和全秩训练的热启动权重与最终权重之间差异的奇异值谱。如下图所示,下图说明了LoRA和ReLoRA之间对于 、、 和 奇异值的显著差异,可以看到ReLoRA在所有四个矩阵参数上均得到了最小的奇异值。
四、总结本文是一篇专注于减轻大型Transformer语言模型训练代价的工作,作者选取了一条非常具有前景的方向,即低秩训练技术,并且从最朴素的低秩矩阵分解 (LoRA) 方法出发,利用多个叠加的低秩更新矩阵来训练高秩网络,为了实现这一点,作者精心设计了包含参数重新启动、锯齿状学习率调度算法和优化器参数重置等一系列操作,这些操作共同提高了ReLoRA算法的训练效率,在某些情况下甚至能够达到与全秩训练相当的性能,尤其实在超大规模的Transformer网络中。作者通过大量的实验证明了ReLoRA的算法可行性和操作有效性,不知ReLoRA是否也会成为大模型工程师一项必备的算法技能呢?
-
神经网络
+关注
关注
42文章
4842浏览量
108175 -
深度学习
+关注
关注
73文章
5607浏览量
124629 -
LoRa
+关注
关注
355文章
1917浏览量
238418 -
大模型
+关注
关注
2文章
3771浏览量
5271
原文标题:LoRA继任者ReLoRA登场,通过叠加多个低秩更新矩阵实现更高效大模型训练效果
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI大模型微调企业项目实战课
【2025夏季班正课】大模型Agent智能体开发实战 课分享
迈向吉瓦级AI工厂的能源变革:英伟达Rubin平台电源架构解析
LoRa扩频技术应用
Lora技术应用领域
在Ubuntu20.04系统中训练神经网络模型的一些经验
LORA无线通信模块怎么组网
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
利用自压缩实现大型语言模型高效缩减

【Sipeed MaixCAM Pro开发板试用体验】 + 04 + 机器学习YOLO体验
SC11 FP300 MLA算子融合与优化




评论