 SC11 FP300 MLA算子融合与优化
SC11 FP300 MLA算子融合与优化

DeepSeekV3的attention模块采用了MLA(Multi-head Latent Attention,多头潜注意力)结构,通过对attention过程中的Key和Value进行低秩联合压缩,降低推理过程中需要的KV cache,提升推理效率。MLA对attention过程中的Query也进行了低秩压缩,可以减少训练过程中激活的内存。
大模型的推理分为两阶段,处理所有输入prompt并产生首个token的过程称为prefill,此后至产生所有token结束推理的过程称为decode,本文的MLA算子融合及优化特指decode过程。
MLA的计算过程比较复杂,包括下投影、上投影、attention和输出投影,为了减少数据搬运和任务调度带来的时间开销,提升芯片效率,我们在SC11上,将上投影和attention过程融合成MLA大算子,如图1所示。DeepSeekV3提供了两种计算模式:naïve和absorb,我们采用计算量更少的absorb方式实现MLA decode过程,步骤如下:

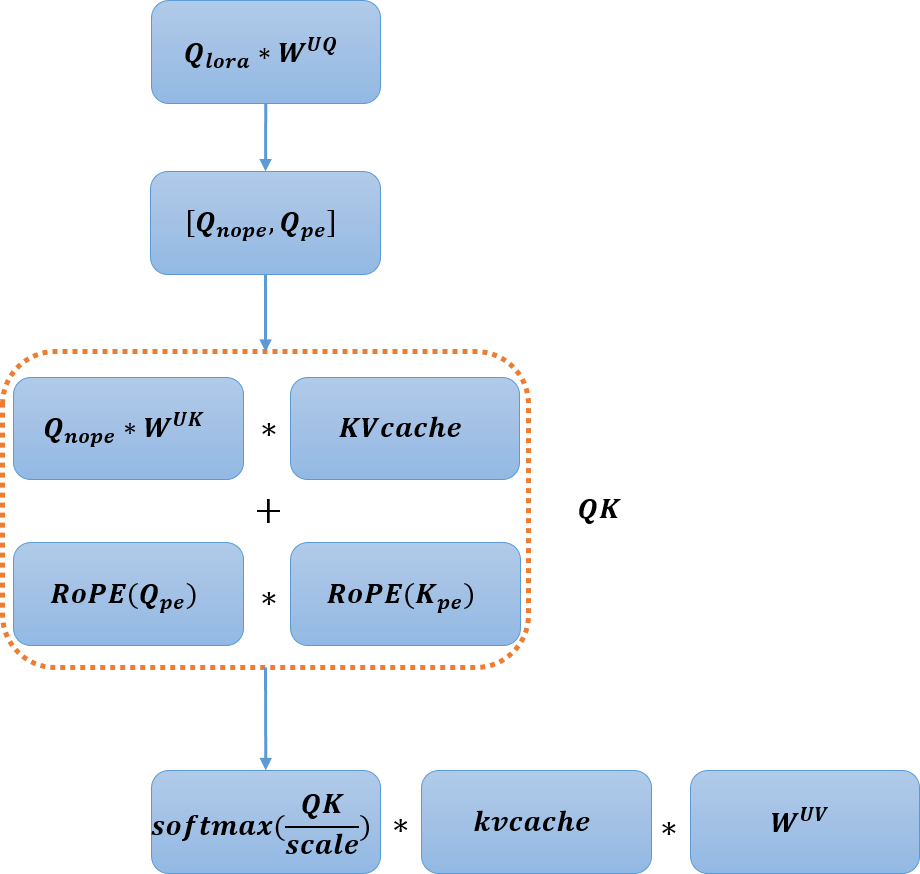 图1-SC11 MLA decode融合算子示意图
图1-SC11 MLA decode融合算子示意图
常用的attention并行部署方案有两种,TP(Tensor Parallel,张量并行)和DP(Data parallel,数据并行)。TP将权重切分到多颗芯片,每颗芯片会重复加载KV cache。DP将数据按batch分配到多颗芯片,每颗芯片处理不同batch的数据,但会重复加载权重。实际应用过程中,可以根据权重和缓存的大小选择并行部署方案,权重和缓存大小如表1所示。
表1 权重与缓存数据大小
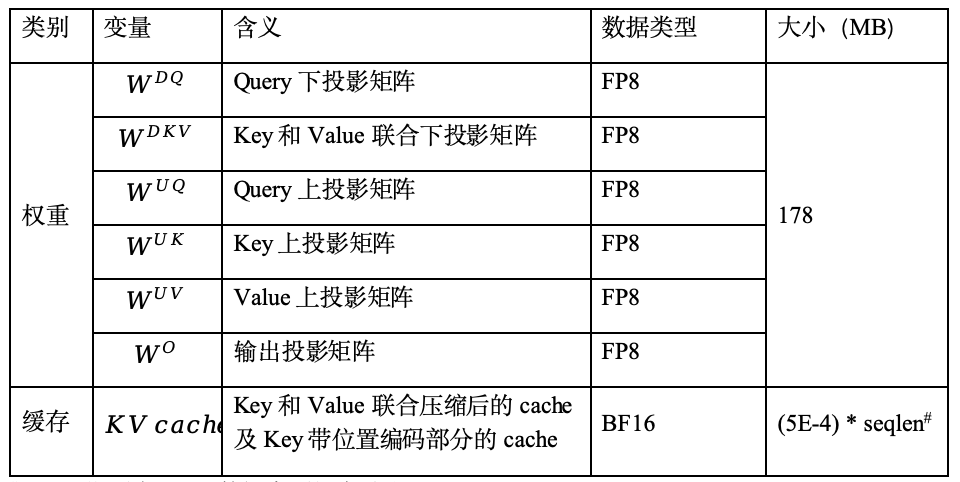
#seqlen指所有batch数据序列长度总和。
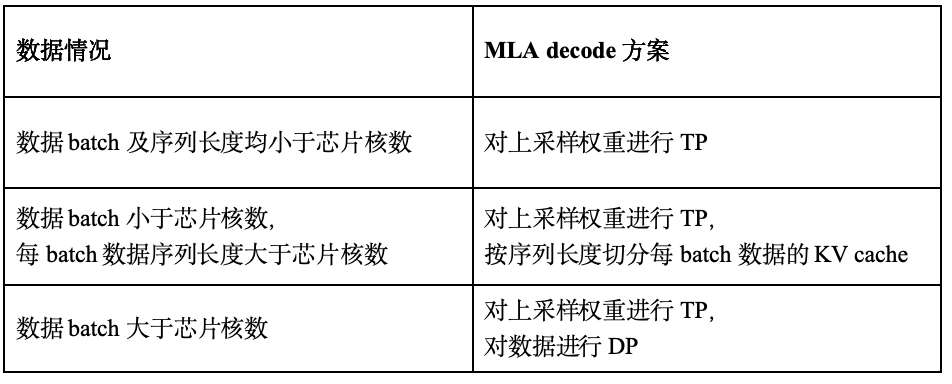
在SC11部署DeepSeekV3模型时,由于应用场景中的权重数据多于KV cache数据,所以MLA阶段采用TP方案进行部署,即将Query、Key和Value的上投影权重矩阵按head切分,部署到四张SC11。DeepSeekV3的参数中,上投影权重有128头,因此每张板卡处理32头。每颗芯片有多个核,上投影权重会继续按head切分到多核。由于低秩的KV cache不包含head维度,无法对KV cache进行TP,为了充分利用多核优势,我们对MLA的实现方式进行了探索,优化了不同batch数目和序列长度下的实现方案,如表2所示。
表2 MLA decode多核实现方案
除了算子融合与动态调用优化后的实现方案,MLA的实现过程也采用了业界常用的Flash Attention和Page Attention等优化方法,进一步减少数据搬运和内存占用。在Page Attention过程中,我们采用两块buffer优化KV cache搬运,使得数据搬运和MLA计算同步进行,优化过程如图2所示。图中SDMA代表负责DDR和L2 SRAM之间或内部的数据搬运模块,GDMA代表负责任意内存之间数据搬运的模块,BDC代表负责数据计算的单元。
在时刻T0同时进行两个操作:
SDMA将batch 0以page方式存储的KV cache从DDR搬到L2 SRAM中的Buffer0,形成连续存储的缓存数据;
GDMA将上投影权重从DDR搬到芯片的片上内存(local memory)。
在时刻T1同时进行三个操作:
SDMA将batch 1以page方式存储的KV cache从DDR搬到L2 SRAM中的Buffer1,形成连续存储的缓存数据;
GDMA将Buffer0中连续存储的batch 0的KV cache数据从L2 SRAM搬到localmemory;
BDC对batch 0进行MLA计算。
时刻T2和T3的操作可依此类推。测试数据表明,在128 batch 512序列的decode过程,使用双buffer优化page attention实现过程后,可以节省30%的推理时间。
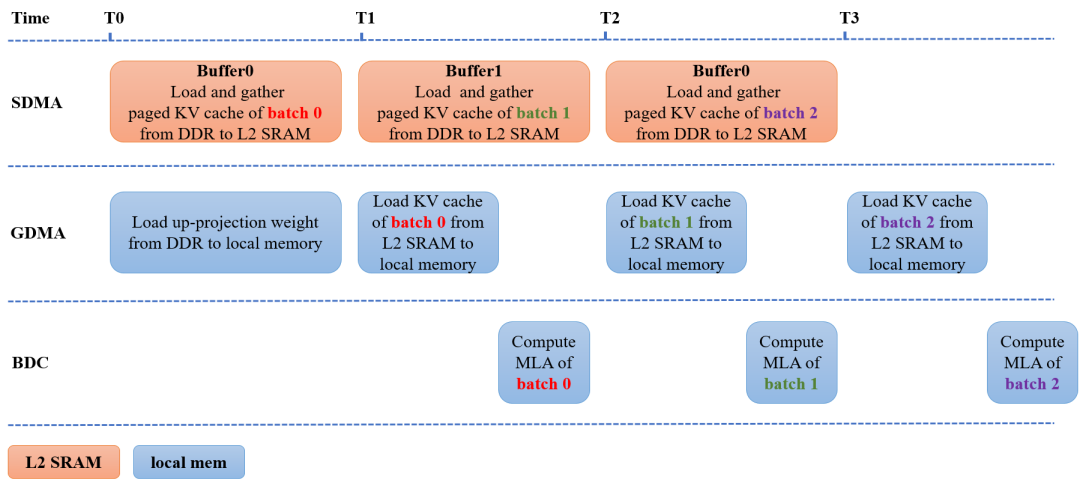 图2-双buffer优化Page Attention实现过程
图2-双buffer优化Page Attention实现过程
经过融合与优化后的MLA,助力了DeepSeekV3全流程的性能,当模型处理128 batch数据,每batch输入序列长度为128,输出序列长度为1024时,DeepSeekV3全流程在4卡SC11上能达到532 token/s。
作者:周文婧,陈学儒,温举发
-
AI
+关注
关注
91文章
41964浏览量
303060 -
人工智能
+关注
关注
1821文章
50511浏览量
267728 -
大模型
+关注
关注
2文章
3862浏览量
5295
发布评论请先 登录
如何用 STM32 + FP7208 + FP6195 打造一款真正的音乐律动氛围灯?
嵌入式人工智能课程(华清远见)
如何用 STM32 + FP7208 + FP6195 打造一款真正的音乐律动氛围灯?
深入解析Atmel AT88SC0204CA CryptoMemory:安全与性能的完美融合
深入解析Atmel AT88SC118 CryptoCompanion芯片:安全与性能的完美融合
探秘DS5002FP安全微处理器芯片:安全与性能的完美融合
ADSP-21593/21594/ADSP-SC592/SC594处理器:高性能与多功能的完美融合
探秘MLA1812NR压敏电阻系列:汽车级表面贴装的可靠之选
一文讲清真相,台湾远翔FP6291为何要分成G11与G12?

国产远翔FP6291的G11和G12,到底有什么区别?

【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课程(11大系列课程,共5000+分钟)
远翔的FP6291的G11和G12,到底有什么区别?
进迭时空同构融合RISC-V AI CPU的Triton算子编译器实践




评论