 黄仁勋甩出最强生成式AI处理器,全球首发HBM3e,比H100还快
黄仁勋甩出最强生成式AI处理器,全球首发HBM3e,比H100还快

芯东西8月9日报道,作为生成式AI、图形显示和元宇宙基础设施领域的“狠角色”,全球图显兼AI计算霸主NVIDIA(英伟达)接下来会放出哪些重磅“核弹”,已经预定了科技圈的焦点。
北京时间昨夜,在计算机图形年会SIGGRAPH上,NVIDIA创始人兼CEO黄仁勋一如既往穿着经典的皮衣登场,并一连亮出多款硬件。
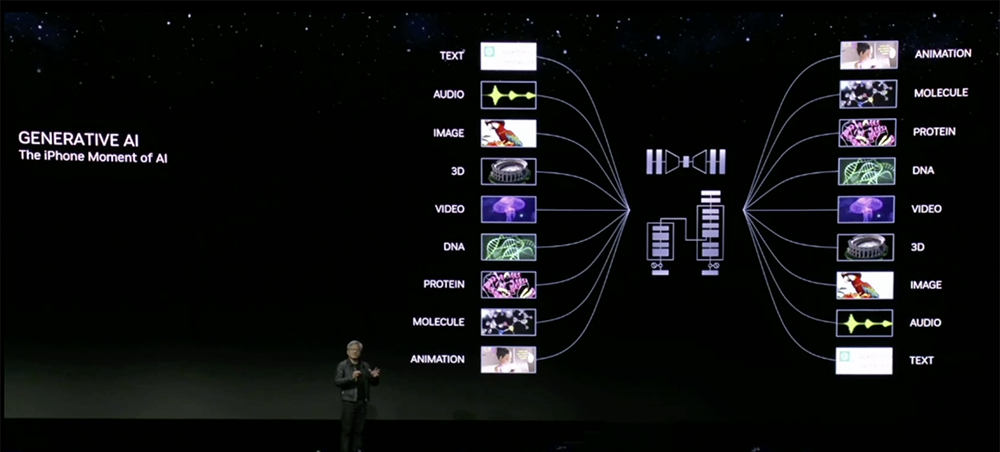
在黄仁勋眼中,生成式AI是AI的“iPhone时刻”。他谈道,人类语言是新的编程语言,我们已经使计算机科学民主化,现在每个人都可以成为程序员。
在随后大约1小时20分钟的演讲中,黄仁勋宣布全球首发HBM3e内存——推出下一代GH200 Grace Hopper超级芯片。黄仁勋将它称作“加速计算和生成式AI时代的处理器”。
还有5款硬件新品同期重磅发布,分别是搭载全新L40S Ada GPU的新款OVX服务器、搭载RTX 6000 Ada GPU的全新RTX工作站,以及3款高端桌面工作站GPU。
除此之外,黄仁勋还介绍了一系列软件更新和合作进展,总体来说都是为了帮助开发人员和企业进一步提高效率,降低开发门槛。
01. 配备全球最快内存的超级芯片来了!大降大模型推理成本
首先,全球第一款HBM3e GPU终于来了!
黄仁勋宣布推出面向加速计算和生成式AI的新一代NVIDIA GH200 Grace Hopper超级芯片。

GH200由72核Grace CPU和4PFLOPS Hopper GPU组成,在全球最快内存HBM3e的“助攻”下,内存容量高达141GB,提供每秒5TB的带宽。其每个GPU的容量达到NVIDIA H100 GPU的1.7倍,带宽达到H100的1.55倍。
该超级芯片可以用于任何大型语言模型,降低推理成本。
与当前一代产品相比,新的双GH200系统共有144个Grace CPU核心、8PFLOPS计算性能的GPU、282GB HBM3e内存,内存容量达3.5倍,带宽达3倍。如果将连接到CPU的LPDDR内存包括在内,那么总共集成了1.2TB超快内存。
GH200将在新的服务器设计中提供,黄仁勋还放出了一段动画视频,展示组装面向生成式AI时代的Grace Hopper AI超级计算机的完整过程。

首先是一块Grace Hopper,用高速互连的CPU-GPU Link将CPU和GPU“粘”在一起,通信速率比PCIe Gen5快7倍。
一个Grace Hopper机架装上NVIDIA BlueField-3和ConnectX-7网卡、8通道4.6TB高速内存,用NVLink Switch实现GPU之间的高速通信,再加上NVLink Cable Cartridge,组成了NVIDA DGX GH200构建块。

NVIDA DGX GH200由16个Grace Hopper机架,通过NVLink Switch系统连成集群,能让256块GPU组成的系统像一块巨型GPU一样工作。由256块GH200组成的NVIDIA DGX GH200 SuperPod,拥有高达1EFLOPS的算力和144TB高速内存。
NVIDIA Quantum-2 InfiniBand Switch可用高速、低延时的网络连接多个DGX SuperPod,进而搭建出面向生成式AI时代的Grace Hopper AI超级计算机。

这带来的主要优势是,实现同等算力的情况下,用更少卡、省更多电、花更少钱。
黄仁勋抛出一个问题:花1亿美元能买什么?
过去,1亿美元能买8800块x86 CPU组成的数据中心,功耗是5MW。

如今,1亿美元能买2500块GH200组成的Iso-Budget数据中心,功耗是3MW,AI推理性能达到上述CPU系统的12倍,能效达20倍。

如果达到跟x86 CPU数据中心相同的AI推理性能,Iso-Troughput数据中心只需用到210块GH200,功耗是0.26MW,成本只有CPU数据中心的1/12,仅800万美元。

“买得越多,省得越多。”黄仁勋再度用这句讲过很多遍的“导购金句”总结。
为方便GH200应用,GH200与今年早些时候在COMPUTEX上推出的NVIDIA MGX服务器规范完全兼容。因此系统制造商可以快速且经济高效地将GH200添加到其服务器版本中。
新GH200预计将于明年第二季度投产。
02. OVX服务器上新,采用L40S Ada GPU
面向数据中心,黄仁勋宣布推出配备全新NVIDIA L40S GPU的NVIDIA OVX服务器,可用于加速AI训练和推理、3D设计和可视化、视频处理和工业数字化等复杂的计算密集型应用。
NVIDIA OVX是针对服务器的参考架构,针对图形、计算、存储和网络进行了优化。全新OVX系统将在每台服务器上启用多达8个L40S GPU,每个GPU配备48GB GDDR6超快内存。

L40S是一款功能强大的通用数据中心处理器,基于Ada架构,内置第四代Tensor Core和FP8 Transformer Engine,提供超过1.45PFLOPS的张量处理能力。
对于具有数十亿参数和多种数据模式(如文本和视频)的复杂AI工作负载,与A100 GPU相比,L40S可实现快1.2倍的AI推理性能、快1.7倍的训练性能、快3.5倍的渲染速度,启用DLSS3时Omniverse渲染速度更是能高到近4倍。
L40S包含18176个CUDA内核,提供近5倍于A100 GPU的单精度浮点(FP32)性能,以加速复杂的计算和数据密集型分析,支持对于工程和科学模拟等计算要求苛刻的工作流程。
为了支持实时渲染、产品设计和3D内容创建等高保真的专业可视化工作流程,L40S GPU内置有142个第三代RT核心,可提供212TFLOPS的光追性能。
L40S GPU将于今年秋季上市。NVIDIA之前投资的CoreWeave是首批提供L40S实例的云服务提供商之一。
03. 推出搭载RTX 6000的RTX工作站、三款桌面级RTX GPU
面向生成式AI和大模型开发、内容创作、数据科学,黄仁勋宣布推出搭载RTX 6000 Ada GPU的全新NVIDIA RTX工作站。

新的RTX工作站提供多达4个NVIDIA RTX 6000 Ada GPU,每个都配备48GB内存,单个桌面工作站可以提供高达5828TFLOPS的AI性能和192GB的GPU内存。
按用户需求,系统可配置NVIDIA AI Enterprise或Omniverse Enterprise软件,以支持各种苛刻的生成式AI和图形密集型工作负载。
该工作站将于秋季由系统制造商开始提供。
此外,NVIDIA也在SIGGRAPH期间推出三款新的桌面Ada GPU——NVIDIA RTX 5000、RTX 4500和RTX 4000,为全球专业人士提供最新的AI、图形和实时渲染技术。
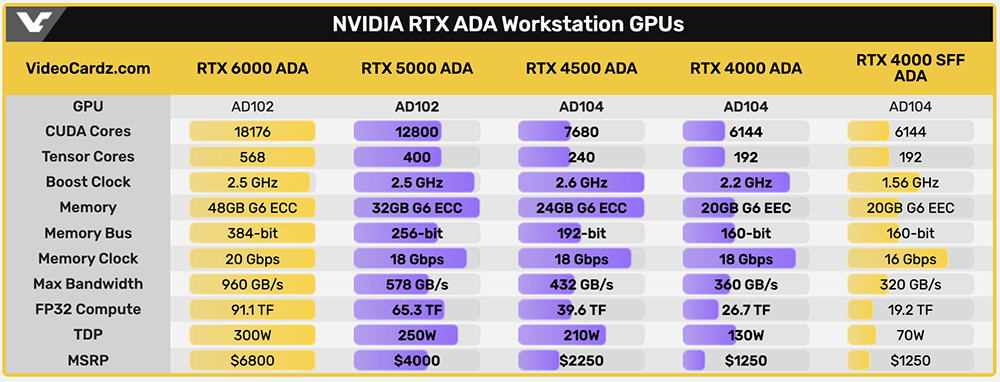
▲NVIDIA RTX Ada工作站GPU主要参数对比(图源:VideoCardz)
三款新GPU均采用4nm定制工艺,并拥有较大的内存:RTX 4000提供20GB GDDR6内存,RTX 4500提供24GB GDDR6内存,RTX 5000提供32GB GDDR6内存。所有都支持错误代码纠正,适用于大型3D模型、渲染图像、模拟和AI数据集的无误差计算。
同时,它们能支持高分辨率AR(增强现实)和VR(虚拟现实)设备,以提供创造AR、VR和MR(混合现实)内容所需的高性能图形。
外媒Wccftech整理了不同RTX Ada工作站显卡的参数对比:
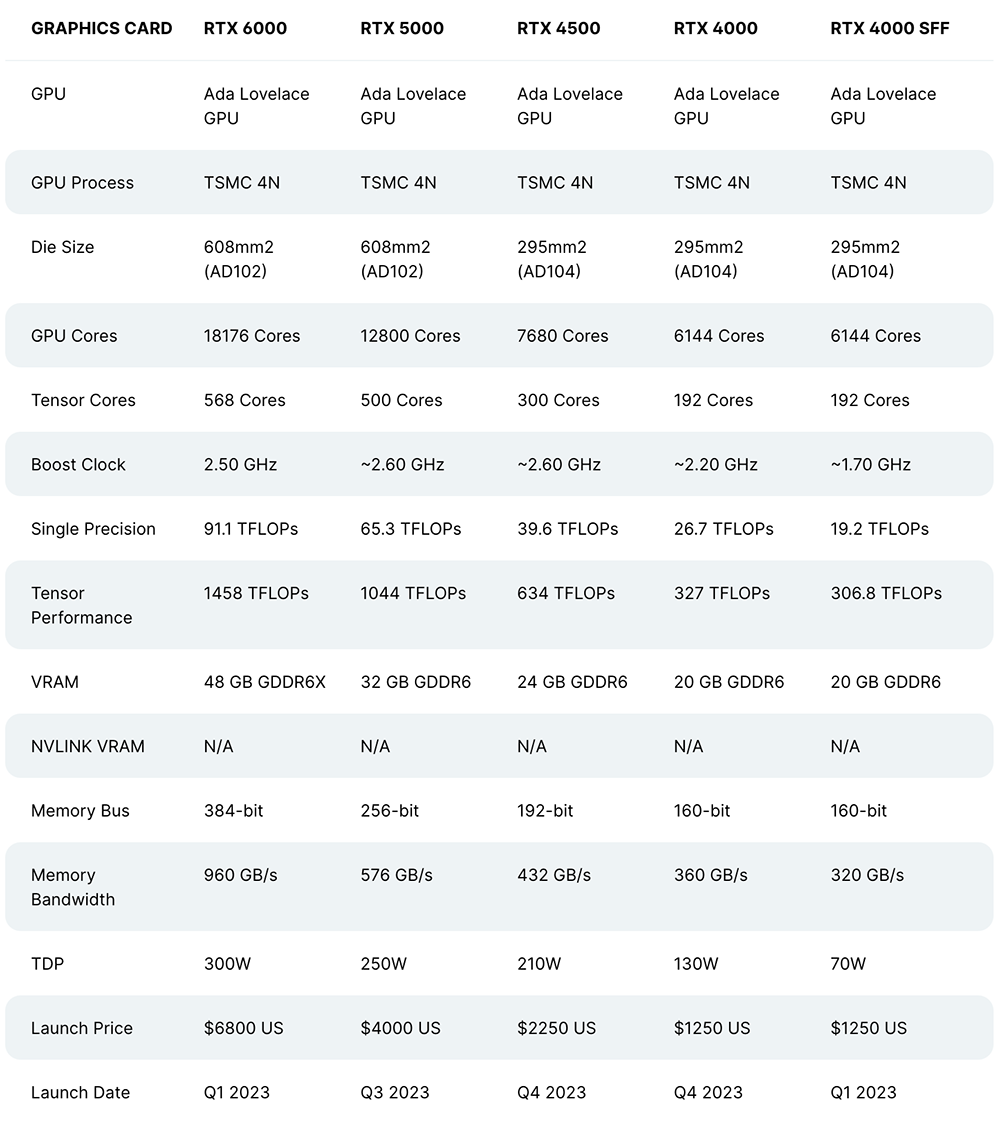
RTX 5000现已上市,RTX 4500和RTX 4000 GPU将于今年秋季发售。
04. 新合作、新升级、新产品助攻生成式AI模型高效开发和部署
除了上述硬件产品外,黄仁勋分享了3个关于优化生成式AI流程的新发布,这些将有助于加速行业采用基于大型语言模型的生成式AI:
一是NVIDIA和全球最大AI开源社区Hugging Face建立合作。
二是推出NVIDIA AI Enterprise 4.0,把DGX Cloud中的所有功能放到NVIDIA AI Enterprise软件中。
三是推出NVIDIA AI Workbench,将需要用于生成式AI工作的一切打包在一起,只用点击一下就能将这个项目移动到任何终端设备或云端。
1、与Hugging Face合作:将数百万开发人员连接到生成式AI超级计算
黄仁勋宣布,NVIDIA和Hugging Face建立合作伙伴关系,将为构建大型语言模型和其他高级AI应用程序的开发人员提供生成式AI超级计算。
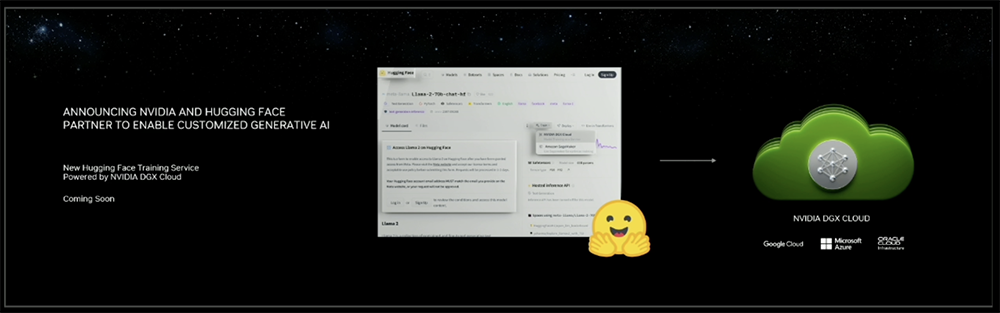
开发人员可以访问Hugging Face平台内的NVIDIA DGX Cloud AI超级计算,来训练和调优先进的AI模型。他们将有一个非常简单的界面来推进工作,无需担心训练的复杂性,因为这些都会由DGX Cloud处理。
DGX Cloud的每个实例有8个NVIDIA H100或A100 80GB Tensor Core GPU,每个节点的GPU内存总计640GB。DGX Cloud包含来自NVIDIA专家的支持,可以帮助客户优化其模型并快速解决开发挑战。
作为合作的一部分,Hugging Face将推出一项名为“训练集群即服务(Training Cluster as a Service)”,以简化为企业创建新的和自定义生成式AI模型。该服务由NVIDIA DGX Cloud提供支持,将在未来几个月内推出。
2、NVIDIA AI Workbench:在笔记本电脑上也能轻松启动生成式AI项目
另一款新品NVIDIA AI Workbench,是一个统一、易用的工作空间,能让开发人员随处构建或运行自己的生成式AI模型。
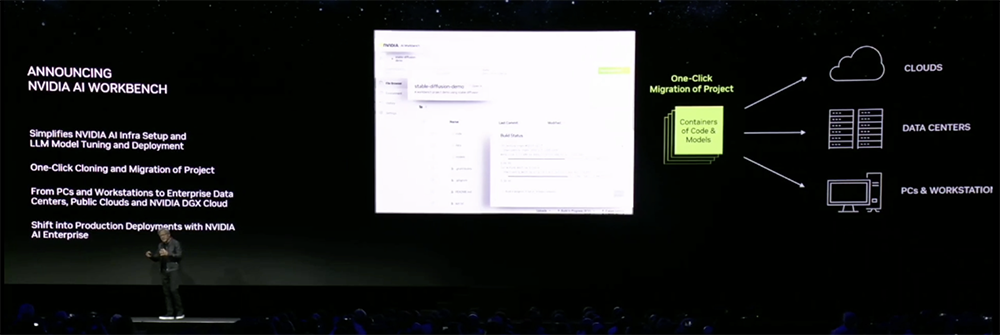
开发者可以很方便地将所有必要的企业级模型、框架、SDK和库从开源代码库和NVIDIA AI平台打包到这个统一的开发者工作空间中,然后只需点击几下鼠标,就能将自己的AI项目从一个位置移动到另一个位置。
这样就能在个人电脑、笔记本电脑或工作站上快速创建、测试和定制预训练的生成式AI模型,并在需要时将其扩展到数据中心、公有云或NVIDIA DGX Cloud。
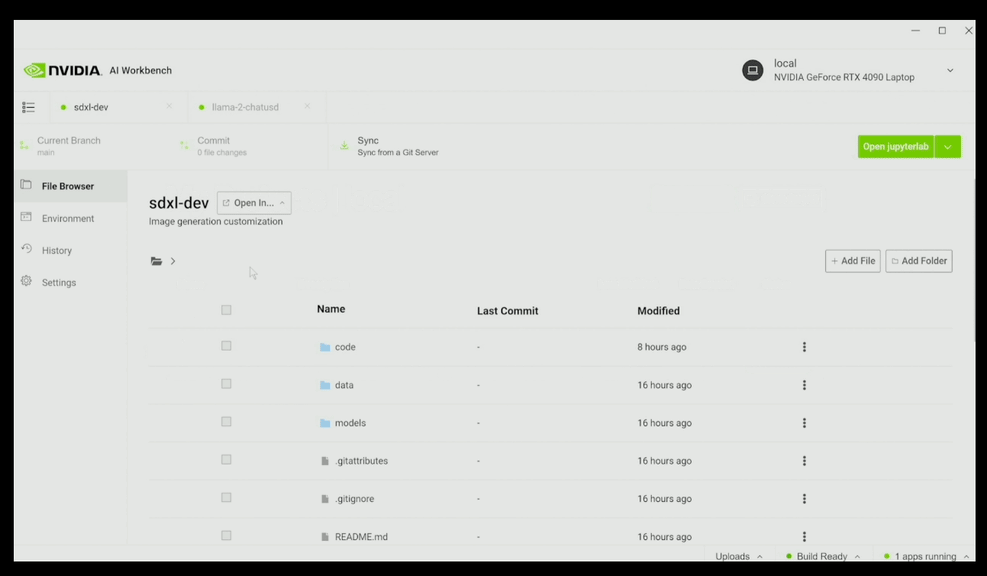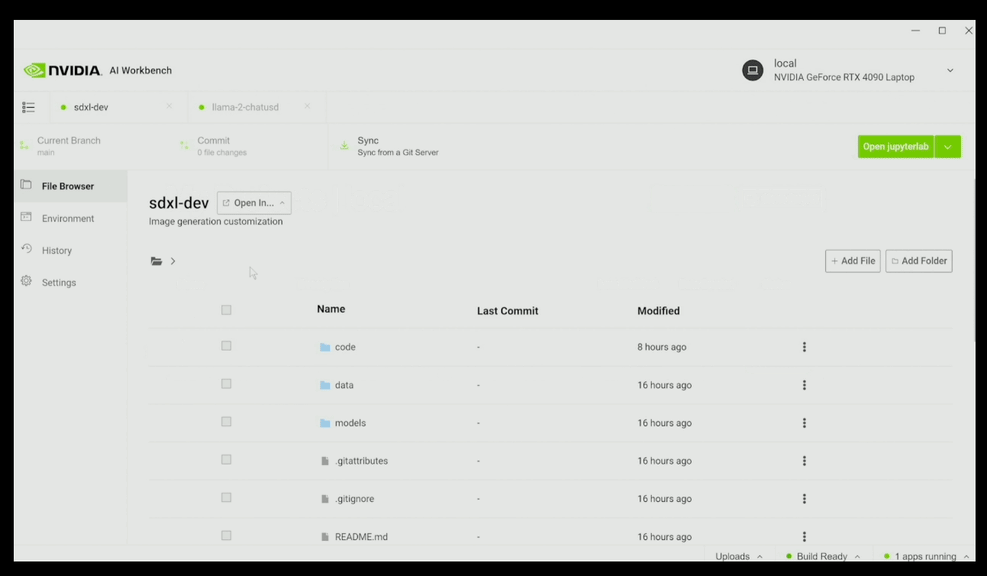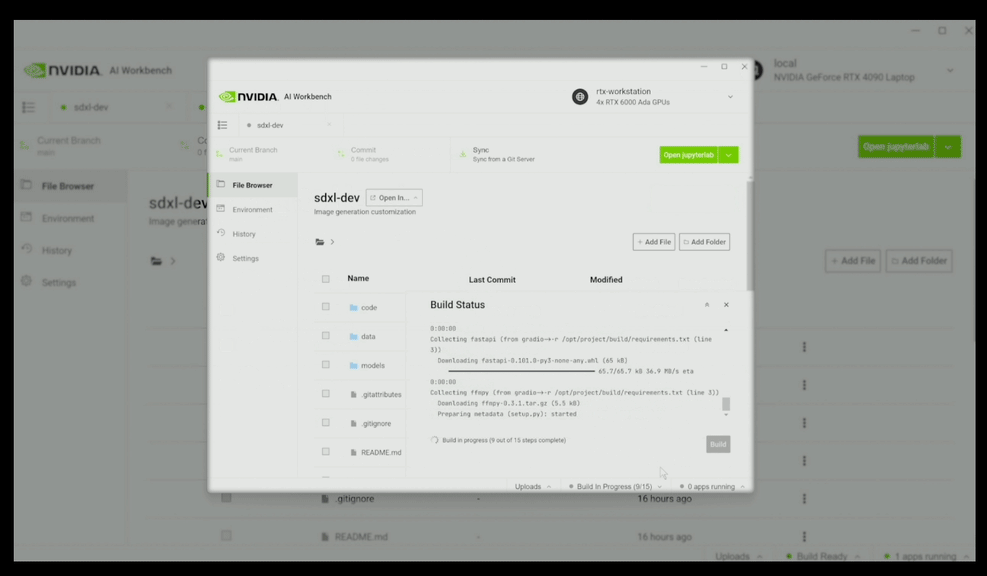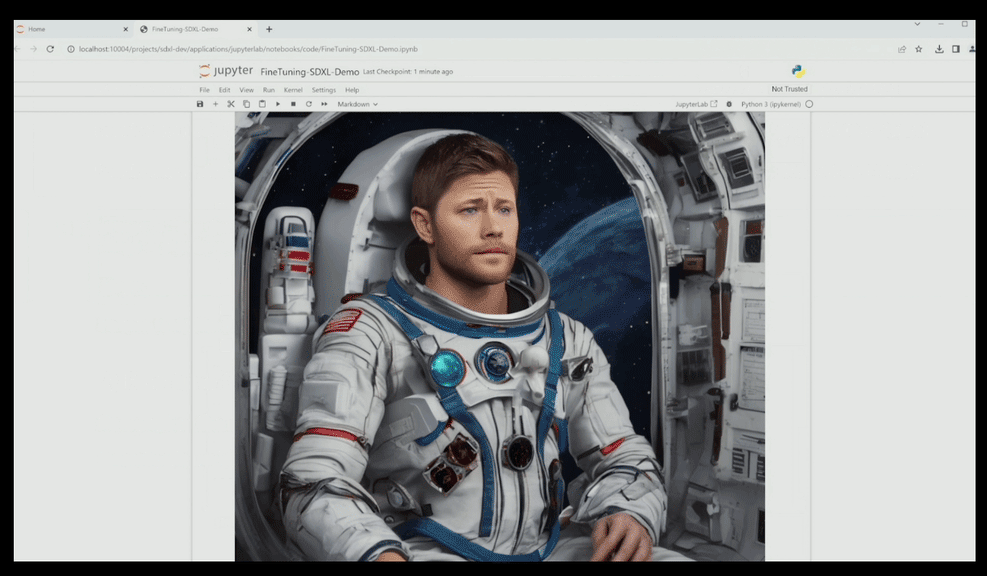
举个例子,你可以在NVIDIA AI Workbench页面上导入项目,比如导入SDXL-dev文生图模型,输入“玩偶黄仁勋在太空”,结果因为模型似乎不认识玩偶老黄,生成的图像跟老黄的形象完全不沾边。
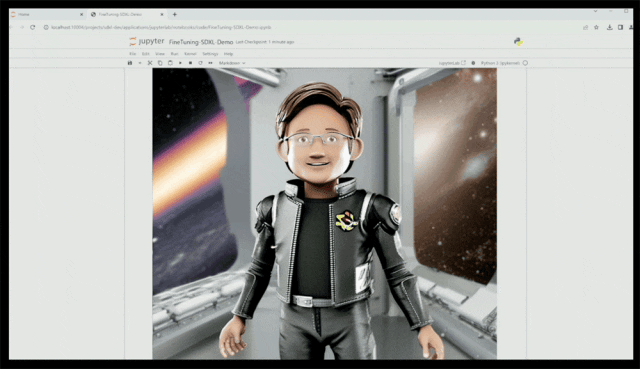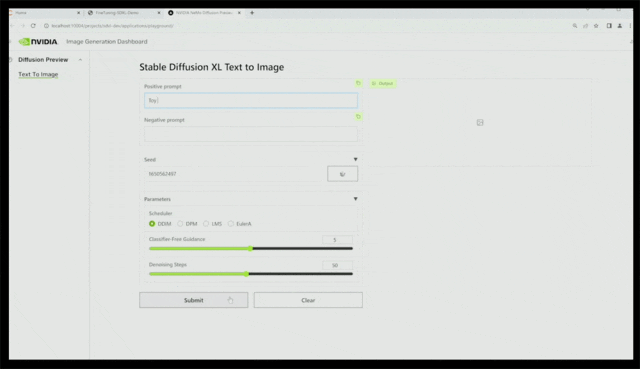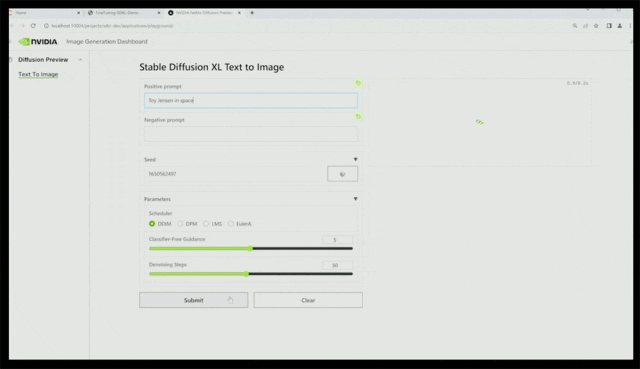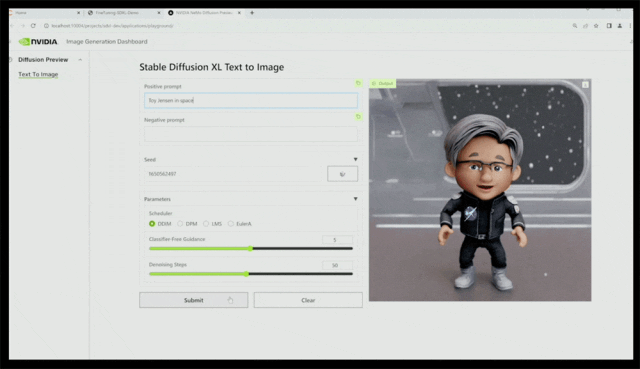
接着只用几张玩具老黄的图像,对SDXL文生图模型进行微调,它就能生成还不错的效果。
总的来说,AI Workbench为跨组织团队创建基于AI的应用程序提供了简化的途径,通过在本地系统上运行的简化的界面访问,让开发人员能使用自定义数据从主流的代码库(如Hugging Face、GitHub和NVIDIA NGC)中定制模型,并能轻松跨多平台共享。
戴尔、惠普、Lambda、联想、超微等AI基础设施供应商正采用AI Workbench以增强其最新一代多GPU桌面工作站、高端移动工作站和虚拟工作站的能力。
3、NVIDIA AI enterprise 4.0:提供一系列生成式AI工具
最新版的企业软件平台NVIDIA AI enterprise 4.0,可提供生产就绪型生成式AI工具,并提供了可靠的生产部署所需的安全性和API稳定性。

NVIDIA AI Enterprise 4.0新支持的软件和工具有助于简化生成式AI部署,其中一大亮点是引入用于构建、定制和部署大型语言模型的云原生框架NVIDIA NeMo。
其他工具还包括NVIDIA Triton管理服务(通过模型编排实现可扩展AI高效运行)、NVIDIA Base Command Manager Essentials集群管理软件(帮助企业在数据中心、多云和混合云环境中最大限度提高AI服务器性能和利用率)等。
NVIDIA AI Enterprise软件支持用户跨云、数据中心和边缘构建和运行支持NVIDIA AI的解决方案,经认证可在主流NVIDIA认证系统、NVIDIA DGX系统、所有主要云平台和新发布的NVIDIA RTX上运行工作站。
最新版本的企业软件平台将集成到谷歌云、微软Azure、Oracle云基础设施等NVIDIA合作伙伴市场。
05. Ominverse升级:加持生成式AI能力,晒OpenUSD路线图
在生成式AI加持下,构建工业元宇宙与数字孪生场景的开发更加方便高效、视觉效果更加逼真。
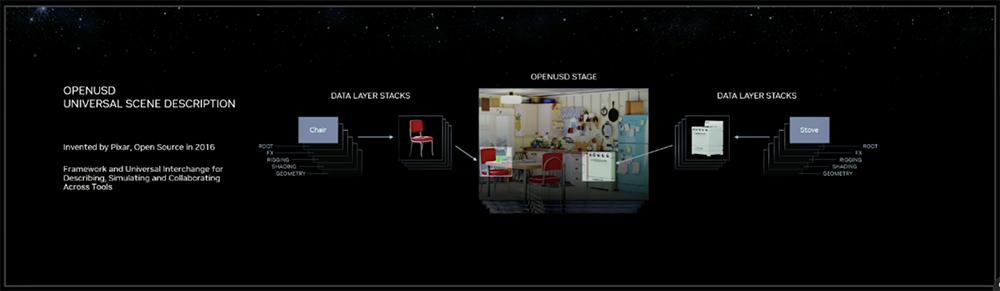
面向元宇宙领域,NVIDIA的主角当仁不让是Omniverse平台,以及该平台的基础——开源通用场景描述框架OpenUSD。生成式AI与Omniverse的结合也此次演讲的重头戏。
黄仁勋宣布,比亚迪和梅赛德斯·奔驰合资的豪华电动汽车品牌腾势(DENZA)已与营销及通信巨头WPP合作,在NVIDIA Omniverse Cloud上构建和部署其下一代先进汽车配置器。
WPP通过USD或OpenUSD集成了来自电动汽车制造商首选的计算机辅助设计(CAD)工具的全保真设计数据,从而构建一个单一的、物理精确的、实时的腾势N7汽车模型数字孪生体。
当想要添加一个功能时,无需任何手动返工,就能将该功能构建到腾势汽车的数字孪生体中,并立即部署到所有营销渠道中。
USD提供了一个高性能的通用框架来描述、组合、模拟和协作3D项目和数据。NVIDIA坚信这是3D互联网的基础。
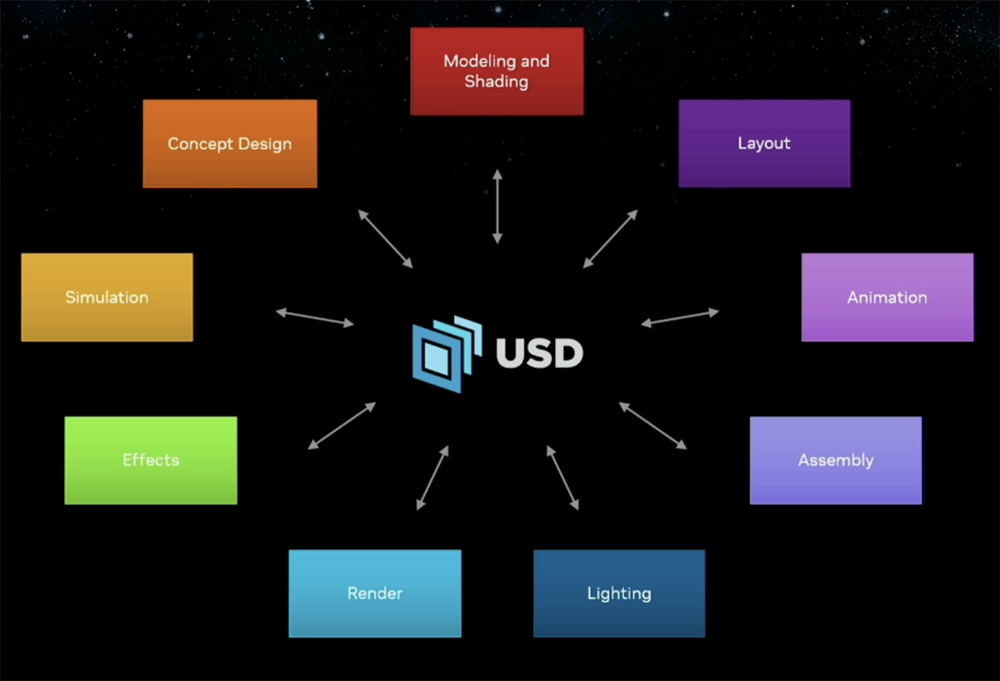
“就像HTML点燃了2D互联网的重大计算革命一样,OpenUSD将点燃3D写作和工业数字化的时代。”黄仁勋说,“通过开发NVIDIA Omniverse和生成式AI,NVIDIA将全力支持OpenUSD的发展和采用。”
在SIGGRAPH大会上,黄仁勋展示了从2020年至2023年NVIDIA加速OpenUSD的发展路线图。

NVIDIA正推出一个SIM Ready规范,将物理属性应用于USD资产,以便机器人和自动驾驶汽车等AI代理可以完全在模拟世界中了解真实世界。
近期NVIDIA与皮克斯、Adobe、苹果、Autodesk联合成立了OpenUSD联盟AOUSD,将为OpenUSD开发一个标准规范,以加速其在工具生态系统中的采用和软件间的互操作性。
NVIDIA正通过NVIDIA Omniverse、新技术组合和云API以及新的NVIDIA OpenUSD开发者计划,推进OpenUSD框架的开发。
为了让开发人员更无缝地实施和部署OpenUSD流水线和应用程序,NVIDIA将生成式AI和OpenUSD结合,推出一些Omniverse云API:
(1)ChatUSD:基于NVIDIA Nemo框架的一个大型语言模型副驾驶,可回答USD知识问题或生成Python-USD代码脚本)。
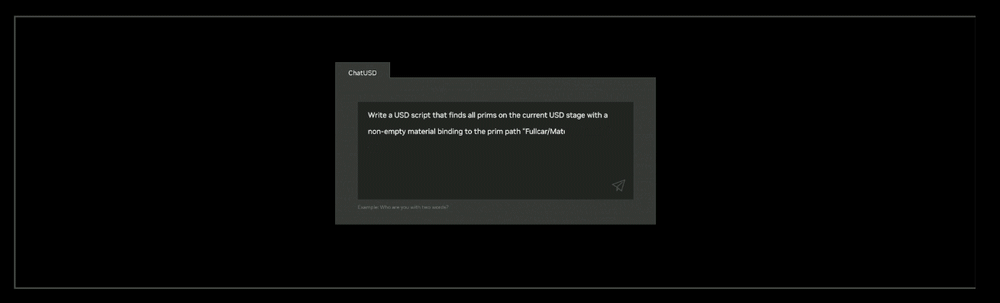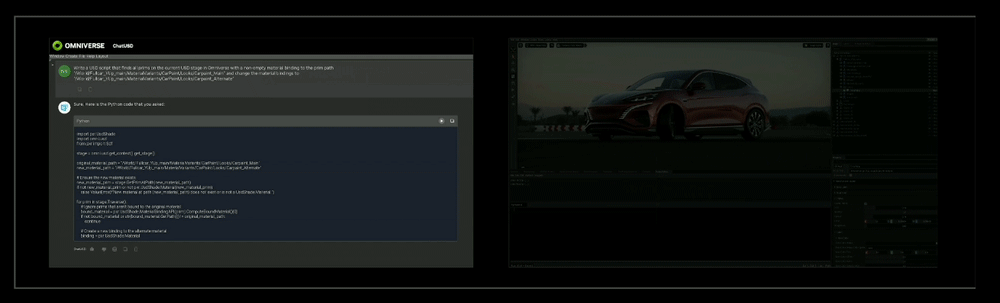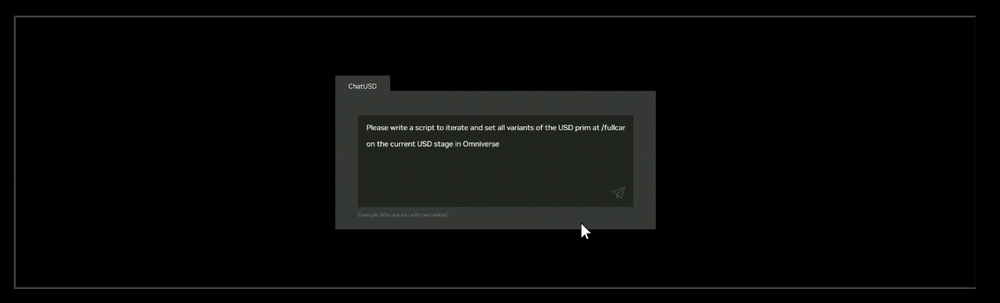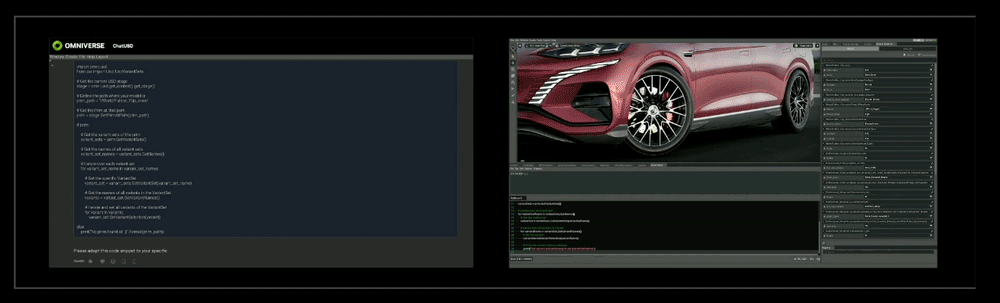
(2)RunUSD:用于检查上传文件与OpenUSD版本兼容性,可生成实时的完全路径跟踪的交互式USD文件渲染。
(3)DeepSearch:基于大型语言模型的语义3D搜索服务,可通过文本或图像输入输入,对大量未标注资产的数据库进行快速语义搜索。
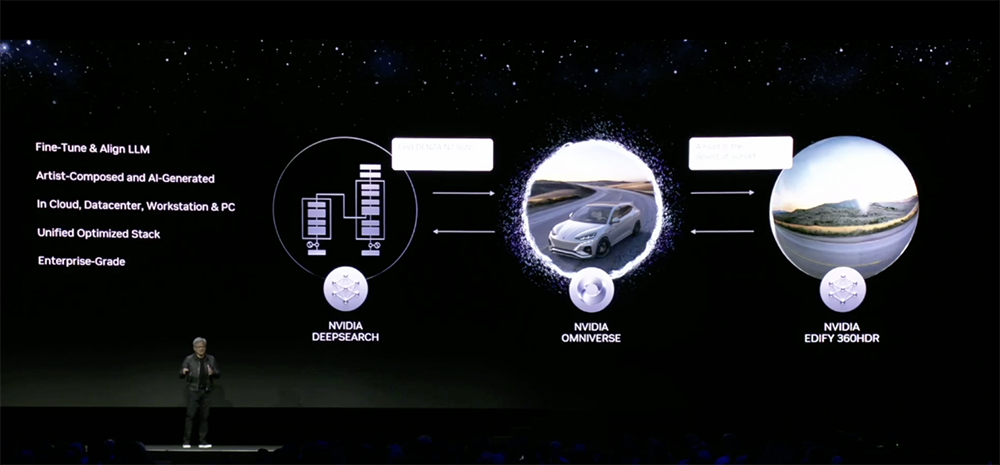
Omniverse云API将使开发人员能够轻松地即时访问NVIDIA及其合作伙伴的最新生成式AI和OpenUSD技术。
NVIDIA Picasso便是其中之一。它是一个基于云的代工厂,用于构建自定义的生成式AI视觉模型。Picasso使开发人员能训练文生图、文生视频、文本转3D生成等模型。
Shutterstock正在使用NVIDIA Picasso(构建的代工厂)来开发生成式AI服务,以加速3D工作流程。Shutterstock宣布了这些新服务的首款产品360 HDRi。经Picasso训练的模型可生成逼真的8K分辨率360度高动态范围成像(HDRi)环境地图,从而大大加快3D场景的内容创作。
此外,Omniverse进行了一些重要的版本更新:
Omniverse RTX渲染器集成了DLSS 3技术和新的AI降噪器,AI降噪器可实现对大规模工业场景的实时4K路径追踪。
开发人员还可以构建基于OpenUSD的内容和体验,并将其部署到扩展现实(XR)设备上。新的XR开发工具使用户能在基于Omniverse应用程序中本地构建空间计算选项,灵活体验他们喜欢的3D项目和虚拟世界。
Omniverse USD Composer可支持3D用户组装大规模的、基于OpenUSD的场景。
提供生成式AI API的Omniverse Audio2Face,仅从音频文件就能创建逼真的面部动画和手势,现在包括多语言支持和一个新的女性基础模型。
Omniverse Kit Extension Registry是一个用于访问、共享和管理全方位扩展的中央存储库,让开发人员能轻松地在他们的应用程序中打开和关闭功能,使构建自定义app变得更容易。
这些新的应用程序和体验模板能让开发人员以很少的代码开始使用OpenUSD和Omniverse。
此外,Adobe与NVIDIA扩大了在Adobe Substance 3D、生成式AI和OpenUSD计划方面的合作,宣布将在Omniverse中将提供其创意生成式AI模型系列Adobe Firefly的API。
最新版本的Omniverse处于测试阶段,很快就会发布到Omniverse Enterprise企业版。
06. 结语:英伟达All in 生成式AI
在本届SIGGRAPH大会上,黄仁勋集中分享了NVIDIA最新的技术、研究、OpenUSD开发和AI内容创建解决方案,并用一系列对开发者及企业极具吸引力的软硬件新品,再度验证NVIDIA在新时代的自定义——NVIDIA是一家平台公司。
今年以来,NVIDIA GPU已成为支持生成式AI和大模型训练的大算力AI芯片首选,亦当之无愧是推动生成式AI普及的核心功臣。受益于生成式AI热潮的NVIDIA,也正积极地成为一个称职的“生成式AI布道者”,近期一直尽心竭力地推广生成式AI在各行各业应用的价值。
在推动高效地、经济地、可扩展地运行生成式AI模型的道路上,NVIDIA所展示了许多软硬件创新成果,无论是加速大型语言模型训练和调优,还是简化定制生成式AI模型的工作流程,抑或是持续提高图形渲染及工业元宇宙基础设施的性能和开发体验,这些进展都令人印象深刻。
-
处理器
+关注
关注
68文章
20148浏览量
247130 -
NVIDIA
+关注
关注
14文章
5496浏览量
109090 -
AI
+关注
关注
89文章
38091浏览量
296592 -
生成式AI
+关注
关注
0文章
537浏览量
1021 -
HBM3
+关注
关注
0文章
74浏览量
468 -
HBM3E
+关注
关注
0文章
82浏览量
715
原文标题:昨夜,黄仁勋甩出最强生成式AI处理器,全球首发HBM3e,比H100还快
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
黄仁勋中国行的背后,AI芯片暗战与英伟达生存博弈
NVIDIA CEO黄仁勋畅谈AI时代最新蓝图
央视专访英伟达创始人黄仁勋 黄仁勋:总感觉公司快倒闭了
黄仁勋用中文演讲全文分享 中国人工智能模型世界一流 黄仁勋中文演讲提了11家中国公司
NVIDIA 将恢复H20芯片在中国的销售 NVIDIA CEO 黄仁勋在美国和中国加大推广AI
NVIDIA CEO 黄仁勋在美国和中国推广 AI

NVIDIA英伟达 GTC 巴黎亮点:NVIDIA CEO黄仁勋公布欧洲AI发展新蓝图






 工商网监
工商网监
评论