 让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升

FlashAttention新升级!斯坦福博士一人重写算法,第二代实现了最高9倍速提升。
继超快且省内存的注意力算法FlashAttention爆火后,升级版的2代来了。FlashAttention-2是一种从头编写的算法,可以加快注意力并减少其内存占用,且没有任何近似值。比起第一代,FlashAttention-2速度提升了2倍。甚至,相较于PyTorch的标准注意力,其运行速度最高可达9倍。
一年前,StanfordAILab博士Tri Dao发布了FlashAttention,让注意力快了2到4倍,如今,FlashAttention已经被许多企业和研究室采用,广泛应用于大多数LLM库。如今,随着长文档查询、编写故事等新用例的需要,大语言模型的上下文以前比过去变长了许多——GPT-4的上下文长度是32k,MosaicML的MPT上下文长度是65k,Anthropic的Claude上下文长度是100k。但是,扩大Transformer的上下文长度是一项极大的挑战,因为作为其核心的注意力层的运行时间和内存要求,是输入序列长度的二次方。Tri Dao一直在研究FlashAttention-2,它比v1快2倍,比标准的注意力快5到9倍,在A100上已经达到了225 TFLOP/s的训练速度!

项目链接:
https://github.com/Dao-AILab/flash-attention

FlashAttention-2:更好的算法、并行性和工作分区
端到端训练GPT模型,速度高达225 TFLOP/s
虽说FlashAttention在发布时就已经比优化的基线快了2-4倍,但还是有相当大的进步空间。比方说,FlashAttention仍然不如优化矩阵乘法(GEMM)运算快,仅能达到理论最大FLOPs/s的25-40%(例如,在A100 GPU上的速度可达124 TFLOPs/s)。
对注意力计算重新排序
我们知道,FlashAttention是一种对注意力计算进行重新排序的算法,利用平铺、重新计算来显著加快计算速度,并将序列长度的内存使用量从二次减少到线性。
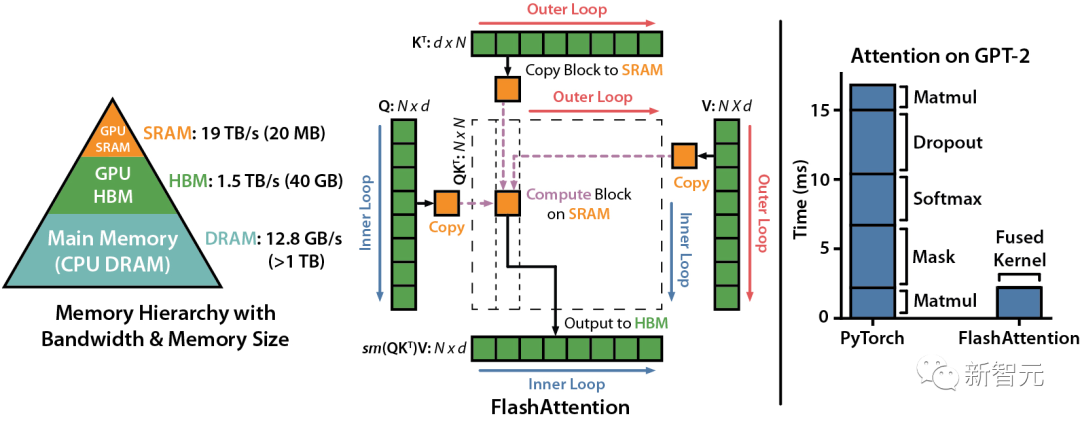
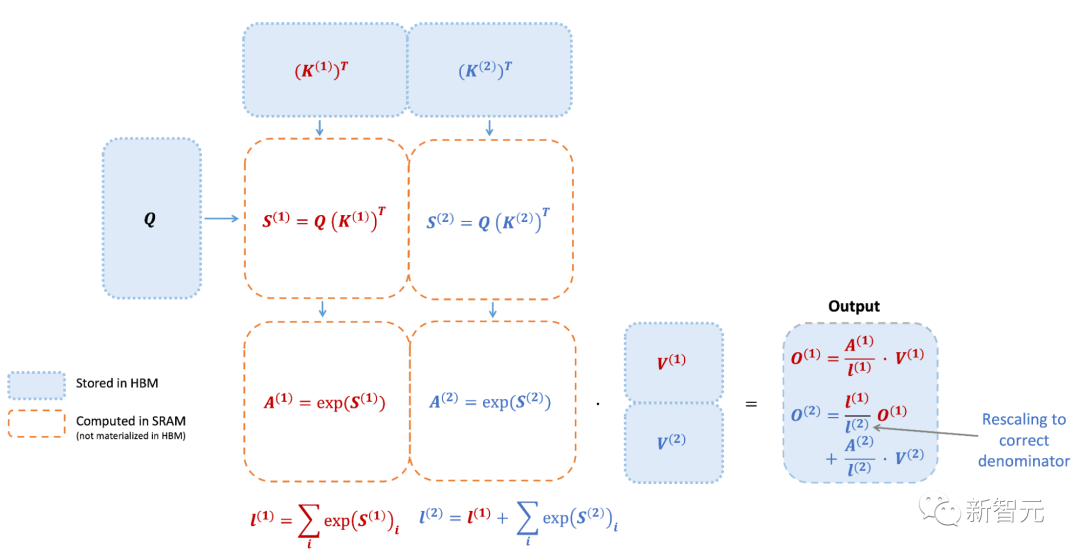
然而,FlashAttention仍然存在一些低效率的问题,这是由于不同线程块之间的工作划分并不理想,以及GPU上的warp——导致低占用率或不必要的共享内存读写。
更少的non-matmulFLOP(非矩阵乘法浮点计算数)
研究人员通过调整FlashAttention的算法来减少non-matmul FLOP的次数。这非常重要,因为现代GPU有专门的计算单元(比如英伟达GPU上的张量核心),这就使得matmul的速度更快。例如,A100 GPU FP16/BF16 matmul的最大理论吞吐量为312 TFLOPs/s,但non-matmul FP32的理论吞吐量仅为 19.5 TFLOPs/s。另外,每个非matmul FLOP比matmul FLOP要贵16倍。所以为了保持高吞吐量,研究人员希望在matmul FLOP上花尽可能多的时间。研究人员还重新编写了FlashAttention中使用的在线softmax技巧,以减少重新缩放操作的数量,以及边界检查和因果掩码操作,而无需更改输出。更好的并行性
FlashAttention v1在批大小和部数量上进行并行化处理。研究人员使用1个线程块来处理一个注意力头,共有 (batch_size * head number) 个线程块。
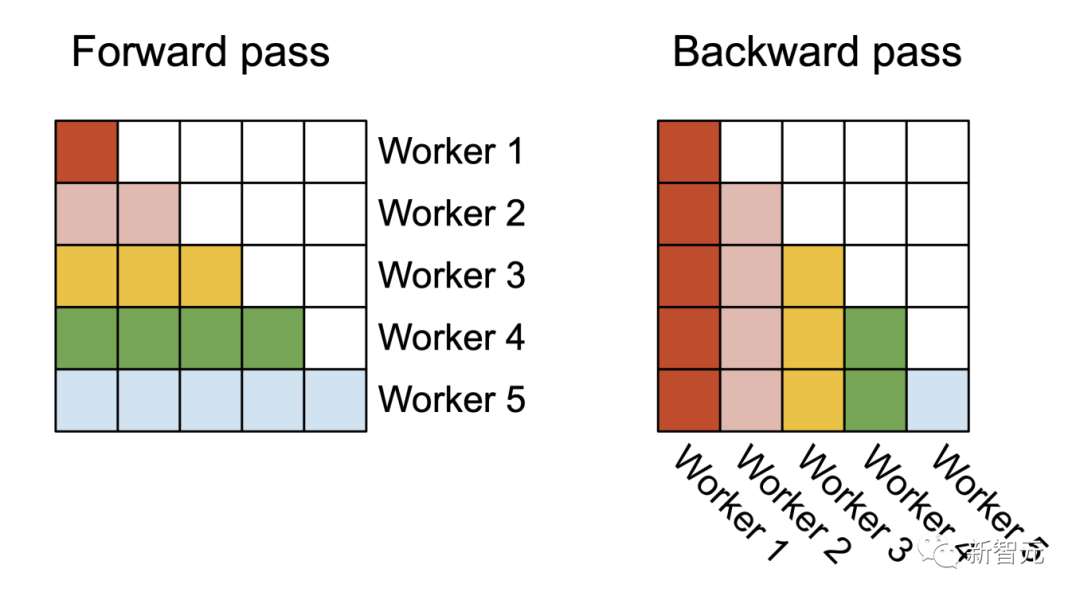
每个线程块都在流式多处理器 (SM)运行,例如,A100 GPU上有108个这样的处理器。当这个数字很大(比如 ≥80)时,这种调度是有效的,因为在这种情况下,可以有效地使用GPU上几乎所有的计算资源。在长序列的情况下(通常意味着更小批或更少的头),为了更好地利用GPU上的多处理器,研究人员在序列长度的维度上另外进行了并行化,使得该机制获得了显著加速。
更好的工作分区
即使在每个线程块内,研究人员也必须决定如何在不同的warp(线程束)之间划分工作(一组32个线程一起工作)。研究人员通常在每个线程块使用4或8个warp,分区方案如下图所示。研究人员在FlashAttention-2中改进了这种分区,减少了不同warp之间的同步和通信量,从而减少共享内存读/写。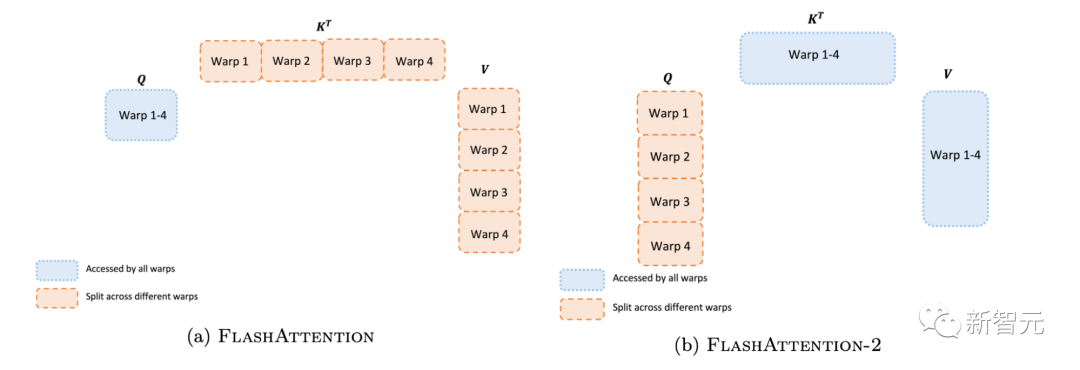 对于每个块,FlashAttention将K和V分割到4个warp上,同时保持Q可被所有warp访问。这称为「sliced-K」方案。然而,这样做的效率并不高,因为所有warp都需要将其中间结果写入共享内存,进行同步,然后再将中间结果相加。而这些共享内存读/写会减慢FlashAttention中的前向传播速度。在FlashAttention-2中,研究人员将Q拆分为4个warp,同时保持所有warp都可以访问K和V。在每个warp执行矩阵乘法得到Q K^T的一个切片后,它们只需与共享的V切片相乘,即可得到相应的输出切片。这样一来,warp之间就不再需要通信。共享内存读写的减少就可以提高速度。
对于每个块,FlashAttention将K和V分割到4个warp上,同时保持Q可被所有warp访问。这称为「sliced-K」方案。然而,这样做的效率并不高,因为所有warp都需要将其中间结果写入共享内存,进行同步,然后再将中间结果相加。而这些共享内存读/写会减慢FlashAttention中的前向传播速度。在FlashAttention-2中,研究人员将Q拆分为4个warp,同时保持所有warp都可以访问K和V。在每个warp执行矩阵乘法得到Q K^T的一个切片后,它们只需与共享的V切片相乘,即可得到相应的输出切片。这样一来,warp之间就不再需要通信。共享内存读写的减少就可以提高速度。
 新功能:头的维度高达256,多查询注意力
新功能:头的维度高达256,多查询注意力FlashAttention仅支持最大128的头的维度,虽说适用于大多数模型,但还是有一些模型被排除在外。FlashAttention-2现在支持256的头的维度,这意味着GPT-J、CodeGen、CodeGen2以及Stable Diffusion 1.x等模型都可以使用FlashAttention-2来获得加速和节省内存。v2还支持多查询注意力(MQA)以及分组查询注意力(GQA)。
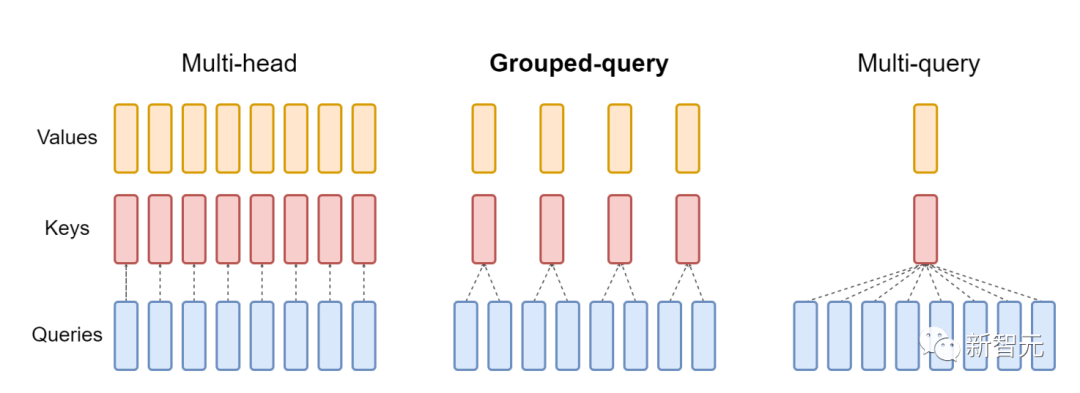
▲GQA为每组查询头共享单个key和value的头,在多头和多查询注意之间进行插值
这些都是注意力的变体,其中多个查询头会指向key和value的同一个头,以减少推理过程中KV缓存的大小,并可以显著提高推理的吞吐量。

注意力基准
研究人员人员在A100 80GB SXM4 GPU 上测量不同设置(有无因果掩码、头的维度是64或128)下不同注意力方法的运行时间。
 研究人员发现FlashAttention-2比第一代快大约2倍(包括在xformers库和Triton中的其他实现)。与PyTorch中的标准注意力实现相比,FlashAttention-2的速度最高可达其9倍。
研究人员发现FlashAttention-2比第一代快大约2倍(包括在xformers库和Triton中的其他实现)。与PyTorch中的标准注意力实现相比,FlashAttention-2的速度最高可达其9倍。
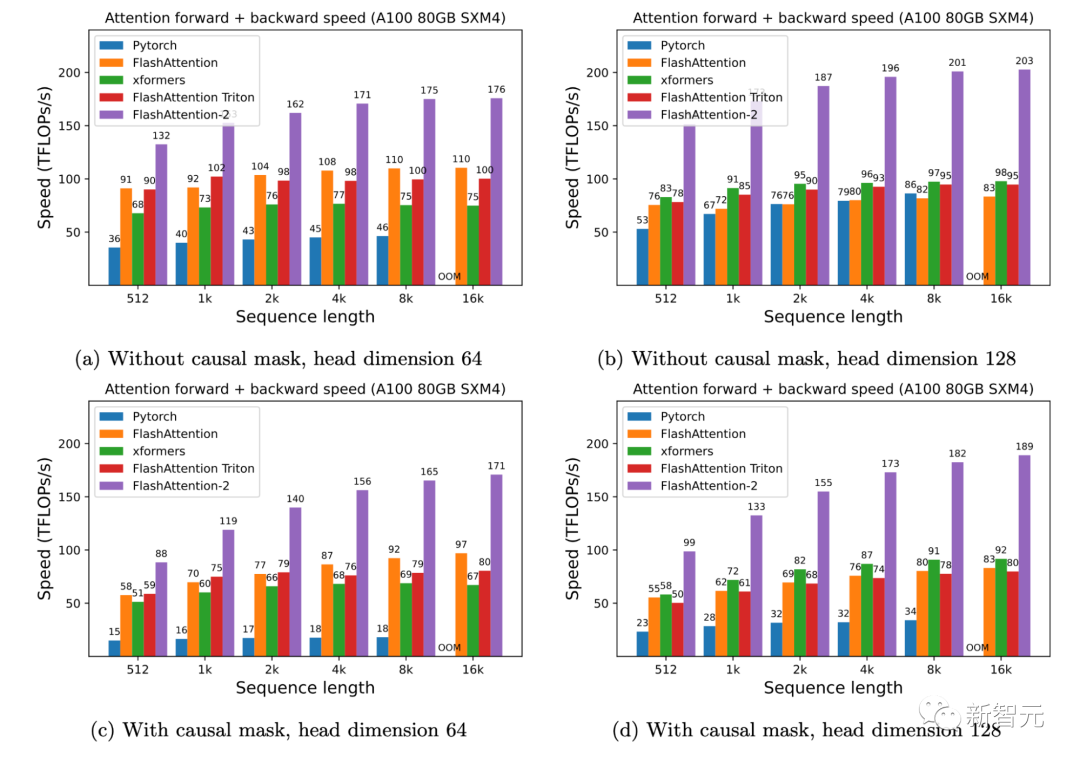
▲A100 GPU上的前向+后向速度
只需在H100 GPU上运行相同的实现(不需要使用特殊指令来利用TMA和第四代Tensor Core等新硬件功能),研究人员就可以获得高达335 TFLOPs/s的速度。
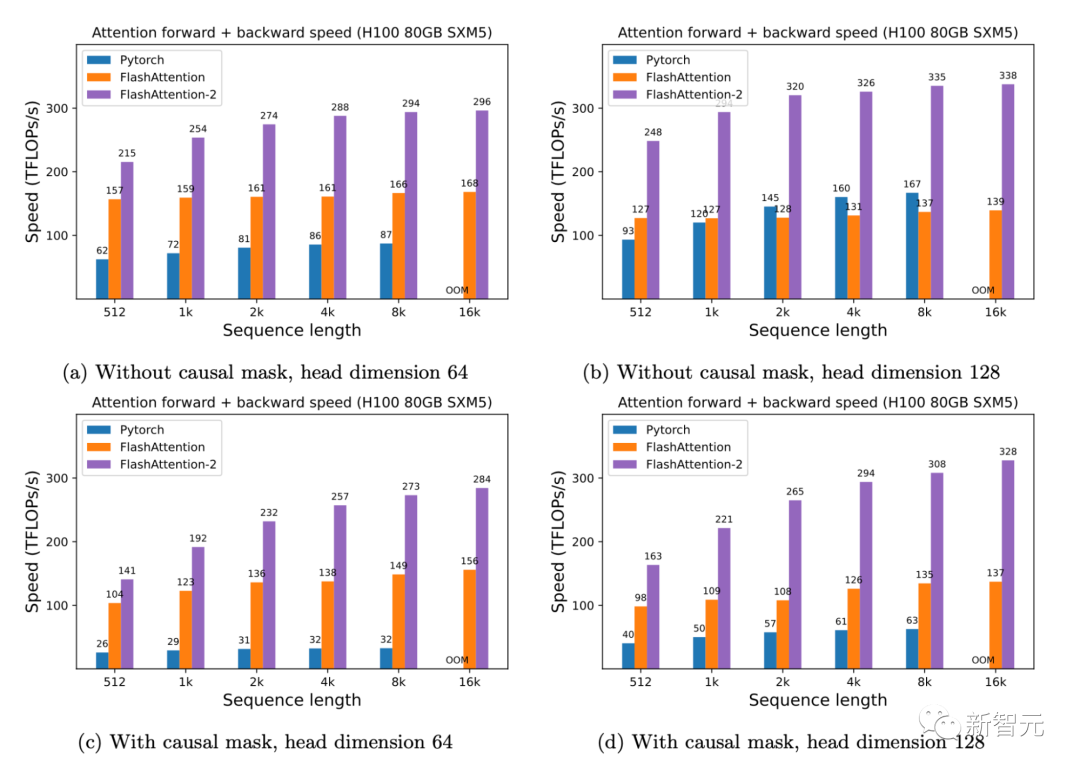
▲H100 GPU上的前向+后向速度
当用于端到端训练GPT类模型时,FlashAttention-2能在A100 GPU上实现高达225TFLOPs/s的速度(模型FLOPs利用率为72%)。与已经非常优化的FlashAttention模型相比,端到端的加速进一步提高了1.3倍。


未来的工作
速度上快2倍,意味着研究人员可以用与之前训练8k上下文模型相同的成本,来训练16k上下文长度的模型。这些模型可以理解长篇书籍和报告、高分辨率图像、音频和视频。同时,FlashAttention-2还将加速现有模型的训练、微调和推理。在不久的将来,研究人员还计划扩大合作,使FlashAttention广泛适用于不同类型的设备(例如H100 GPU、AMD GPU)以及新的数据类型(例如fp8)。下一步,研究人员计划针对H100 GPU进一步优化FlashAttention-2,以使用新的硬件功能(TMA、第四代Tensor Core、fp8等等)。将FlashAttention-2中的低级优化与高级算法更改(例如局部、扩张、块稀疏注意力)相结合,可以让研究人员用更长的上下文来训练AI模型。研究人员也很高兴与编译器研究人员合作,使这些优化技术更好地应用于编程。
 作者介绍
作者介绍Tri Dao曾在斯坦福大学获得了计算机博士学位,导师是Christopher Ré和Stefano Ermon。根据主页介绍,他将从2024年9月开始,任职普林斯顿大学计算机科学助理教授。
Tri Dao的研究兴趣在于机器学习和系统,重点关注高效训练和长期环境:- 高效Transformer训练和推理 - 远程记忆的序列模型 - 紧凑型深度学习模型的结构化稀疏性。
值得一提的是,Tri Dao今天正式成为生成式AI初创公司Together AI的首席科学家。

原文标题:让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2950文章
48121浏览量
418278
原文标题:让Attention提速9倍!FlashAttention燃爆显存,Transformer上下文长度史诗级提升
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
安信可AI语音模组支持MCP模型上下文协议
安信可 PalChat 系列(V1/V2)支持 MCP(模型上下文协议),工程师只需写几十行 C 代码,就能让 AI 模型直接控制硬件设备。V1 基于 Ai-WB2-12F,适合快速验证;V2
储能BMS遭遇“史诗级”加强
该产品在储能中只是一个纯成本投入,但随着新政策到来,BMS有望从成本变为“利润中心”,这对BMS而言,将是“史诗级”的加强。 行政分时电价的渐退 与 BMS的崛起 2026年开年,全国统一电力市场继续深化,而电力现货市场进一步普及,电
Ultrahuman使用Android Studio中的Gemini解决技术障碍并提升性能
Android Studio 中 Gemini 的上下文感知工具,Ultrahuman 团队得以简化和加速其开发流程。
大模型服务为什么总是爆显存
、上下文长度、框架预留与碎片。只盯参数量,很多故障会越修越贵:明明是请求画像变了,却被误判成卡不够;明明是参数贴边,却被误判成框架不稳。
NVIDIA BlueField-4为推理上下文记忆存储平台提供强大支持
随着代理式 AI 工作流将上下文窗口扩展到数百万个 token,并将模型规模扩展到数百万亿个参数,AI 原生企业正面临着越来越多的扩展挑战。这些系统目前依赖于智能体长期记忆来存储跨多轮、工具和会话持续保存的上下文,以便智能体能够基于先前的推理进行构建,而不是每次请求都从头

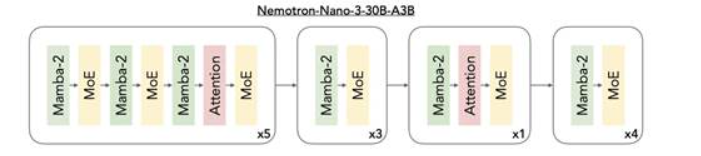
深入解析NVIDIA Nemotron 3系列开放模型
这一全新开放模型系列引入了开放的混合 Mamba-Transformer MoE 架构,使多智能体系统能够进行快速长上下文推理。
大语言模型如何处理上下文窗口中的输入
本博客介绍了五个基本概念,阐述了大语言模型如何处理上下文窗口中的输入。通过明确的例子和实践中获得的见解,本文介绍了多个与上下文窗口有关的基本概念,如词元化、序列长度和注意力等。

执行脱离上下文的威胁分析与风险评估
作为WITTENSTEIN high integrity system(WHIS)公司的核心产品,SAFERTOS专为安全关键型嵌入式系统设计,使其成为确保联网车辆环境可靠防护的理想选择。在本文中,我们将讨论如何开展SAFERTOS安全分析,结合威胁评估与风险评估(TARA)结果,以及这些实践方法的具体实施,最终推动SAFERTOS增强型安全模块的开发。遵循行业标准,该方法为管理风险并保护互联车辆组件免受不断演变的威胁提供了一个结构化的框架。
请问riscv中断还需要软件保存上下文和恢复吗?
以下是我拷贝的文档里的说明,这个中断处理还需要软件来写上下文保存和恢复,在使用ARM核的单片机都不需要考虑这些的,使用过的小伙伴能解答吗?
3.8. 进出中断的上下文保存和恢复
RISC-V架构
发表于 10-20 09:56
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM
当 GPT-4o 用毫秒级响应处理图文混合指令、Gemini-1.5-Pro 以百万 token 上下文 “消化” 长文档时,行业的目光正从云端算力竞赛转向一个更实际的命题:如何让智能 “落地
发表于 09-05 17:25
HarmonyOSAI编程智能问答
多线程?
指定上下文问答
在对话框中输入@符号,或点击上方@Add Context按钮,可指定对单个或多个代码文件进行分析。点击图标开启光标上下文功能,该功能可识别光标位置和选中的代码片段,让CodeGenie分析指定文件和选
发表于 09-03 16:17
【「DeepSeek 核心技术揭秘」阅读体验】+看视频+看书籍+国产开源大模型DeepSeekV3技术详解--1
大小的潜在向量 (Latent Vector) c_t 中。同时,为了保证对近期上下文的精确感知,它依然会实时计算当前 token 的 K 和 V。
最终,注意力机制的计算将同时作用于“压缩的历史
发表于 08-23 15:20
HarmonyOS AI辅助编程工具(CodeGenie)智能问答
Context按钮,可指定对单个或多个代码文件进行分析。点击
图标开启光标上下文功能,该功能可识别光标位置和选中的代码片段,让CodeGenie分析指定文件和选中的代码片段。
以上材料主要参考引用HarmonyOS官方文档。
发表于 08-15 11:07
鸿蒙NEXT-API19获取上下文,在class中和ability中获取上下文,API迁移示例-解决无法在EntryAbility中无法使用最新版
摘要:随着鸿蒙系统API升级至16版本(modelVersion5.1.1),多项API已废弃。获取上下文需使用UIContext,具体方法包括:在组件中使用getUIContext(),在类中使

Transformer架构中编码器的工作流程
编码器是Transformer体系结构的基本组件。编码器的主要功能是将输入标记转换为上下文表示。与早期独立处理token的模型不同,Transformer编码器根据整个序列捕获每个token的




评论