 用Chiplet解决ASIC在LLM上的成本问题
用Chiplet解决ASIC在LLM上的成本问题

电子发烧友网报道(文/周凯扬)虽说最近靠着GPT大语言模型的热度,英伟达之类的主流GPU公司赚得盆满钵满,但要说仗着GPU的高性能就能高枕无忧的话,也就未免有些痴人说梦了。未来随着LLM的继续发展,训练与推理如果要花费同样的硬件成本,那么即便是大厂也难以负担。
所以不少厂商都在追求如何削减TCO(总拥有成本)的办法,有的从网络结构出发,有的从自研ASIC出发的,但收效甚微,到最后还是得花大价钱购置更多的GPU。而来自华盛顿大学和悉尼大学的几位研究人员,在近期鼓捣出的Chiplet Cloud架构,却有可能颠覆这一现状。
TCO居高不下的因素
对于大部分厂商来说,纯粹的TCO并不是他们考虑的首要因素,他们更关注的是同一性能下如何实现更低的TCO。当下,限制GPU在LLM推理性能上的主要因素之一,不是Tensor核心的利用率,而是内存带宽。
比如在更小的batch size和普通的推理序列长度下,内存带宽就会限制对模型参数的读取,比如把参数从HBM加载到片上寄存器,因为全连接层中的GeMM(通用矩阵乘)计算强度不高,几乎每次计算都需要加载新的参数。
而Chiplet Cloud为了获得更好的TCO与性能比,选择了片上SRAM而不是HBM的外部内存方案,将所有模型参数和中间数据(比如K和V向量等)缓存到片上内存中去,从而实现了比传统的DDR、HBM2e更好的单Token TCO表现,同时也获得了更大的内存带宽。
Chiplet Cloud,作为基于chiplet的ASIC AI超算架构,正是专为LLM减少生成单个Token所需的TCO成本设计的。从他们给出的评估数据对比来看,与目前主流的GPU和TPU对比,只有Chiplet Cloud对于TCO/Token做了极致的优化。比如在GPT-3上,32个Chiplet Cloud服务器相较32个DGX A100服务器的TCO成本改善了94倍,在PaLM 540B上,30个Chiplet Cloud服务器相较64个TPUv4芯片将TCO改善了15倍。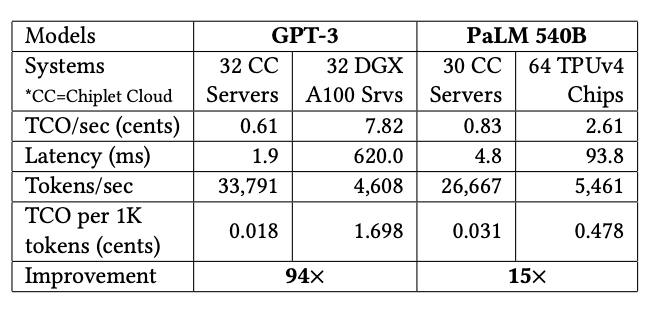
更灵活的Chiplet方案
为什么选择Chiplet呢?我们先来看一个极端的堆片上内存的例子,也就是直接选择晶圆级的“巨芯”,比如Cerebras Systems打造的WSE-2芯片。该芯片基于7nm工艺下的一整片12英寸晶圆打造,集成了2.6万亿个晶体管,面积达到46255mm2,片上内存更是达到了40GB。
但这样的巨芯设计意味着高昂的制造成本,所以Chiplet Cloud的研究人员认为更大的SRAM应该与相对较小的芯片对应,这样才能减少制造成本,所以他们选择了chiplet的设计方式。近来流行的Chiplet方案提高了制造良率,也减少了制造成本,允许在不同的系统层级上进行设计的重复利用。
以台积电7nm工艺为例,要想做到0.1/cm2的缺陷密度,一个750mm2芯片的单价是一个150mm2芯片单价的两倍,所以Chiplet的小芯片设计成本更低。重复利用的设计也可以进一步降低成本,加快设计周期,为ASIC芯片提供更高的灵活性。
Chiplet Cloud更适合哪些厂商
虽然论文中提到了不少Chiplet Cloud的优点,但这依然是一个尚未得到实际产品验证的架构,拥有验证实力的公司往往也只有微软、谷歌、亚马逊以及阿里巴巴这类具备芯片设计实力的公司。况且ASIC终究是一种特化的方案,最清楚云平台计算负载需要哪些优化,还得是云服务厂商自己。
-
芯片
+关注
关注
463文章
54463浏览量
469668 -
asic
+关注
关注
34文章
1278浏览量
124977 -
chiplet
+关注
关注
6文章
499浏览量
13655 -
LLM
+关注
关注
1文章
350浏览量
1397
发布评论请先 登录
Google正式发布LLM评测基准Android Bench

拥抱Chiplet,大芯片的必经之路

NVIDIA TensorRT Edge-LLM在汽车与机器人行业的落地应用
跃昉科技受邀出席第四届HiPi Chiplet论坛

PowerVR上的LLM加速:LLM性能解析


【CIE全国RISC-V创新应用大赛】+ 一种基于LLM的可通过图像语音控制的元件库管理工具
解构Chiplet,区分炒作与现实
NVIDIA TensorRT LLM 1.0推理框架正式上线
基于树莓派5+LLM8850 Card的高性能AI加速解决方案

DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
使用 llm-agent-rag-llamaindex 笔记本时收到的 NPU 错误怎么解决?
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

LM Studio使用NVIDIA技术加速LLM性能



评论