 LLM性能的主要因素
LLM性能的主要因素

现在是2023年5月,截止目前,网络上已经开源了众多的LLM,如何用较低的成本,判断LLM的基础性能,选到适合自己任务的LLM,成为一个关键。
本文会涉及以下几个问题:
影响LLM性能的主要因素
目前主要的模型的参数
LLaMA系列是否需要扩中文词表
不同任务的模型选择
影响LLM性能的主要因素
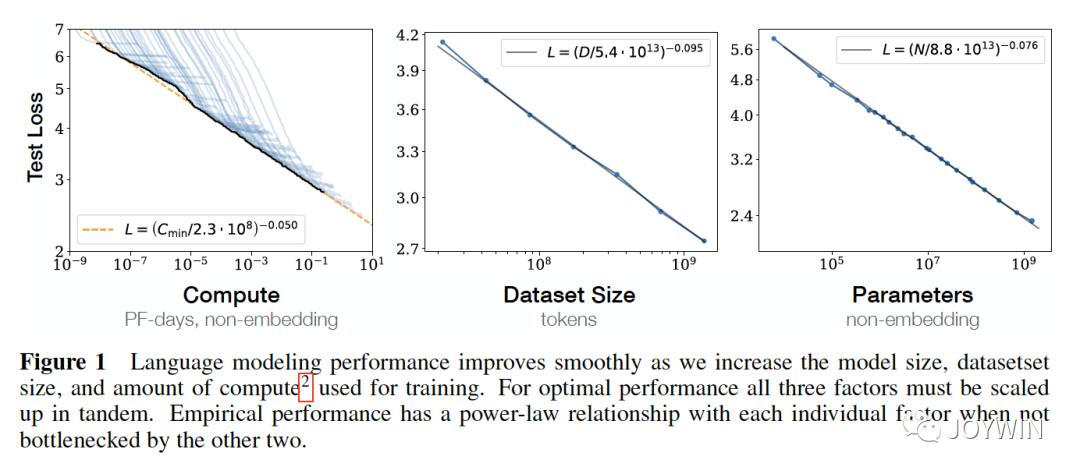
Scaling Laws for Neural Language Models
OpenAI的论文Scaling Laws中列举了影响模型性能最大的三个因素:计算量、数据集大小、模型参数量。也就是说,当其他因素不成为瓶颈时,计算量、数据集大小、模型参数量这3个因素中的单个因素指数增加时,loss会线性的下降。同时,DeepMind的研究也得出来和OpenAI类似的结论。那么我们可以基本确定,如果一个模型在这3个方面,均做的不错,那么将会是一个很好的备选。
模型参数量是我们最容易注意到的,一般而言,LLM也只在训练数据上训练1个epoch(如果还有算力,其实可以扩更多的新数据),那么,数据集的大小就是很关键的参数。训练OPT-175B的Susan Zhang在Stanford分享的时候,也提到了,如果能够重新再来一次,她会选择much much more data。可见数据量的重要性。
了解到Scaling Laws之后,为了降低模型的推理成本,可以在模型参数量降低的同时,增加训练的数据量,这样可以保证模型的效果。Chinchilla和LLaMA就是这样的思路。
除了以上的因素之外,还有一个比较大的影响因素就是数据质量。
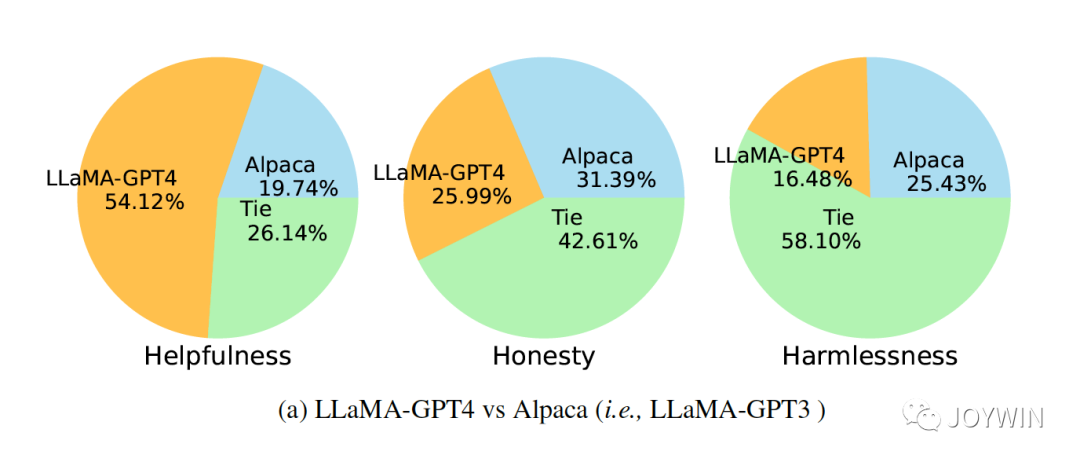
Instruction Tuning with GPT-4
在微软的论文中指出,同样基于LLaMA模型,使用GPT3和GPT4产生的数据,对模型进行Instruction Turing,可以看到GPT4的数据微调过的模型效果远远好于GPT3数据微调的模型,可见数据质量带来的影响。同样的,Vicuna的Instruction Turing中,也对shareGPT的数据做了很细致的清洗工作。
所以,如果没有数量级的差异,在Instruction Turing的时候,可以尽可能抛弃质量差的数据,保留高质量的数据。
目前主要的模型的参数
| 训练数据量 | 参数 | |
|---|---|---|
| LLaMA | 1T~1.4T tokens | 7B~65B |
| chatGLM-6B | 1T tokens | 6B |
根据我们上面的推理,训练数据量是对模型影响最关键的因素。LLaMA和chatGLM-6B是目前效果相对比较好的LLM,他们的训练数据都达到了至少1T tokens。那么如果一个LLM的训练数据量,少于1T tokens数的话,这个模型可以不用考虑了。
而LLaMA的参数量可以有7B、13B、33B、65B可以选择,那么在参数量上和可选择性上,比chatGLM要更优秀。那么,基于这些考虑,LLaMA系列及其变种,是当前更好的选择。而且,经过Instruction Turing之后,Vicuna已经表现出了非常好的性能,根据微软的论文(不是伯克利自己的论文),Vicuna已经达到90%的GPT4的效果。这一点和伯克利自己的结论也吻合。
在Vicuna的作者的博客中,作者也提到了vicuna-13B会比vicuna-7B效果好很多。笔者自己微调过这两个模型,13B确实会比7B的准确率高出5-10%。
同时,int8量化的Vicuna-13B在推理时,只需要20GB的显存,可以放进很多消费级的显卡中。
这么看起来,Vicuna-13B确实是一个很强的baseline,目前看到的开源LLM,只有WizardVicunaLM 的效果更优于Vicuna-13B。如果你没有很多时间调研,那么vicuna-13B会是一个不错的备选。
LLaMA系列是否需要扩中文词表
关于LLaMA的一个争论就是,LLaMA的base model是在以英语为主要语言的拉丁语系上进行训练的,中文效果会不会比较差?还有就是,LLaMA词表中的中文token比较少,需不需要扩词表?
针对问题一,微软的论文中已经验证了,经过Instruction Turing的Vicuna-13B已经有非常好的中文能力。
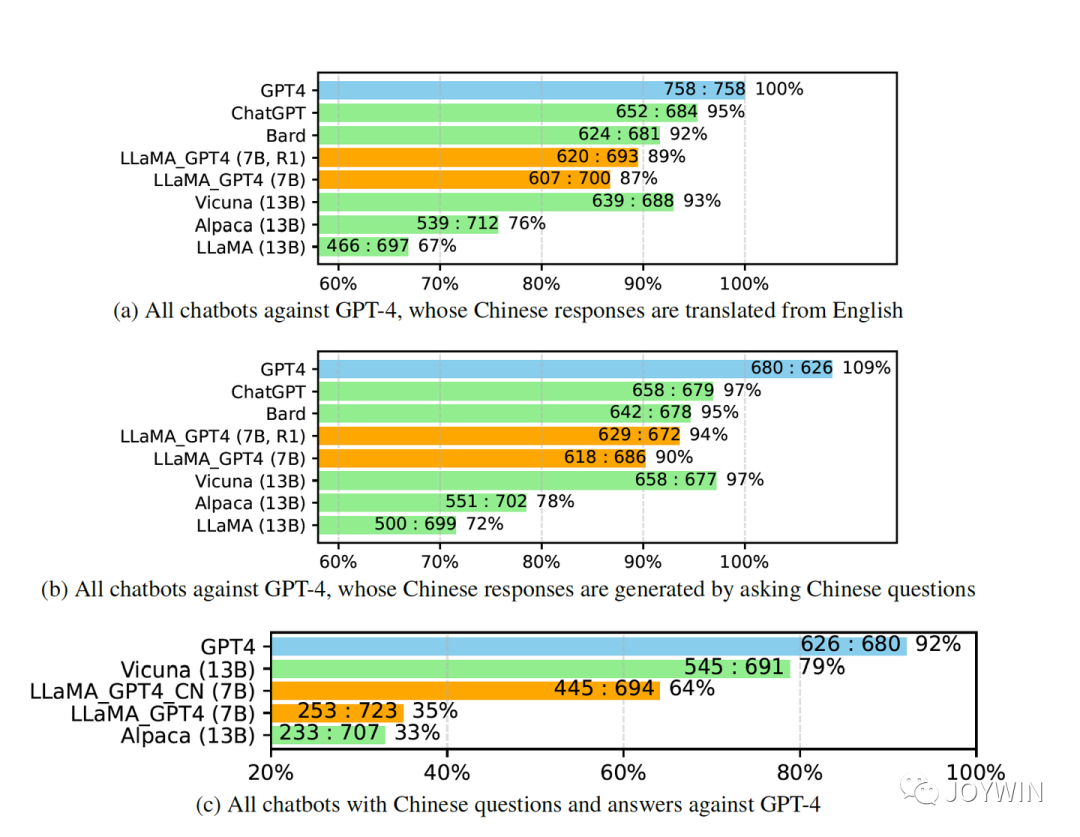
Instruction Tuning with GPT-4
那为什么没有在很多中文语料上训练过的LLaMA,能有这么好的中文能力呢?首先,在GPT4的技术报告中提到,即使在数据量很少的语言上,GPT4也有非常好的性能。
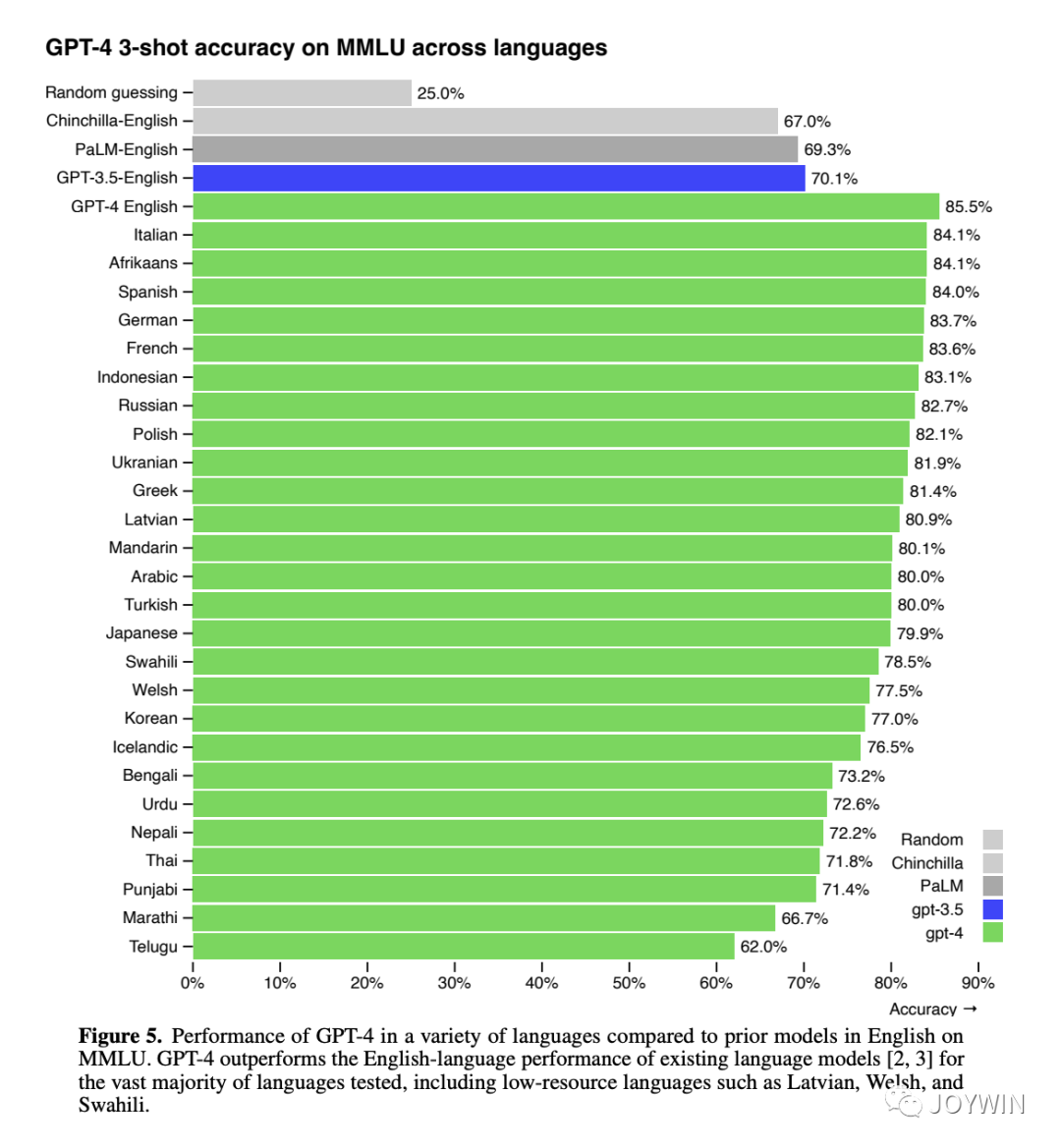
GPT-4 Technical Report
LLM表现出了惊人的跨语言能力。我猜其中一个比较重要的原始是采用了byte-level BPE算法构建词表。这种BBPE算法,将很多字符都拆分到byte级别。比如,虽然词表中没有对应的中文字符,但是可以通过组合byte,构建出来原始的中文字符。这部分可以参考文章Dylan:[分析] 浅谈ChatGPT的Tokenizer。因此,经过超大规模的语料训练之后,LLM可以跨不同的语言,表现出很好的性能。
采用BBPE的好处是可以跨语言共用词表,显著压缩词表的大小。而坏处就是,对于类似中文这样的语言,一段文字的序列长度会显著增长。因此,很多人会想到扩中文词表。但考虑到扩词表,相当于从头初始化开始训练这些参数。因此,参考第一节的结论,如果想达到比较好的性能,需要比较大的算力和数据量。如果没有很多数据和算力,就不太建议这么搞。
根据开源项目Chinese-LLaMA-Alpaca公布的数据,他们在使用120G的中文语料后(下图中的Alpaca-Plus-7B和Alpaca-Plus-13B),效果才有不错的提升,而在使用20G语料时(下图中的Alpaca-13B),效果还相对比较差。作为对比,原始的LLaMA使用的数据量大概是4T左右(此处是存储空间,不是token数)。
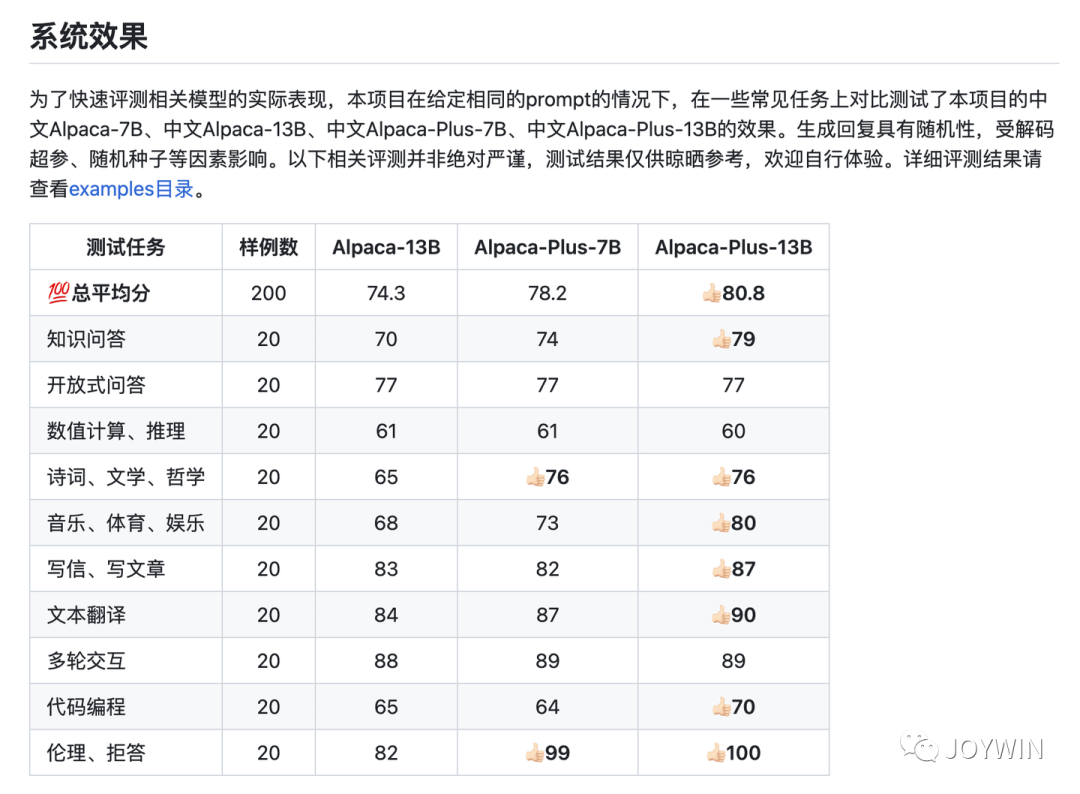
Chinese-LLaMA-Alpaca
因此,虽然扩词表看起来很诱人,但是实际操作起来,还是很有难度的,不过如果你有很多数据和算力,这个当我没说(不是)。
不同任务的模型选择
上文还提到,LLaMA系列的一大优势是,有很多不同大小的模型,从7B-65B。上面我们主要讨论了13B的模型,还有33B和65B的模型没有讨论。那什么场景下,13B的模型也不够,需要更大的模型呢?
答案就是,只要你的算力可以支持,就建议上更大的模型。
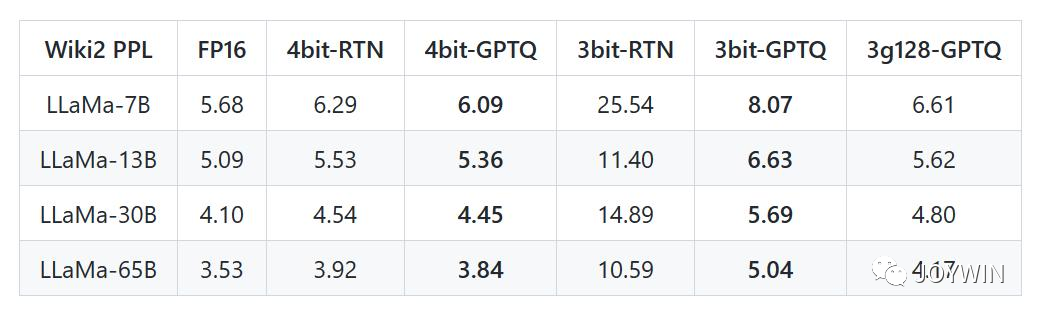
GPTQ-for-LLaMa
根据GPTQ-for-LLaMa 的数据,可以看到随着模型的增大,模型在wiki2数据上的困惑度一直在下降。更重要的是,LLaMA-33B经过int4量化之后,PPL低于LLaMA-13B!LLaMA-65B经过int4量化之后,PPL低于LLaMA-33B!并且,LLaMA-33B经过int4量化之后,推理只需要20GB的显存!!!
看到这个数据,我着实有点小激动。然后立马开始着手微调33B的模型!!!
当然,从推理成本的角度来看,模型参数量越小,成本越低。那什么情况下可以用小模型呢?回答是,需要根据任务的难易程度选择模型大小,如果任务很简单,其实小模型就OK。比如处理一些比较简单的中文任务,chatGLM-6B将会更合适。中文词表,再加上推理更好的优化,可以极大降低推理成本。
但如果任务很难,对于语义的理解程度很高,那么肯定是模型越大效果越好。有什么任务是比较难的任务呢?我们来看看什么任务让GPT4的觉得比较困难。
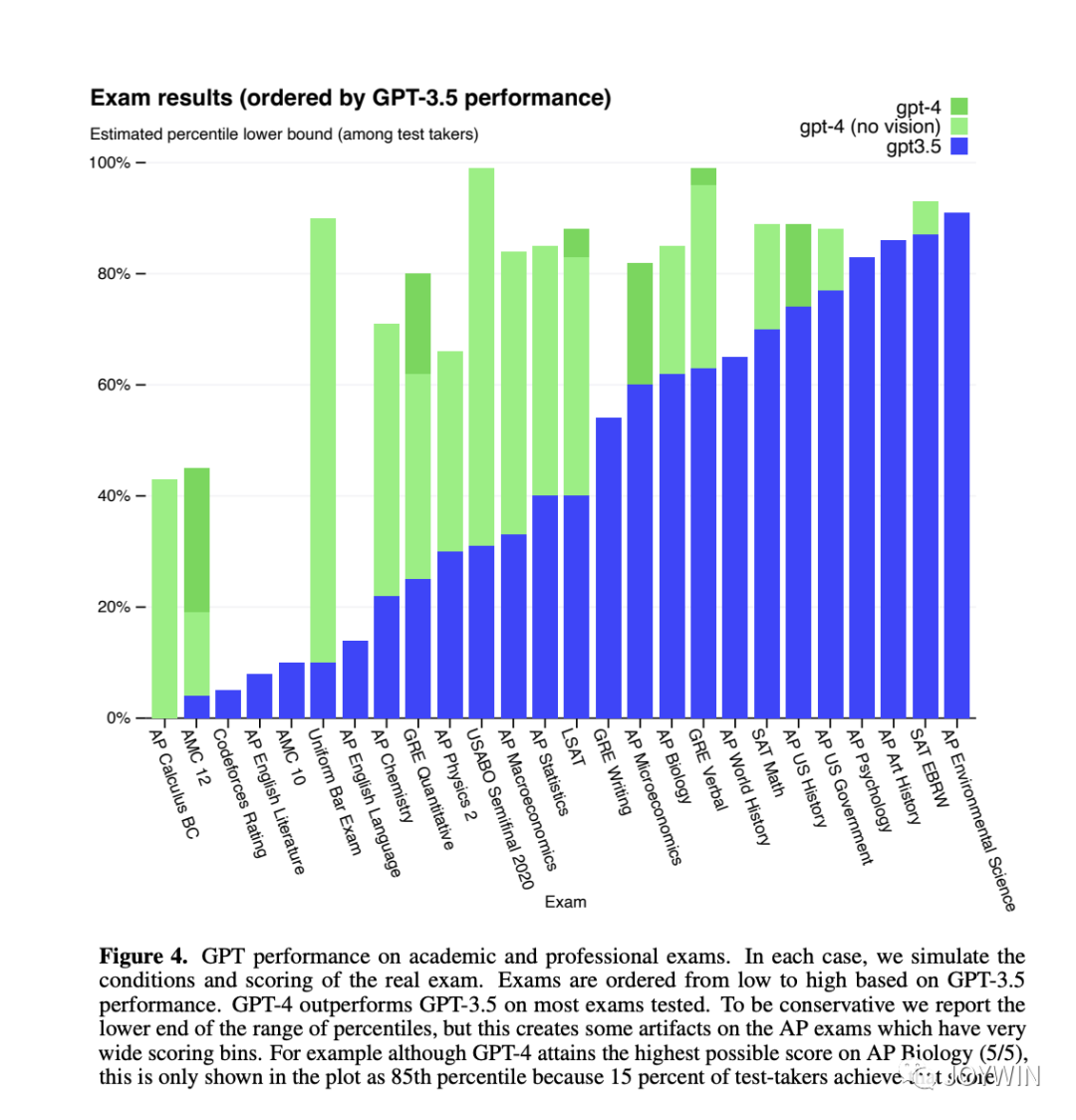
GPT-4 Technical Report
可以看到,GPT4表现最差的几个项目分别是Codeforces Rating、AP English Literature、AMC 10和AP English Language(AP是Advanced Placement,美国大学先修课程)。其中有两个分别是代码测试和数学测试,语言模型(LM)表现比较差符合预期。但是作为地表最强语言模型,在English Literature和English Language的考试中,这样的表现,是让人有点意外的。不过,话说回来,OpenAI对于GPT4的定位,还是一个工具型助手,而不是一个写文学性文字的模型。RLHF的作用,也是让模型,尽可能符合人对它的instruction。
因此,如果你的任务是,让LLM去写偏文学性的文章,应该要注意两个方面:1、任务本身有难度,尽可能上能力范围内的参数量更大的模型;2、数据层面,不要使用Instruction Turing的数据 ,而需要自己去找合适的高质量数据集。
-
模型
+关注
关注
1文章
3880浏览量
52363 -
数据集
+关注
关注
4文章
1242浏览量
26311 -
GPT
+关注
关注
0文章
376浏览量
17033 -
LLM
+关注
关注
1文章
352浏览量
1416
原文标题:大模型选型的一点思考
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
决定仿真精度的主要因素
影响步进电机性能的主要因素有哪些?
影响电机结构的主要因素有哪些
影响光纤跳线管理的4种主要因素



评论