 武大+上交提出BatGPT:创新性采用双向自回归架构,可预测前后token
武大+上交提出BatGPT:创新性采用双向自回归架构,可预测前后token

本论文介绍了一种名为BATGPT的大规模语言模型,由武汉大学和上海交通大学联合开发和训练。

该模型采用双向自回归架构,通过创新的参数扩展方法和强化学习方法来提高模型的对齐性能,从而更有效地捕捉自然语言的复杂依赖关系。

BATGPT在语言生成、对话系统和问答等任务中表现出色,是一种高效且多用途的语言模型。
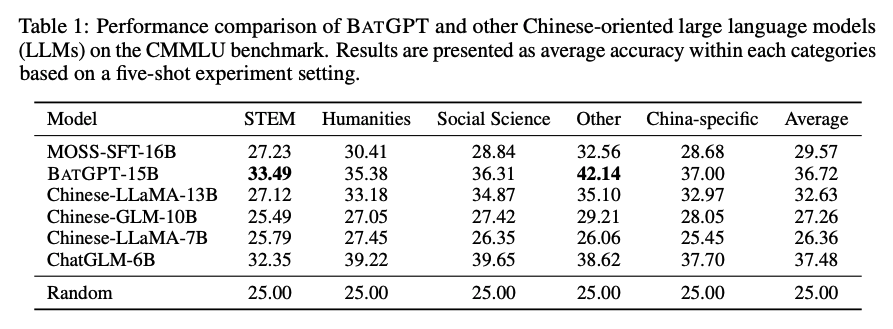
BATGPT 的双向自回归架构如何帮助其捕获自然语言的复杂依赖关系?
BATGPT的双向自回归架构可以同时考虑输入序列的前后文信息,从而更好地捕捉自然语言的复杂依赖关系。
传统的自回归模型只能考虑输入序列的前面部分,而BATGPT的双向自回归架构可以同时考虑前面和后面的信息,从而更好地理解整个输入序列的语义。
这种架构可以有效地解决传统模型中存在的“有限记忆”和“幻觉”问题,提高模型的生成质量和对齐性能。
BATGPT在训练方面提出的参数扩展方法是什么,它是如何提高模型有效性的?
BATGPT在训练方面提出了一种参数扩展方法,即在较小的模型上进行预训练,然后将预训练的参数扩展到更大的模型中。
这种方法可以有效地利用较小模型的预训练参数,从而加速更大模型的训练过程,并提高模型的有效性。
此外,BATGPT还采用了强化学习方法,从AI和人类反馈中学习,以进一步提高模型的对齐性能。这些方法的结合可以显著提高BATGPT的生成质量和对齐性能,使其成为一种高效且多用途的语言模型。
BATGPT 是否可以用于语言生成、对话系统和问答之外的应用程序?
BATGPT表现稳健,能够处理不同类型的提示,因此它具有广泛的能力,并适用于广泛的应用程序。
虽然文中没有明确提到BATGPT是否可以用于语言生成、对话系统和问答之外的应用程序,但是它的广泛能力表明它可以用于其他类型的应用程序。
-
应用程序
+关注
关注
38文章
3346浏览量
60453 -
语言模型
+关注
关注
0文章
575浏览量
11349 -
强化学习
+关注
关注
4文章
274浏览量
12006
原文标题:武大+上交提出 BatGPT:创新性采用双向自回归架构,可预测前后token
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
纤纳光电亮相2050大会AI Token秀
能够降低每Token成本的因素有哪些

可测 + AI 预测:光伏发电功率预测如何提升消纳与收益

工业设备预测性维护:从被动响应到主动防御的智能化转型
Token工厂加速兑现!迅策携手国家级数据交易所,深化垂类Token开发

详解Token经济:智能时代的价值标尺与产业全链路重构

Token中文新译名:「符元」——一文七个维度讲清Token的本质定义

模元(Token)工厂能源供应系统重构与SiC功率半导体赋能

线性回归的类型和应用

光伏四可装置硬件平台架构详解:计算单元、通信接口与可靠性设计
采用Prefetch+Cache架构有什么优势?
基于全局预测历史的gshare分支预测器的实现细节
九联科技亮相第十一届上交会
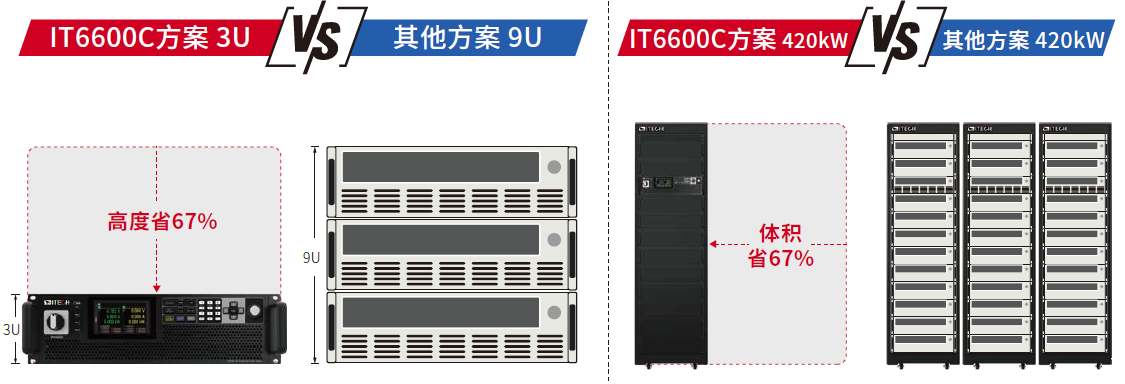
艾德克斯IT6600C 系列双向电源:大功率测试设备的新突破
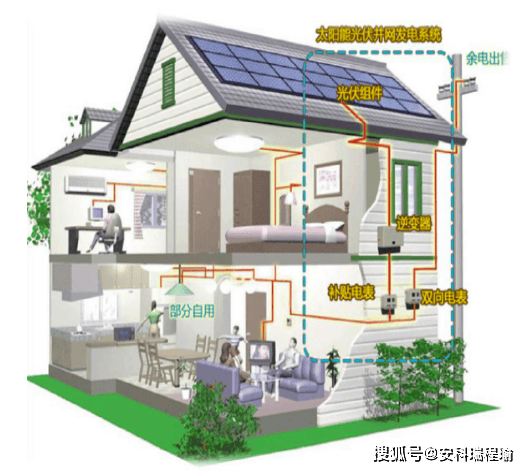
什么是光伏双向电表?双向电表有哪些应用?



评论