 Ampere的192核云原生CPU首度导入Chiplet设计
Ampere的192核云原生CPU首度导入Chiplet设计

Ampere Computing以自有IP打造的192核云原生CPU——AmpereOne系列处理器的技术细节陆续曝光。其中一个大亮点,是与上一代128核Ampere Altra对比,AmpereOne系列处理器中首度采用Chiplet设计。
半导体制程不断演进下,要实现复杂的芯片设计流程的门槛其实越来越高,芯片全流程设计的成本也大幅增加,这是摩尔定律放缓后出现的问题。因应方式是Chiplet小芯片设计的兴起,已经开始被AMD、英特尔等处理器大芯片公司大举采用。
Chiplet是一种模块化芯片的技术,将传统片上系统(SoC)所需的微处理器、模拟IP核、数字IP核和存储器等模块分开制造,并在后道工艺中集成为一个芯片模组,可实现不同模块的混用、复用,且各模块不需要在同一制程节点制造,因此另一个优势是能确保芯片的良率。
在AMD、英特尔陆续导入Chiplet设计后,Ampere Computing也在最新的AmpereOne系列处理器中实现Chiplet。
Ampere Computing首席产品官Jeff Wittich指出,Ampere开始大量采用小芯片的设计带来了许多的优势,像是提升灵活度,以及加快了整个芯片设计周期。再者,采用Chiplet的设计也实现了特定的拓扑结构,以及单一的计算裸片(里边分布着全部的内核),同时还有单一大网格结构,助力为客户提供平衡的高性能。反之,其他设计则要求数据从一个计算的小芯片传输到另一个小芯片,这种设计会带来延迟问题。
Jeff Wittich强调,在实现了最佳的Chiplet架构之后,产品上市的速度就会更快,且可以提供芯片的可扩展性。
过去几年间,Ampere Computing已经陆续实现的128核的Ampere Altra系列处理器,在云环境的关键指标——每机架性能方面超越其他竞品像是英特尔和AMD等。这次全新的AmpereOne系列处理器是采用台积电的5nm制程技术,现在已投产并交付给客户。
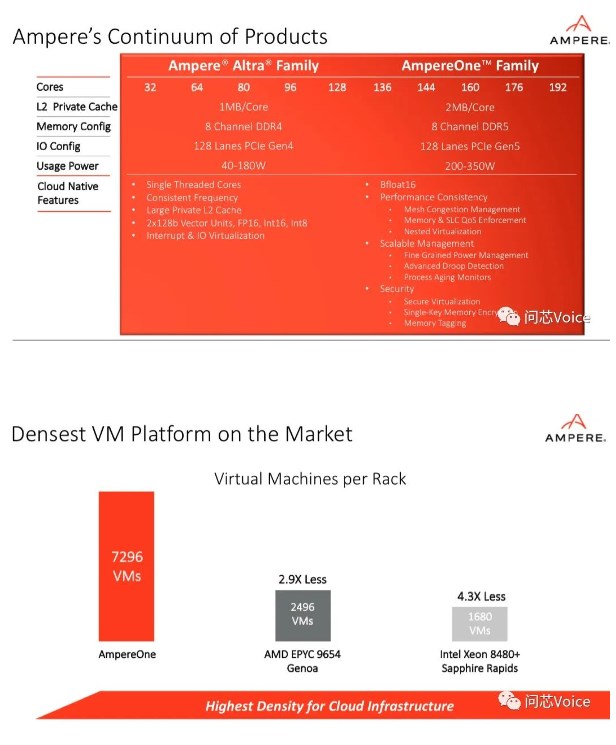
Jeff Wittich指出,AmpereOne能够为云工作负载提供更高的性能、更高的可扩展性以及更高的密度,也是第一款基于Ampere新自研核的产品,由Ampere自有IP全新打造,拥有多达192个单线程Ampere核。
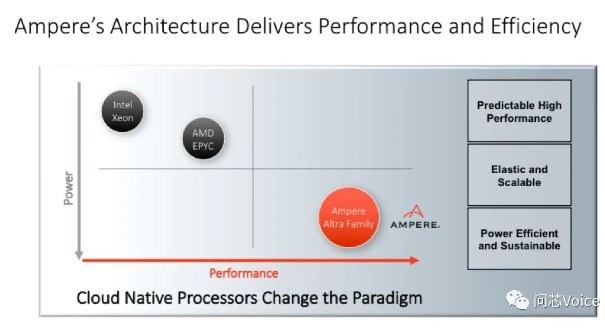
192 核是一个非常大的数字,比英特尔和 AMD 的核心数还要多。 Ampere用一个具体的场景来说明,比如在云环境中运行虚拟机(VM),用192核的AmpereOne对比96核的AMD Genoa,或者60核的英特尔Sapphire Rapids,AmpereOne每机架运行的虚拟机数量是AMD Genoa的2.9倍,是英特尔Sapphire Rapids的4.3倍。
AmpereOne推出后,与之前推出的Ampere Altra、Ampere Altra Max未来发展的差异性如何?
Jeff Wittich指出,这两个系列服务于不同的客户需求。目前已经在市场上持续交付的Ampere Altra系列,里面包含了几款不同的产品,核数从32核到128核不等。而全新推出的AmpereOne系列并不是要取代Ampere Altra系列,而是在它的原本的基础之上,进行持续的扩张。
在未来很长一段时间里,Ampere Altra 系列处理器还会继续销售,而最新的AmpereOne是在Ampere Altra Max 128核的基础上,将核数进一步提升到了最高可达192核。
客户如何决定要采用AmpereOne?还是Ampere Altra?
他分析,完全是看场景应用。在边缘计算的场景下,可能只需要部署32核、功耗40瓦的Ampere Altra处理器就够用了,但对于一些有更大算力需求的客户,譬如大规模的数据中心,这时候更高的核数可以提供更好的性能,所以可能需要192核的AmpereOne系列处理器。
在AI方面,Ampere也提供了几个参考的基准,一是在生成式AI方面,相比AMD Genoa,AmpereOne可每秒多提供2.3倍的帧数(图像),在运行稳定的扩散模型中胜出。此外,在运行DLRM模型的推荐系统中,通过AmpereOne响应的查询数量是AMD Genoa的每秒查询数量的两倍多。
此外,通过DDR5内存技术,以及128通道的PCIe 5.0的设计,AmpereOne系列处理器不仅实现了性能的扩展,也为云服务提供商和云工作负载提供价值。
由于新款的AmpereOne系列处理器是自研IP,是否会与上一代Ampere Altra系列有不相容的问题? Jeff Wittich表示,不会存在兼容性的问题,因为两款处理器都是基于ARM ISA的。所有能够在Ampere Altra系列处理器上运行的代码,在AmpereOne上运行也没有问题,不需要任何改动。
针对进行火爆的生成式AI对数据中心CPU市场的影响? Jeff Wittich表示,生成式AI进一步加速了市场对算力的需求。
他分析,针对AI工作负载最常见的有两大场景,第一是AI训练工作负载,即处理器在大量数据的基础上建立模型,对于某些大模型来说,过程有时候不只需要几个小时、几天,甚至可能要花上数周甚至数月的时间。第二个场景就是AI推理,即在完成AI训练的基础上,在应用上去运行模型。
虽然可能训练AI模型只需要一次,但是运行模型还需要进行上百万次甚至数十亿次,这些工作负载需要进行非常快速的运行,以尽可能快的速度向用户交付数据和资源。
AI训练和AI推理的工作负载是非常不一样的。 AI训练发生在服务器上的CPU、GPU,但是AI推理不一样,它扩展在整个云的部署中。这就意味着它对云的基础建设提出了更高的要求。
所以AI训练和AI推理有三个主要不同,一个是就规模而言,AI推理需要更大的规模;第二,AI推理很有可能在通用服务器上和其他工作负载同时运行;第三,AI推理对速度的要求更高,而且还需要不断地进行大量重复,以向用户快速交付结果。
Jeff Wittich表示,无论是Ampere Altra还是AmpereOne系列处理器都非常适用于AI推理,特别是大规模的云场景。目前,已经有许多客户都在使用Ampere Altra系列处理器进行AI推理,并且得到我们Library中很多软件工具的支持,包括TensorFlow、PyTorch、ONNX常用的主流框架。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20391浏览量
255694 -
片上系统
+关注
关注
0文章
205浏览量
27751 -
虚拟机
+关注
关注
1文章
976浏览量
30778 -
chiplet
+关注
关注
6文章
503浏览量
13676
原文标题:媒体视角|Ampere的192核云原生CPU首度导入Chiplet设计
文章出处:【微信号:AmpereComputing,微信公众号:安晟培半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
九同方亮相AI for Chiplet产业生态交流会
Chiplet,正在改变芯片制造

瀚高数据库深度参编国家标准《信息技术 云原生关系数据库管理系统技术要求》正式发布
低功耗 10 位 ADC——MAX192 的深度剖析与应用
云原生全球广域网架构深度科普:从单点集中到全域互联

LX2080释放复位瞬间启动电流过大,有什么办法让CPU核缓启动或者8个核分时依次启动吗?
【乾芯QXS320F开发板试用】ipc核间通信测试过程
E203软核提高CPU时钟频率方法
使用rk3568开发板,核0\\1\\3运行linux,核2运行hal,在核0中怎么关闭核2
解构Chiplet,区分炒作与现实

smp t113-s3 A7 多核cpu0 无法唤醒cpu1 核怎么解决?
KiCad 已支持导入 Altium 工程(Project)
单核CPU网关和双核CPU网关有什么区别
云原生环境里Nginx的故障排查思路




评论