 多个CPU各自的cache同步问题
多个CPU各自的cache同步问题

CACHE的一致性
Cache的一致性有这么几个层面
2.多个CPU各自的cache同步问题
3.CPU与设备(其实也可能是个异构处理器,不过在Linux运行的CPU眼里,都是设备,都是DMA)的cache同步问题
先看一下ICACHE和DCACHE同步问题。由于程序的运行而言,指令流的都流过icache,而指令中涉及到的数据流经过dcache。所以对于自修改的代码(Self-Modifying Code)而言,比如我们修改了内存p这个位置的代码(典型多见于JIT compiler),这个时候我们是通过store的方式去写的p,所以新的指令会进入dcache。但是我们接下来去执行p位置的指令的时候,icache里面可能命中的是修改之前的指令。
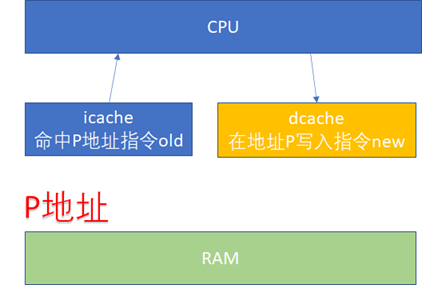
所以这个时候软件需要把dcache的东西clean出去,然后让icache invalidate,这个开销显然还是比较大的。
但是,比如ARM64的N1处理器,它支持硬件的icache同步,详见文档:The Arm Neoverse N1 Platform: Building Blocks for the Next-Gen Cloud-to-Edge Infrastructure SoC

特别注意画红色的几行。软件维护的成本实际很高,还涉及到icache的invalidation向所有核广播的动作。
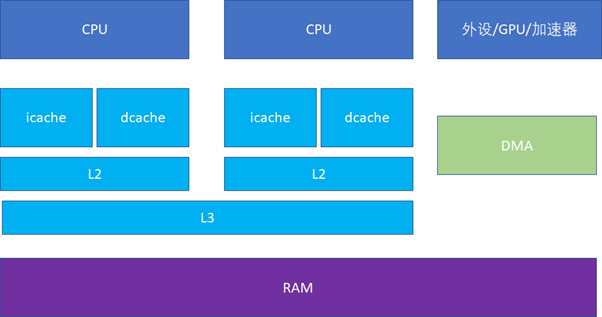
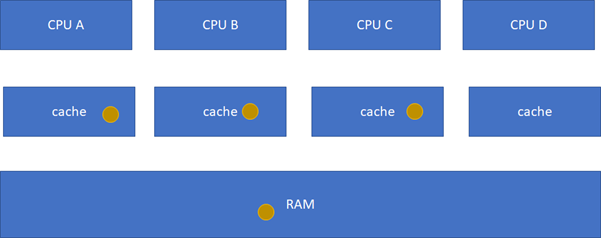
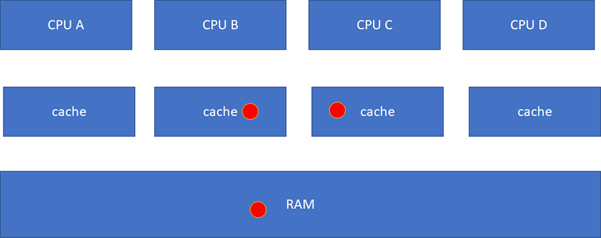
接下来的一个问题就是多个核之间的cache同步。下面是一个简化版的处理器,CPU_A和B共享了一个L3,CPU_C和CPU_D共享了一个L3。实际的硬件架构由于涉及到NUMA,会比这个更加复杂,但是这个图反映层级关系是足够了。
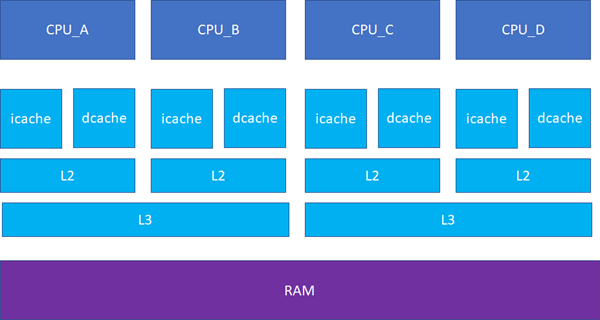
比如CPU_A读了一个地址p的变量?CPU_B、C、D又读,难道B,C,D又必须从RAM里面经过L3,L2,L1再读一遍吗?这个显然是没有必要的,在硬件上,cache的snooping控制单元,可以协助直接把CPU_A的p地址cache拷贝到CPU_B、C和D的cache。
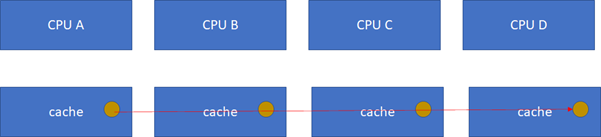
这样A-B-C-D都得到了相同的p地址的棕色小球。
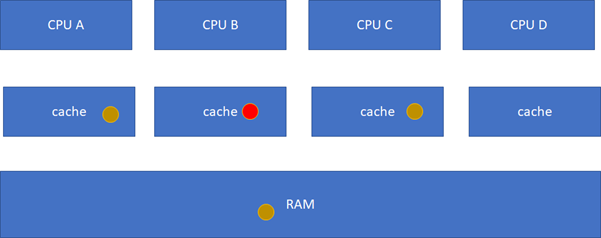
假设CPU B这个时候,把棕色小球写成红色,而其他CPU里面还是棕色,这样就会不一致了:
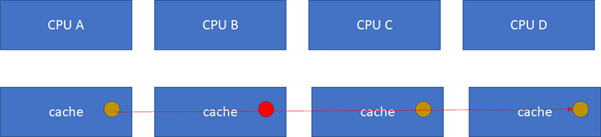
这个时候怎么办?这里面显然需要一个协议,典型的多核cache同步协议有MESI和MOESI。MOESI相对MESI有些细微的差异,不影响对全局的理解。下面我们重点看MESI协议。
MESI协议定义了4种状态:
M(Modified):当前cache的内容有效,数据已被修改而且与内存中的数据不一致,数据只在当前cache里存在;类似RAM里面是棕色球,B里面是红色球(CACHE与RAM不一致),A、C、D都没有球。
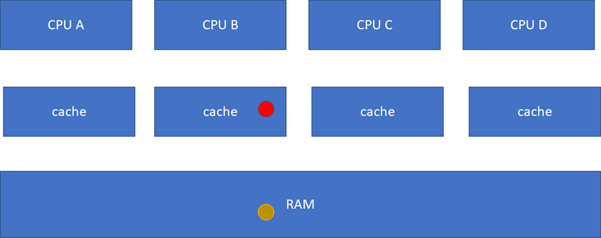
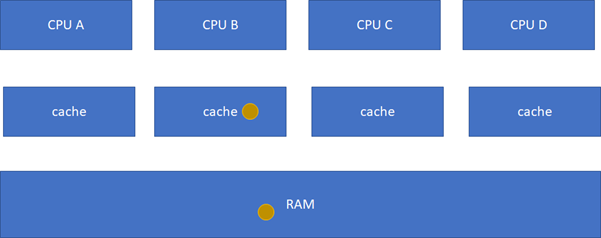
E(Exclusive):当前cache的内容有效,数据与内存中的数据一致,数据只在当前cache里存在;类似RAM里面是棕色球,B里面是棕色球(RAM和CACHE一致),A、C、D都没有球。
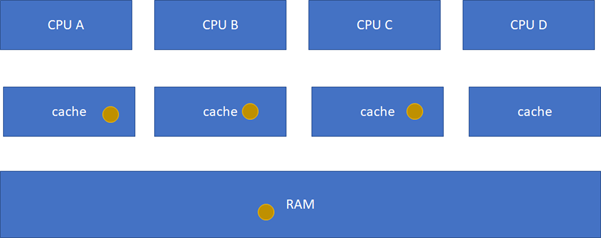
S(Shared):当前cache的内容有效,数据与内存中的数据一致,数据在多个cache里存在。类似如下图,在CPU A-B-C里面cache的棕色球都与RAM一致。
I(Invalid):当前cache无效。前面三幅图里面cache没有球的那些都是属于这个情况。
然后它有个状态机
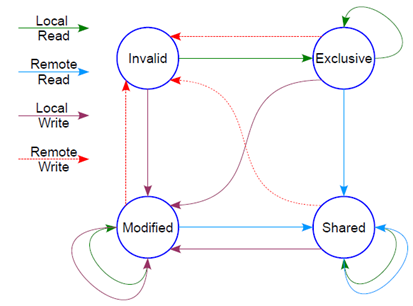
这个状态机比较难记,死记硬背是记不住的,也没必要记,它讲的cache原先的状态,经过一个硬件在本cache或者其他cache的读写操作后,各个cache的状态会如何变迁。所以,硬件上不仅仅是监控本CPU的cache读写行为,还会监控其他CPU的。只需要记住一点:这个状态机是为了保证多核之间cache的一致性,比如一个干净的数据,可以在多个CPU的cache share,这个没有一致性问题;但是,假设其中一个CPU写过了,比如A-B-C本来是这样:
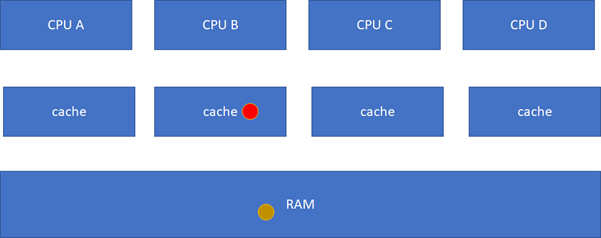
然后B被写过了:
这样A、C的cache实际是过时的数据,这是不允许的。这个时候,硬件会自动把A、C的cache invalidate掉,不需要软件的干预,A、C其实变地相当于不命中这个球了:
这个时候,你可能会继续问,如果C要读这个球呢?它目前的状态在B里面是modified的,而且与RAM不一致,这个时候,硬件会把红球clean,然后B、C、RAM变地一致,B、C的状态都变化为S(Shared):
这一系列的动作虽然由硬件完成,但是对软件而言不是免费的,因为它耗费了时间。如果编程的时候不注意,引起了硬件的大量cache同步行为,则程序的效率可能会急剧下降。
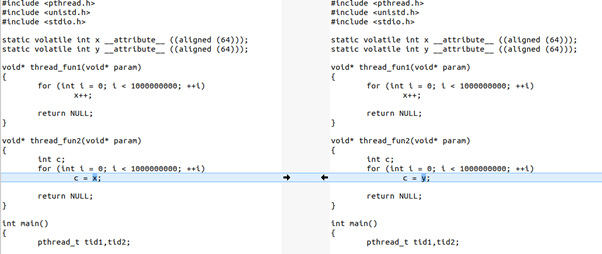
为了让大家直观感受到这个cache同步的开销,下面我们写一个程序,这个程序有2个线程,一个写变量,一个读变量:

这个程序里,x和y都是cacheline对齐的,这个程序的thread1的写,会不停地与thread2的读,进行cache同步。
它的执行时间为:
$ time ./a.out real 0m3.614s user 0m7.021s sys0m0.004s
它在2个CPU上的userspace共运行了7.021秒,累计这个程序从开始到结束的对应真实世界的时间是3.614秒(就是从命令开始到命令结束的时间)。
如果我们把程序改一句话,把thread2里面的c = x改为c = y,这样2个线程在2个CPU运行的时候,读写的是不同的cacheline,就没有这个硬件的cache同步开销了:
它的运行时间:
$ time ./b.out real 0m1.820s user 0m3.606s sys0m0.008s
现在只需要1.8秒,几乎减小了一半。
感觉前面那个a.out,双核的帮助甚至都不大。如果我们改为单核跑呢?
$ time taskset -c 0 ./a.out real 0m3.299s user 0m3.297s sys0m0.000s
它单核跑,居然只需要3.299秒跑完,而双核跑,需要3.614s跑完。单核跑完这个程序,甚至比双核还快,有没有惊掉下巴?!!!因为单核里面没有cache同步的开销。
下一个cache同步的重大问题,就是设备与CPU之间。如果设备感知不到CPU的cache的话(下图中的红色数据流向不经过cache),这样,做DMA前后,CPU就需要进行相关的cacheclean和invalidate的动作,软件的开销会比较大。
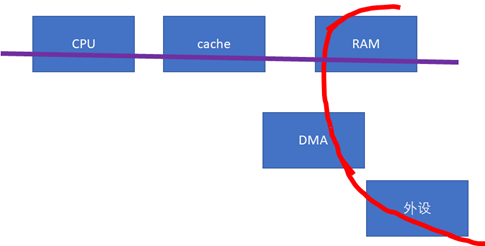
这些软件的动作,若我们在Linux编程的时候,使用的是streaming DMA APIs的话,都会被类似这样的API自动搞定:
dma_map_single() dma_unmap_single() dma_sync_single_for_cpu() dma_sync_single_for_device() dma_sync_sg_for_cpu() dma_sync_sg_for_device()
如果是使用的dma_alloc_coherent() API呢,则设备和CPU之间的buffer是cache一致的,不需要每次DMA进行同步。对于不支持硬件cache一致性的设备而言,很可能dma_alloc_coherent()会把CPU对那段DMA buffer的访问设置为uncachable的。
这些API把底层的硬件差异封装掉了,如果硬件不支持CPU和设备的cache同步的话,延时还是比较大的。那么,对于底层硬件而言,更好的实现方式,应该仍然是硬件帮我们来搞定。比如我们需要修改总线协议,延伸红线的触角:
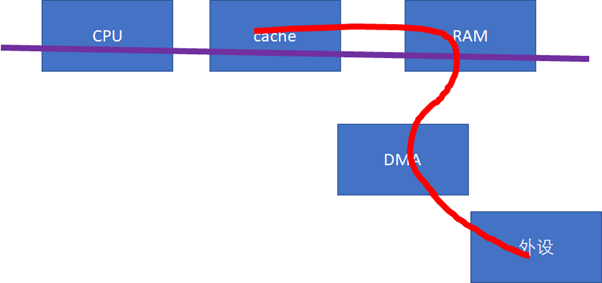
当设备访问RAM的时候,可以去snoop CPU的cache:
如果做内存到外设的DMA,则直接从CPU的cache取modified的数据;
如果做外设到内存的DMA,则直接把CPU的cache invalidate掉。
这样,就实现硬件意义上的cache同步。当然,硬件的cache同步,还有一些其他方法,原理上是类似的。注意,这种同步仍然不是免费的,它仍然会消耗bus cycles的。实际上,cache的同步开销还与距离相关,可以说距离越远,同步开销越大,比如下图中A、B的同步开销比A、C小。
对于一个NUMA服务器而言,跨NUMA的cache同步开销显然是要比NUMA内的同步开销大。
意识到CACHE的编程
通过上一节的代码,读者应该意识到了cache的问题不处理好,程序的运行性能会急剧下降。所以意识到cache的编程,对程序员是至关重要的。
从CPU流水线的角度讲,任何的内存访问延迟都可以简化为如下公式:
Average Access Latency = Hit Time + Miss Rate × Miss Penalty
cache miss会导致CPU的stall状态,从而影响性能。现代CPU的微架构分了frontend和backend。frontend负责fetch指令给backend执行,backend执行依赖运算能力和Memory子系统(包括cache)延迟。
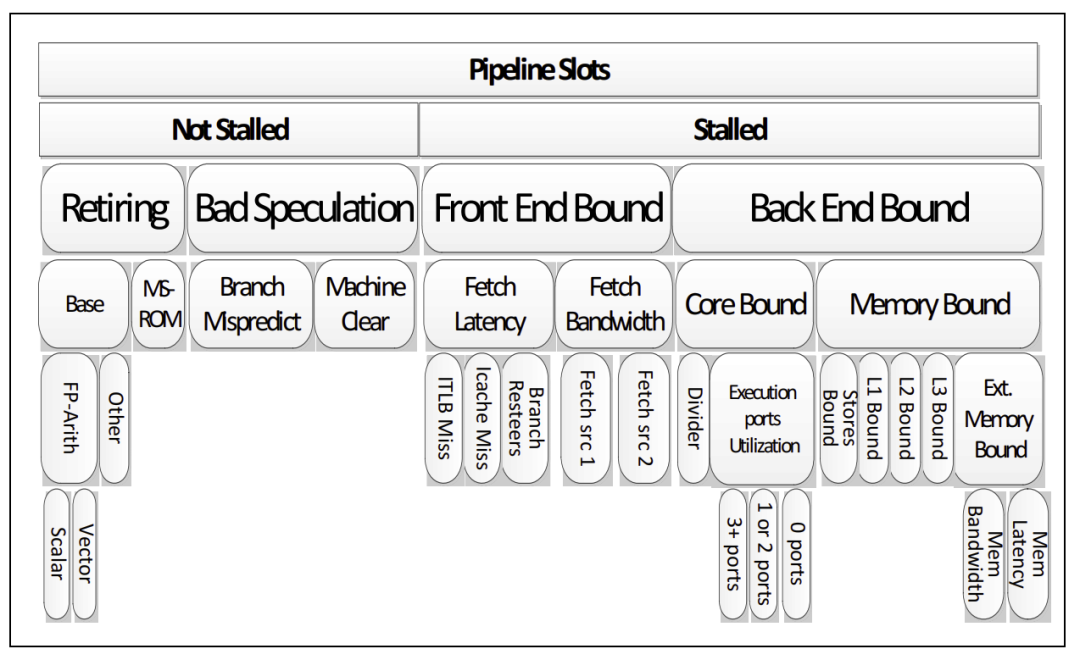
backend执行中访问数据导致的cache miss会导致backend stall,从而降低IPC(instructions per cycle)。减小cache的miss,实际上是一个软硬件协同设计的任务。比如硬件方面,它支持预取prefetch,通过分析cache miss的pattern,硬件可以提前预取数据,在流水线需要某个数据前,提前先取到cache,从而CPU流水线跑到需要它的时候,不再miss。当然,硬件不一定有那么聪明,也许它可以学会一些简单的pattern。但是,对于复杂的无规律的数据,则可能需要软件通过预取指令,来暗示CPU进行预取。
cache预取
比如在ARM处理器上就有一条指令叫pld,prefetch可以用pld指令:
static inline void prefetch(const void *ptr)
{
__asm__ __volatile__(
"pld %a0"
:: "p" (ptr));
}
眼见为实,我们随便从Linux内核里面找一个commit:
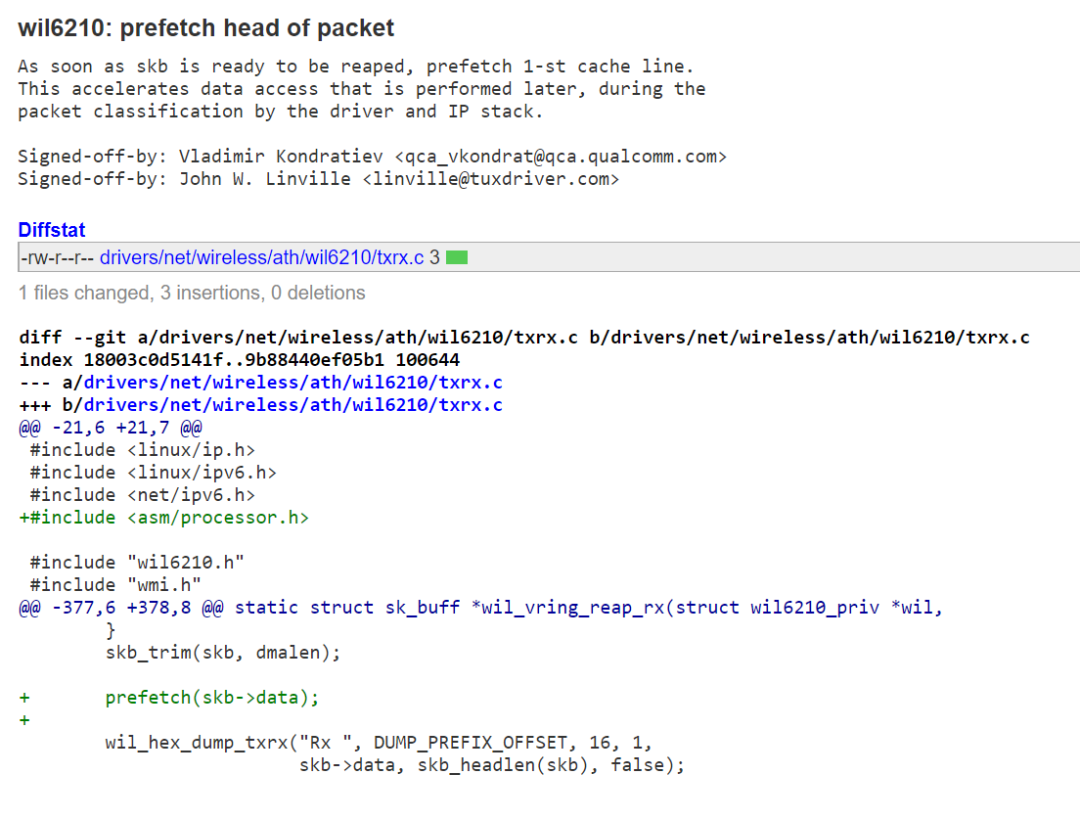
因为我们从WiFi收到了一个skb,我们很快就要访问这个skb里面的数据来进行packet的分类以及交给IP stack处理了,不如我们先prefetch一下,这样后面等需要访问这个skb->data的时候,流水线可以直接命中cache,从而不打断。
预取的原理有点类似今天星期五,咱们在上海office,下周一需要北京分公司的人来上海office开会。于是,我们通知北京office的人周末坐飞机过来,这样周一开会的时候就不必等他们了。不预取的情况下,会议开始后,再等北京的人飞过来,会导致stall状态。
任何东西最终还是要落实到代码,talk is cheap,show me the code。下面这个是经典的二分查找法代码,这个代码是网上抄的。
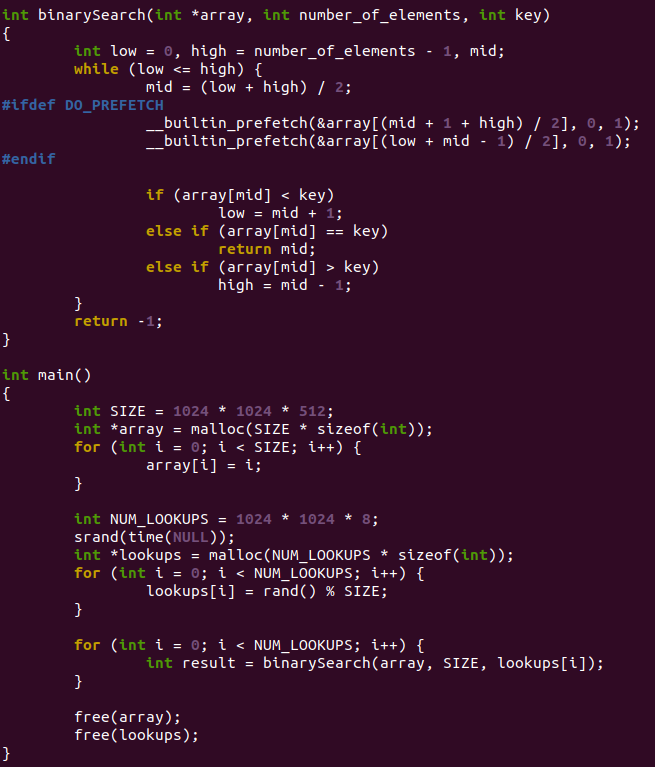
特别留意ifdef DO_PREFETCH包着的代码,它提前预取了下次的中间值。我们来对比下,不预取和预取情况下,这个同样的代码执行时间的差异。先把cpufreq的影响尽可能关闭掉,设置为performance:
barry@barry-HP-ProBook-450-G7:~$ sudo cpupower frequency-set --governor performance Setting cpu: 0 Setting cpu: 1 Setting cpu: 2 Setting cpu: 3 Setting cpu: 4 Setting cpu: 5 Setting cpu: 6 Setting cpu: 7
然后我们来对比差异:
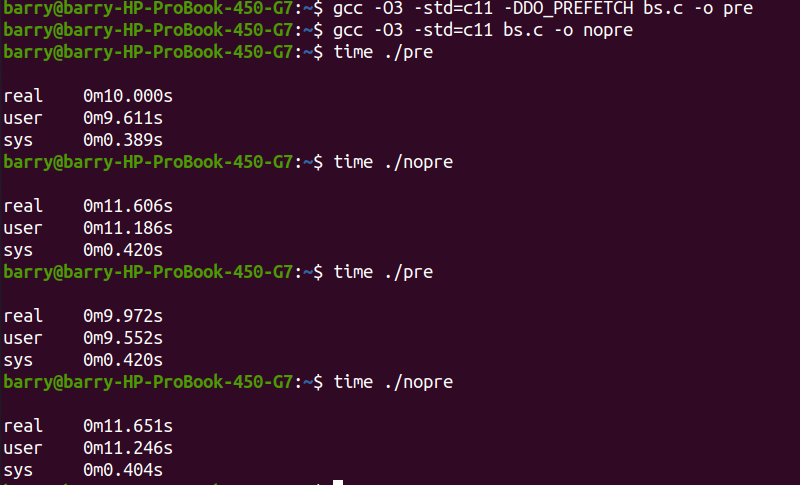
开启prefetch执行时间大约10s, 不prefetch的情况下,11.6s执行完成,性能提升大约14%,所以周末坐飞机太重要了!
现在我们来通过基于perf的pmu-tools(下载地址:https://github.com/andikleen/pmu-tools),对上面的程序进行topdown分析,分析的时候,为了尽可能减小其他因子的影响,我们把程序通过taskset运行到CPU0。
先看不prefetch的情况,很明显,程序是backend_bound的,其中DRAM_Bound占比大,达到75.8%。
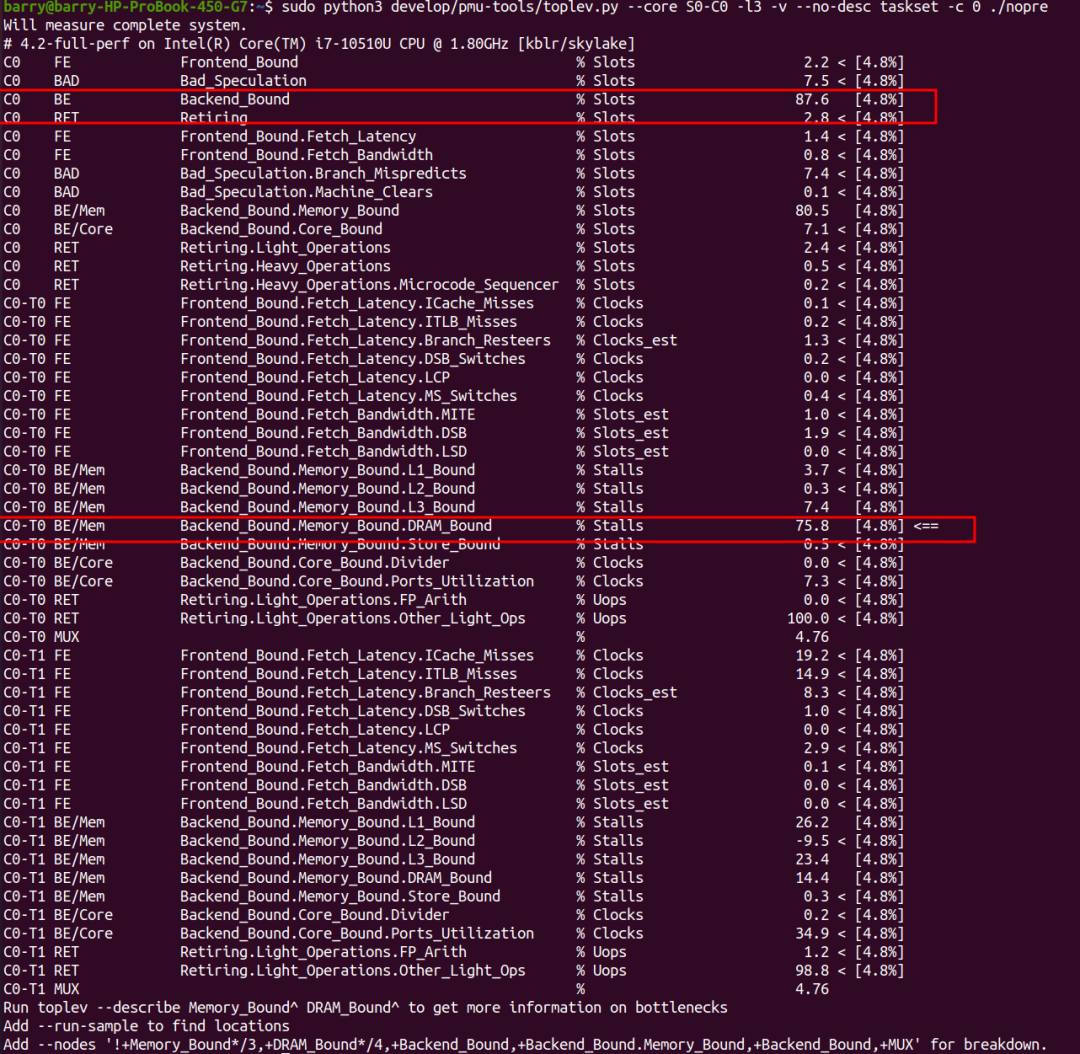
开启prefetch的情况呢?程序依然是backend_bound的,其中,backend bound的主体依然是DRAM_Bound,但是比例缩小到了60.7%。
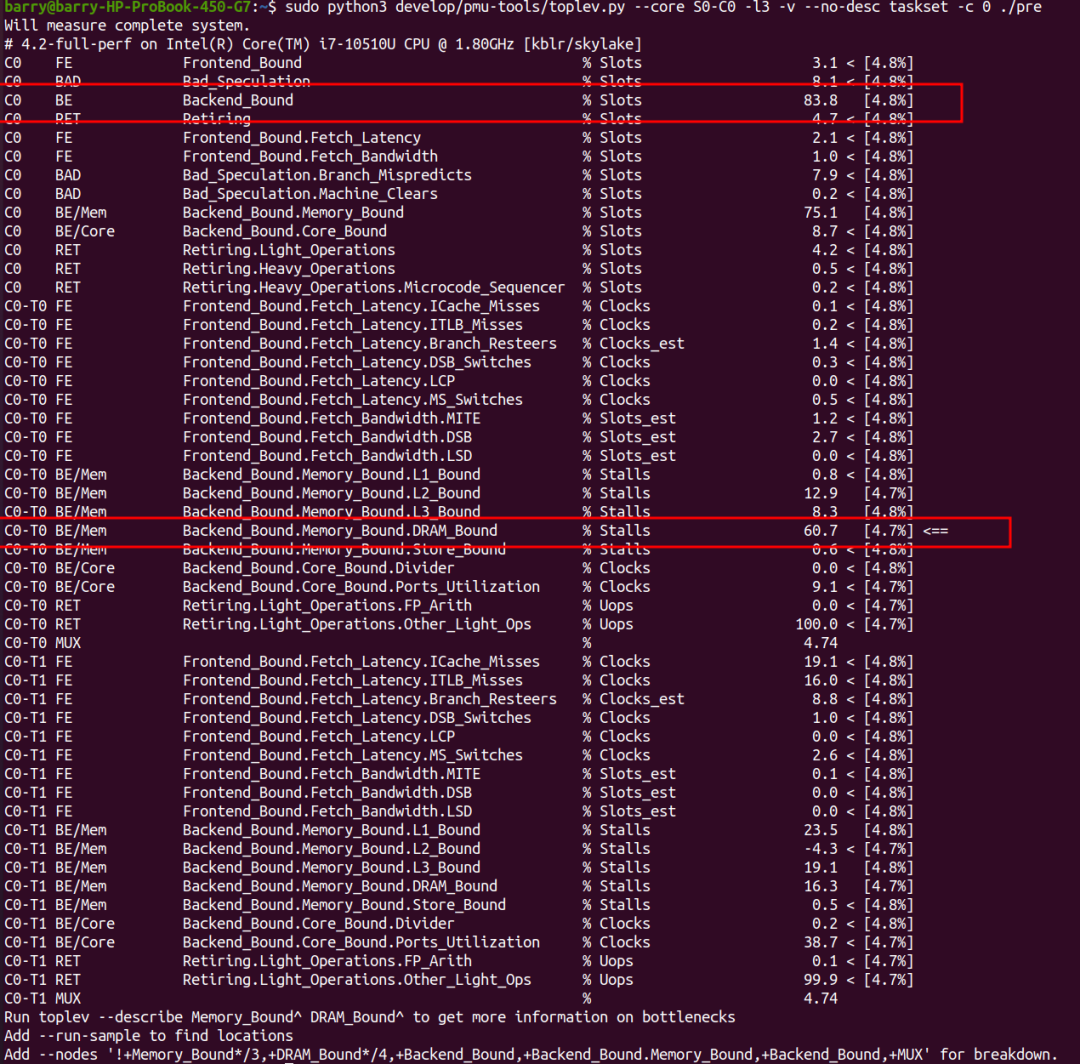
DRAM_Bound主要对应cycle_activity.stalls_l3_miss事件,我们通过perf stat来分别进行搜集:
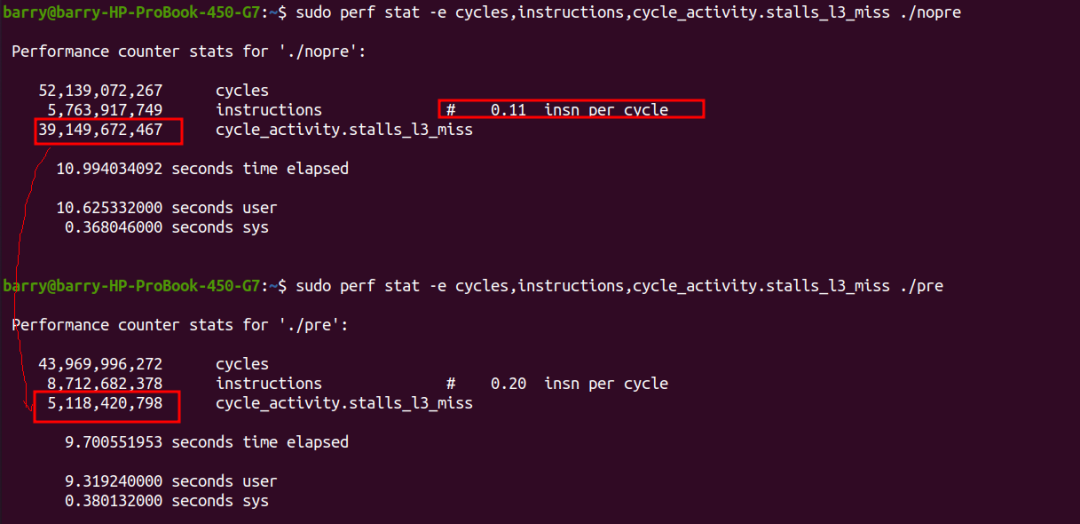
我们看到,执行prefetch情况下,指令的条数明显多了,但是它的insn per cycle变大了,所以总的时间cycles反而减小。其中最主要的原因是cycle_activity.stalls_l3_miss变小了很多次。
这个时候,我们可以进一步通过录制mem_load_retired.l3_miss来分析究竟代码哪里出了问题,先看noprefetch情况:

焦点在main函数:

继续annotate一下:
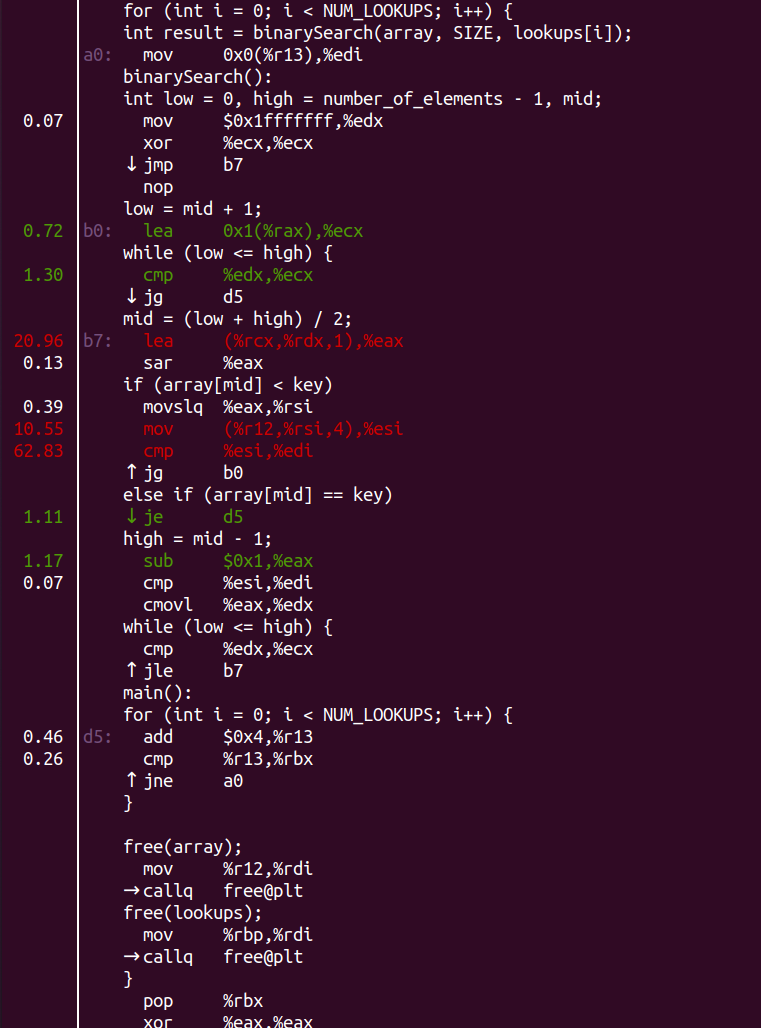
明显问题出在array[mid] < key这句话这里。做prefetch的情况下呢?

main的占比明显变小了(99.93% -> 80.00%):

继续annotate一下:
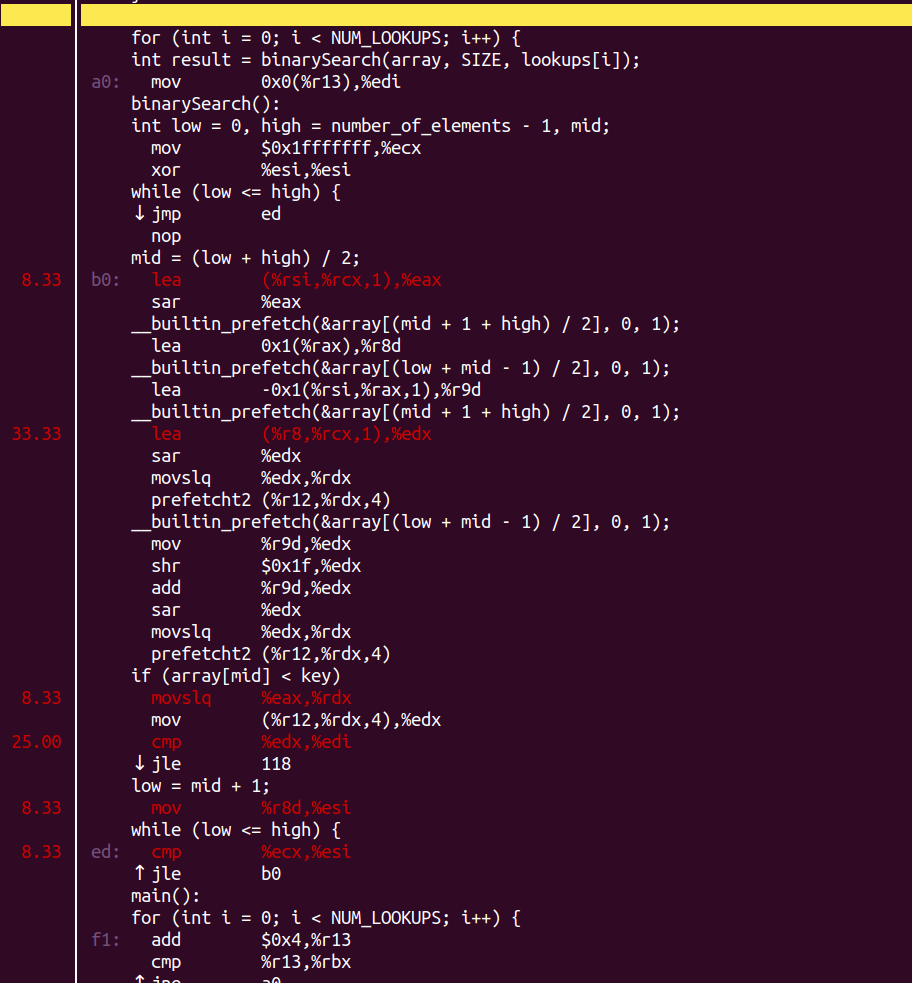
热点被分散了,预取缓解了Memory_Bound的情况。
避免false sharing
前面我们提到过,数据如果在一个cacheline,被多核访问的时候,多核间运行的cache一致性协议,会导致cacheline在多核间的同步。这个同步会有很大的延迟,是工程里著名的false sharing问题。
比如下面一个结构体
structs
{
inta;
intb;
}
如果1个线程读写a,另外一个线程读写b,那么两个线程就有机会在不同的核,于是产生cacheline同步行为的来回颠簸。但是,如果我们把a和b之间padding一些区域,就可以把这两个缠绕在一起的人拉开:
struct s
{
int a;
charpadding[cacheline_size-sizeof(int)];
int b;
}
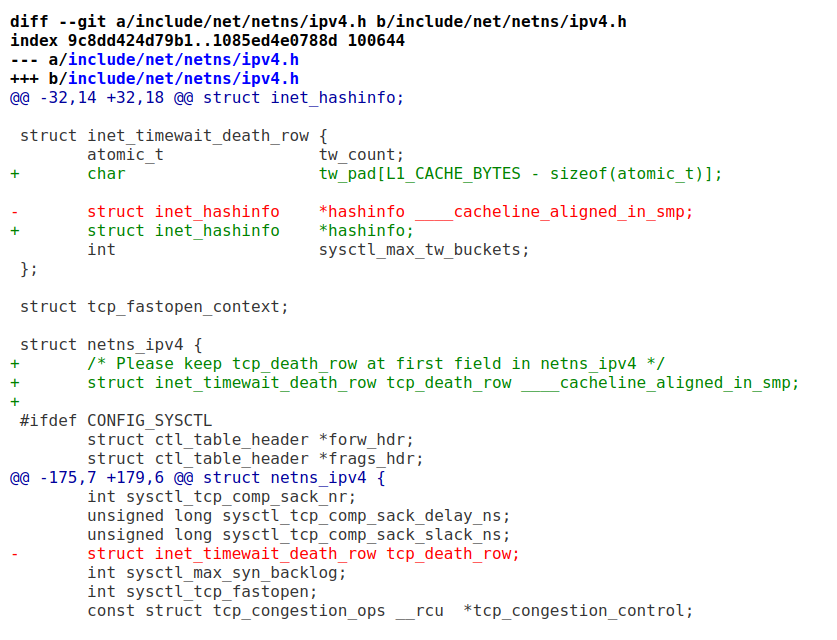
因此,在实际的工程中,我们经常看到有人对数据的位置进行移位,或者在2个可能引起false sharing的数据间填充数据进行padding。这样的代码在内核不甚枚举,我们随便找一个:

它特别提到在tw_count后面60个字节(L1_CACHE_BYTES - sizeof(atomic_t))的padding,从而避免false sharing:
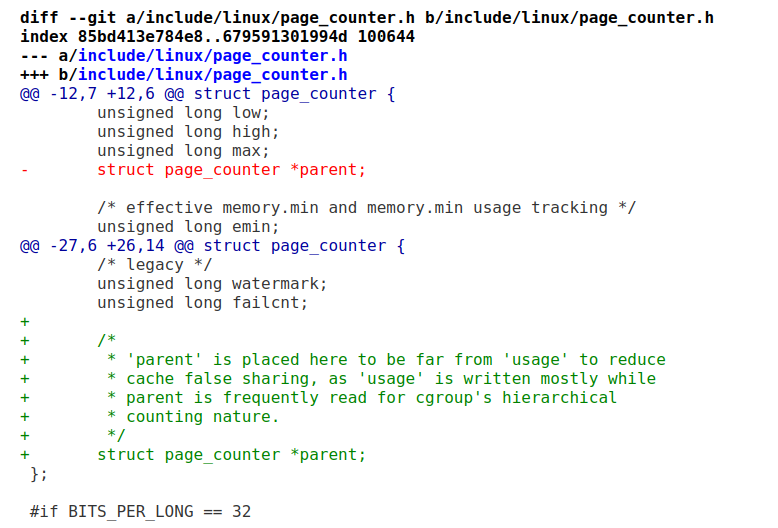
下面这个则是通过移动结构体内部成员的位置,相关数据的cacheline分开的:

这个改动有明显的性能提升,最高可达9.9%。代码里面也有明显地注释,usage和parent原先靠地太近,一个频繁写,一个频繁读。移开了2边互相不打架了:
把理论和代码能对上的感觉真TNND爽。无论是996,还是007,都必须留些时间来思考,来让理论和实践结合,否则,就变成漫无目的的内卷,这样一定会卷输的。内卷并不可悲,可悲的是卷不赢别人。
1. 什么是CPU Cache?
如图所示:
CPU Cache可以理解为CPU内部的高速缓存,当CPU从内存中读取数据时,并不是只读自己想要的那一部分,而是读取更多的字节到CPU高速缓存中。当CPU继续访问相邻的数据时,就不必每次都从内存中读取,可以直接从高速缓存行读取数据,而访问高速缓存比访问内存速度要快的多,所以速度会得到极大提升。
2. 为什么要有Cache?为什么要有多级Cache?
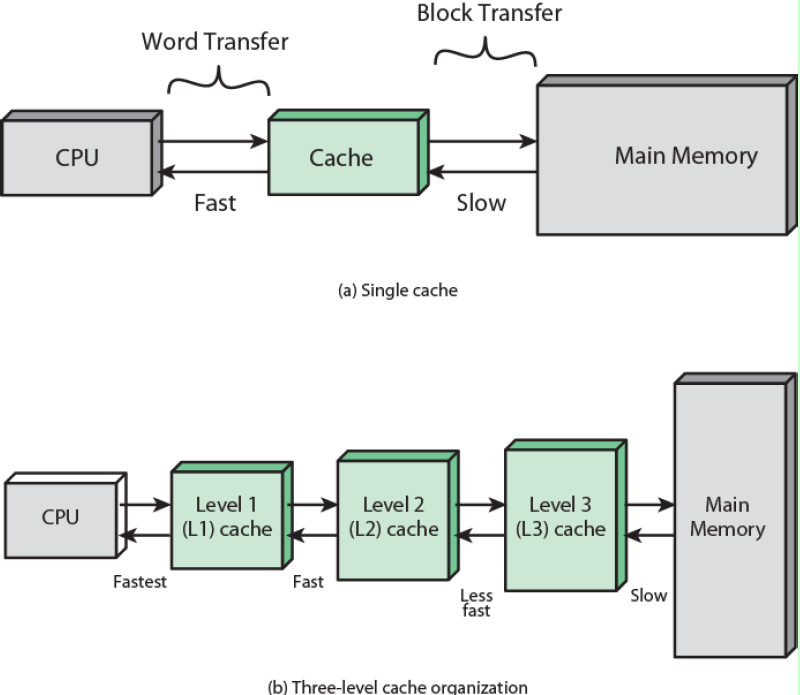
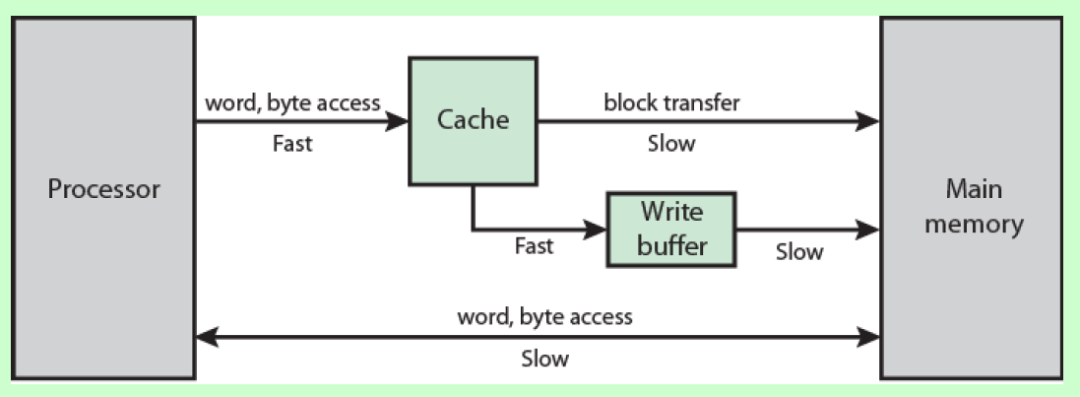
为什么要有Cache这个问题想必大家心里都已经有了答案了吧,CPU直接访问距离较远,容量较大,性能较差的主存速度很慢,所以在CPU和内存之间插入了Cache,CPU访问Cache的速度远高于访问主存的速度。
CPU Cache是位于CPU和内存之间的临时存储器,它的容量比内存小很多但速度极快,可以将内存中的一小部分加载到Cache中,当CPU需要访问这一小部分数据时可以直接从Cache中读取,加快了访问速度。
想必大家都听说过程序局部性原理,这也是CPU引入Cache的理论基础,程序局部性分为时间局部性和空间局部性。时间局部性是指被CPU访问的数据,短期内还要被继续访问,比如循环、递归、方法的反复调用等。空间局部性是指被CPU访问的数据相邻的数据,CPU短期内还要被继续访问,比如顺序执行的代码、连续创建的两个对象、数组等。因为如果将刚刚访问的数据和相邻的数据都缓存到Cache时,那下次CPU访问时,可以直接从Cache中读取,提高CPU访问数据的速度。
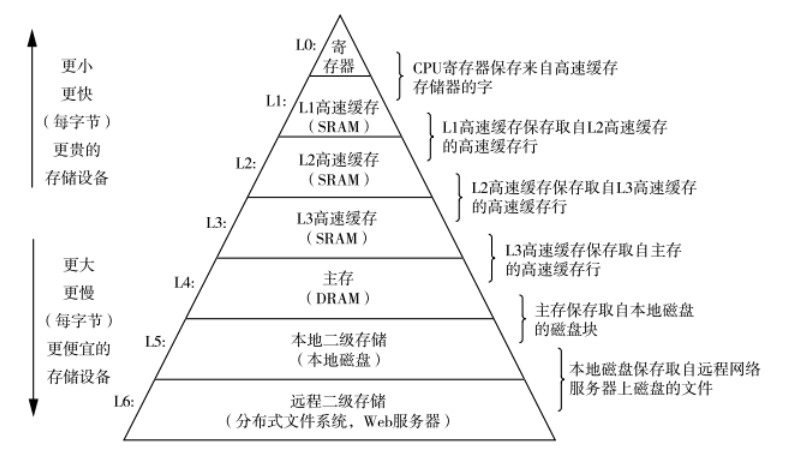
一个存储器层次大体结构如图所示,速度越快的存储设备自然价格也就越高,随着数据访问量的增大,单纯的增加一级缓存的成本太高,性价比太低,所以才有了二级缓存和三级缓存,他们的容量越来越大,速度越来越慢(但还是比内存的速度快),成本越来越低。
3. Cache的大小和速度如何?
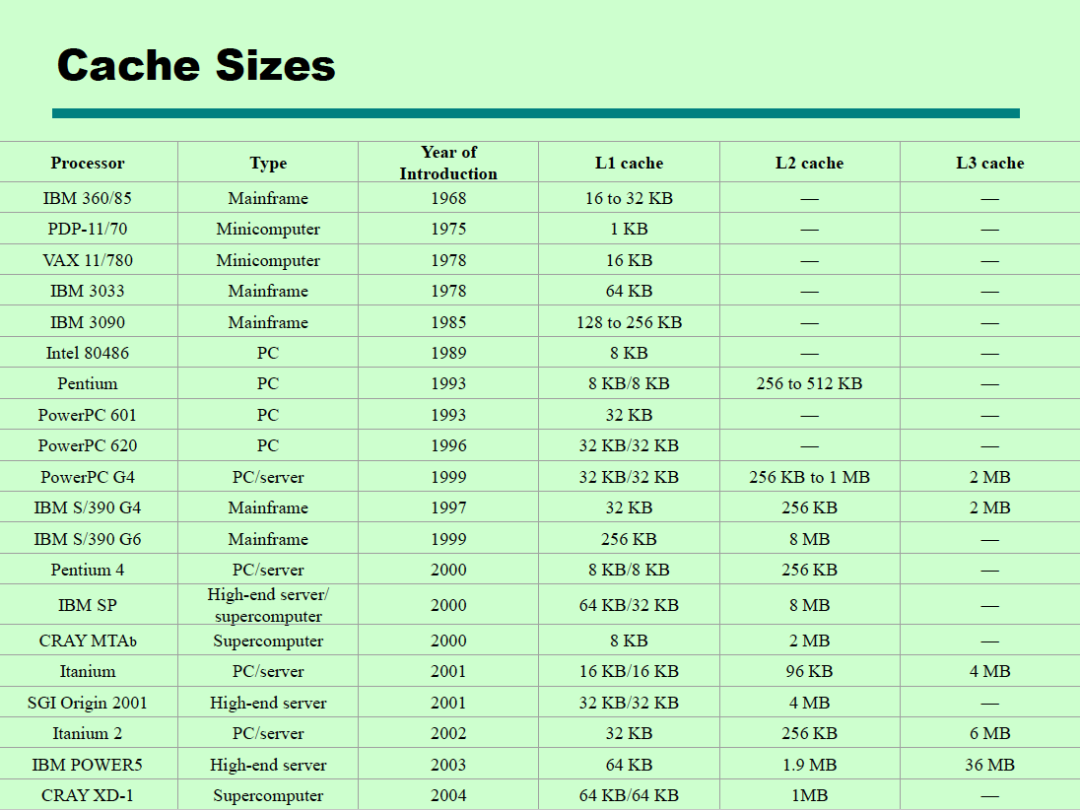
通常越接近CPU的缓存级别越低,容量越小,速度越快。不同的处理器Cache大小不同,通常现在的处理器的L1 Cache大小都是64KB。
那CPU访问各个Cache的速度如何呢?
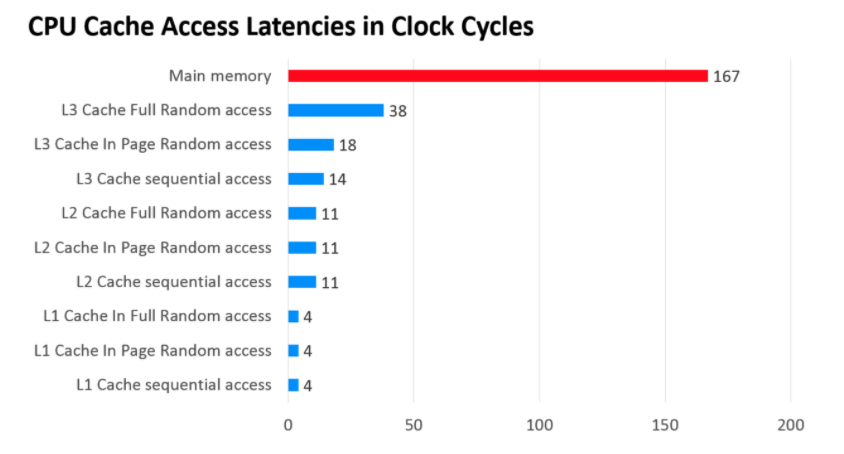
如图所示,级别越低的高速缓存,CPU访问的速度越快。
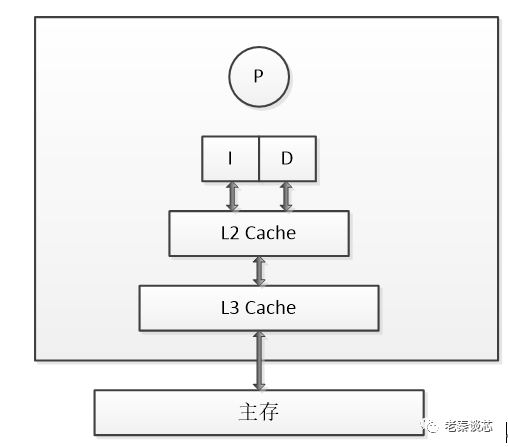
CPU多级缓存架构大体如下:
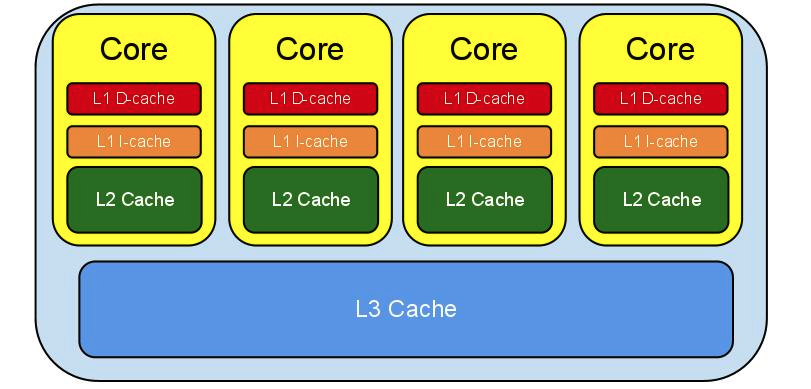
L1 Cache是最离CPU最近的,它容量最小,速度最快,每个CPU都有L1 Cache,见上图,其实每个CPU都有两个L1 Cache,一个是L1D Cache,用于存取数据,另一个是L1I Cache,用于存取指令。
L2 Cache容量较L1大,速度较L1较慢,每个CPU也都有一个L2 Cache。L2 Cache制造成本比L1 Cache更低,它的作用就是存储那些CPU需要用到的且L1 Cache miss的数据。
L3 Cache容量较L2大,速度较L2慢,L3 Cache不同于L1 Cache和L2 Cache,它是所有CPU共享的,可以把它理解为速度更快,容量更小的内存。
当CPU需要数据时,整体流程如下:
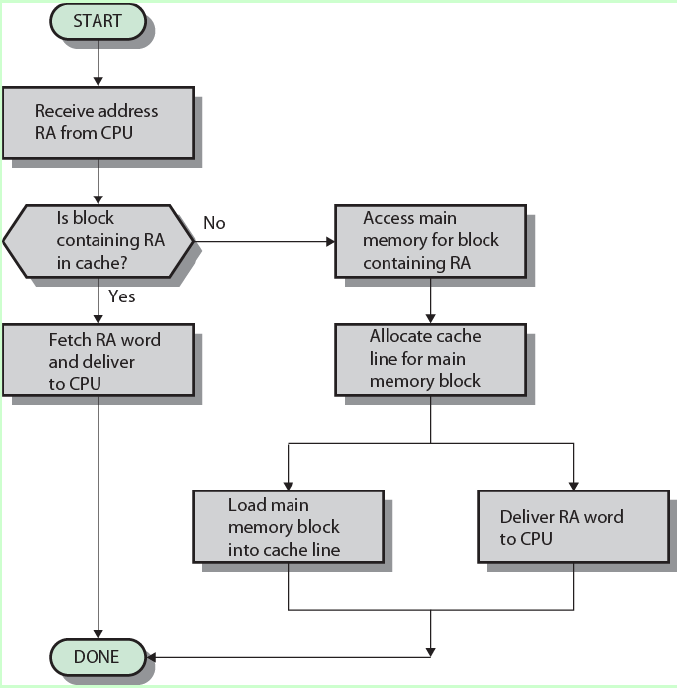
会最先去CPU的L1 Cache中寻找相关的数据,找到了就返回,找不到就去L2 Cache,再找不到就去L3 Cache,再找不到就从内存中读取数据,寻找的距离越长,自然速度也就越慢。
4. Cache Line?
Cache Line可以理解为CPU Cache中的最小缓存单位。Main Memory-Cache或Cache-Cache之间的数据传输不是以字节为最小单位,而是以Cache Line为最小单位,称为缓存行。 目前主流的Cache Line大小都是64字节,假设有一个64K字节的Cache,那这个Cache所能存放的Cache Line的个数就是1K个。
5. 写入策略
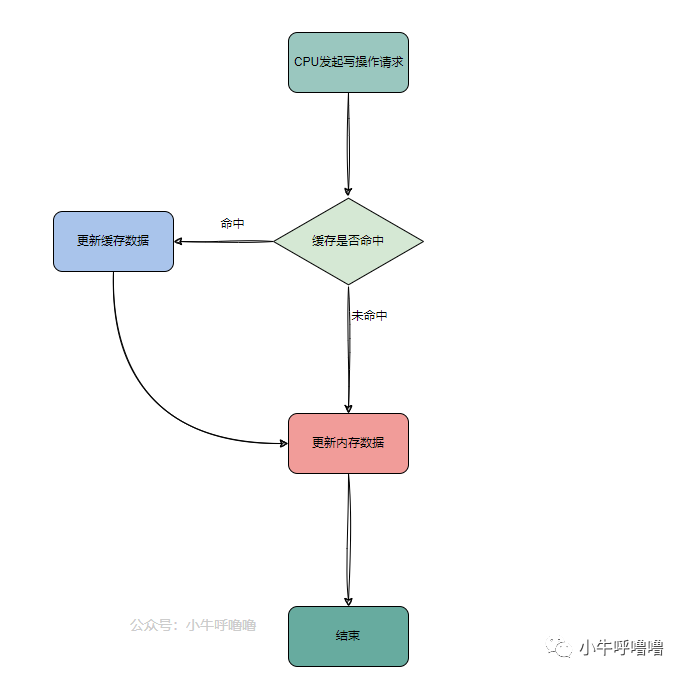
Cache的写入策略有两种,分别是WriteThrough(直写模式)和WriteBack(回写模式)。 直写模式:在数据更新时,将数据同时写入内存和Cache,该策略操作简单,但是因为每次都要写入内存,速度较慢。 回写模式:在数据更新时,只将数据写入到Cache中,只有在数据被替换出Cache时,被修改的数据才会被写入到内存中,该策略因为不需要写入到内存中,所以速度较快。但数据仅写在了Cache中,Cache数据和内存数据不一致,此时如果有其它CPU访问数据,就会读到脏数据,出现bug,所以这里需要用到Cache的一致性协议来保证CPU读到的是最新的数据。
6. 什么是Cache一致性呢?
多个CPU对某块内存同时读写,就会引起冲突的问题,被称为Cache一致性问题。
有这样一种情况:
a.CPU1读取了一个字节offset,该字节和相邻的数据就都会被写入到CPU1的Cache. b.此时CPU2也读取相同的字节offset,这样CPU1和CPU2的Cache就都拥有同样的数据。 c.CPU1修改了offset这个字节,被修改后,这个字节被写入到CPU1的Cache中,但是没有被同步到内存中。 d.CPU2 需要访问offset这个字节数据,但是由于最新的数据并没有被同步到内存中,所以CPU2 访问的数据不是最新的数据。
这种问题就被称为Cache一致性问题,为了解决这个问题大佬们设计了MESI协议,当一个CPU1修改了Cache中的某字节数据时,那么其它的所有CPU都会收到通知,它们的相应Cache就会被置为无效状态,当其他的CPU需要访问此字节的数据时,发现自己的Cache相关数据已失效,这时CPU1会立刻把数据写到内存中,其它的CPU就会立刻从内存中读取该数据。
MESI协议是通过四种状态的控制来解决Cache一致性的问题:
■M:代表已修改(Modified) 缓存行是脏的(dirty),与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S).
■E:代表独占(Exclusive) 缓存行只在当前缓存中,但是干净的(clean)--缓存数据同于主存数据。当别的缓存读取它时,状态变为共享(S);当前写数据时,变为已修改(M)状态。
■S:代表共享(Shared) 缓存行也存在于其它缓存中且是干净(clean)的。缓存行可以在任意时刻抛弃。
■I:代表已失效(Invalidated) 缓存行是脏的(dirty),无效的。
四种状态的相容关系如下:
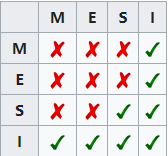
这里我们只需要知道它是通过这四种状态的切换解决的Cache一致性问题就好,具体状态机的控制实现太繁琐,就不多介绍了,这是状态机转换图,是不是有点懵。
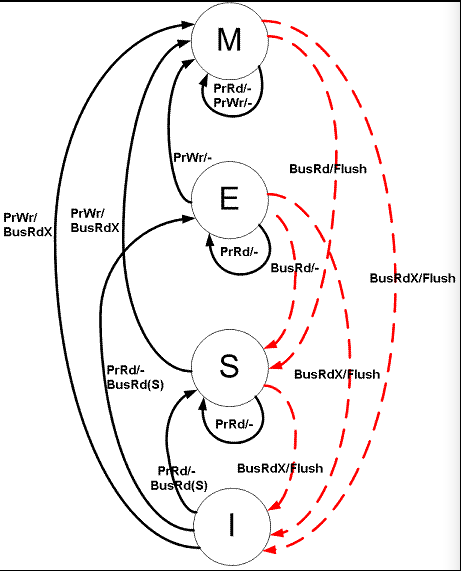
7. Cache与主存的映射关系?
直接映射

直接映射如图所示,每个主存块只能映射Cache的一个特定块。直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址转换速度快,但是这种方式不太灵活,Cache的存储空间得不到充分利用,每个主存块在Cache中只有一个固定位置可存放,容易产生冲突,使Cache效率下降,因此只适合大容量Cache采用。
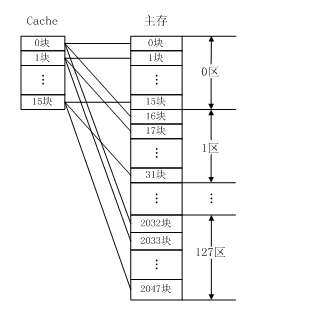
例如,如果一个程序需要重复引用主存中第0块与第16块,最好将主存第0块与第16块同时复制到Cache中,但由于它们都只能复制到Cache的第0块中去,即使Cache中别的存储空间空着也不能占用,因此这两个块会不断地交替装入Cache中,导致命中率降低。
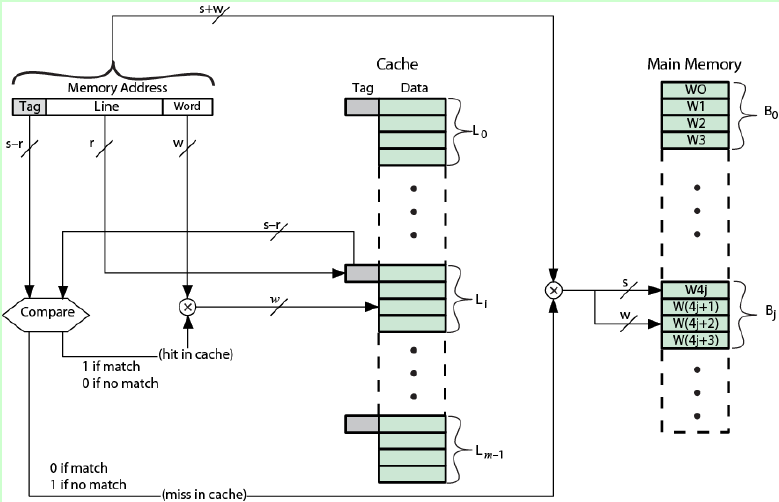
直接映射方式下主存地址格式如图,主存地址为s+w位,Cache空间有2的r次方行,每行大小有2的w次方字节,则Cache地址有w+r位。通过Line确定该内存块应该在Cache中的位置,确定位置后比较标记是否相同,如果相同则表示Cache命中,从Cache中读取。
全相连映射
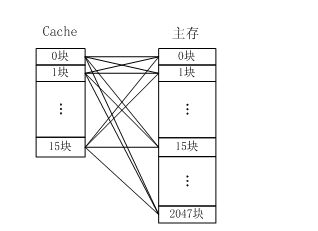
全相连映射如图所示,主存中任何一块都可以映射到Cache中的任何一块位置上。
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
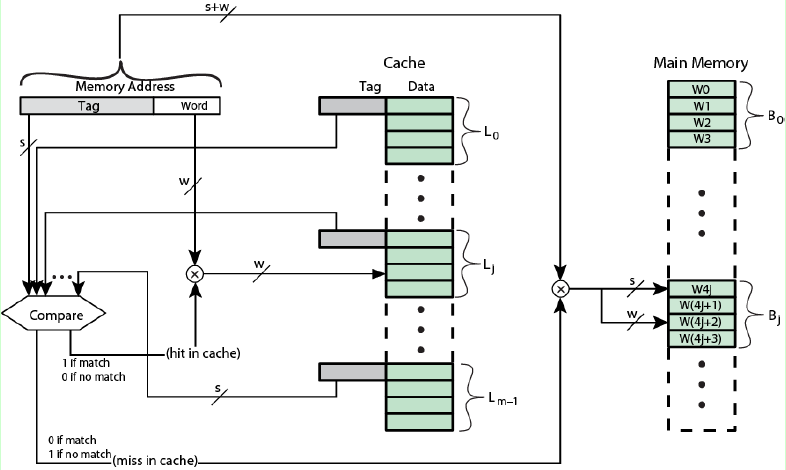
全相连映射的主存结构就很简单啦,将CPU发出的内存地址的块号部分与Cache所有行的标记进行比较,如果有相同的,则Cache命中,从Cache中读取,如果找不到,则没有命中,从主存中读取。
组相连映射
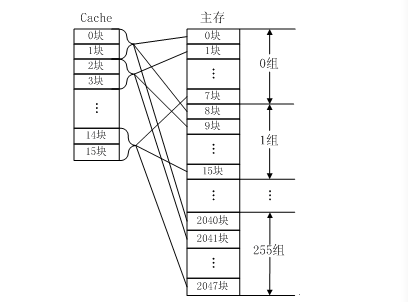
组相联映射实际上是直接映射和全相联映射的折中方案,其组织结构如图3-16所示。主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成u组,每组v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。例如,主存分为256组,每组8块,Cache分为8组,每组2块。
主存中的各块与Cache的组号之间有固定的映射关系,但可自由映射到对应Cache组中的任何一块。例如,主存中的第0块、第8块……均映射于Cache的第0组,但可映射到Cache第0组中的第0块或第1块;主存的第1块、第9块……均映射于Cache的第1组,但可映射到Cache第1组中的第2块或第3块。
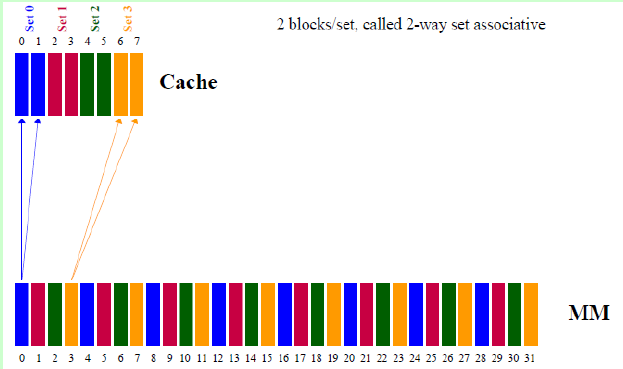
常采用的组相联结构Cache,每组内有2、4、8、16块,称为2路、4路、8路、16路组相联Cache。组相联结构Cache是前两种方法的折中方案,适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
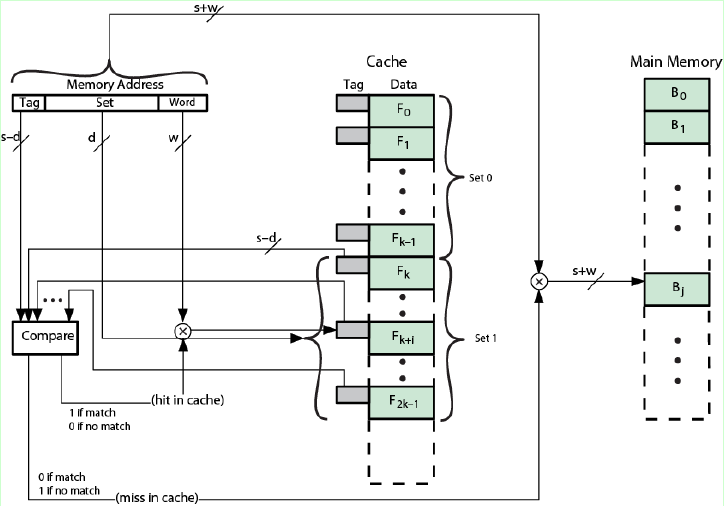
组相连映射方式下的主存地址格式如图,先确定主存应该在Cache中的哪一个组,之后组内是全相联映射,依次比较组内的标记,如果有标记相同的Cache,则命中,否则不命中。
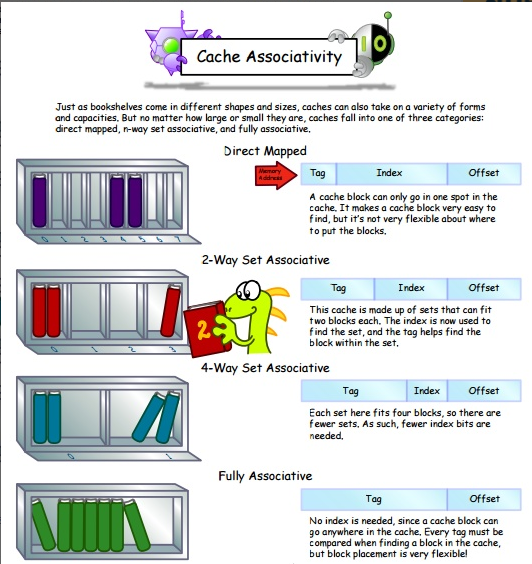
在网上找到了三种映射方式下的主存格式对比图,大家也可以看下:
8. Cache的替换策略?
Cache的替换策略想必大家都知道,就是LRU策略,即最近最少使用算法,选择未使用时间最长的Cache替换。
9. 如何巧妙利用CPU Cache编程?
constintrow=1024;
constintcol=1024;
intmatrix[row][col];
//按行遍历
intsum_row=0;
for(intr=0;r< row; r++) {
for (int c = 0; c < col; c++) {
sum_row += matrix[r][c];
}
}
//按列遍历
int sum_col = 0;
for (int c = 0; c < col; c++) {
for (int r = 0; r < row; r++) {
sum_col += matrix[r][c];
}
}
上面是两段二维数组的遍历方式,一种按行遍历,另一种是按列遍历,乍一看您可能认为计算量没有任何区别,但其实按行遍历比按列遍历速度快的多,这就是CPU Cache起到了作用,根据程序局部性原理,访问主存时会把相邻的部分数据也加载到Cache中,下次访问相邻数据时Cache的命中率极高,速度自然也会提升不少。
平时编程过程中也可以多利用好程序的时间局部性和空间局部性原理,就可以提高CPU Cache的命中率,提高程序运行的效率。
责任编辑:彭菁
-
处理器
+关注
关注
68文章
20332浏览量
255002 -
cpu
+关注
关注
68文章
11327浏览量
225893 -
Cache
+关注
关注
0文章
130浏览量
29790
原文标题:深入理解cache对写好代码至关重要
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
cpu与cache内存交互的过程
CPU Cache是如何保证缓存一致性的?
cache的应用——什么时候需要刷cache1
嵌入式CPU指令Cache的设计与实现
什么是缓存Cache
什么是Cache/SIMD?
什么是Instructions Cache/IMM/ID
高速缓存(Cache),高速缓存(Cache)原理是什么?
Buffer和Cache之间区别是什么?
cache的排布与CPU的典型分布
什么是 Cache? Cache读写原理
CPU Cache伪共享问题
CPU设计之Cache存储器



评论