 AI走入应用场景:底层算力如何建构?
AI走入应用场景:底层算力如何建构?

本文转载自《半导体行业观察》感谢《半导体行业观察》对新思科技的关注 如今,人工智能应用正在渗透入大众生活的方方面面,自动驾驶技术的行人检测、数码相机的图像质量增强、AI美颜、语音识别……这些人工智能应用的背后离不开硬件的支持。虽然神经网络处理器(NPU)在性能、效率和算法灵活性方面已优于可编程的DSP,但这并不意味着 AI 处理中不需要 DSP。恰恰相反,对于许多应用的AI子系统来说,神经网络处理器(NPU)与矢量DSP是绝佳组合。 哪些应用需要用到DSP?NPU和DSP该如何更好的配置?行业内是否有现成的解决方案可供选择?本文将针对这些问题一一进行讲解。
DSP在AI应用中发挥重要作用
从众多神经网络处理需求来看,例如卷积神经网络 (CNN) 或转换器,任何可以执行乘法运算并移动大量数据的处理器最终都可以执行这些计算密集型模型。借助先进的量化技术,经过训练的神经网络的32位浮点输出可以在 8 位整数控制器或处理器上运行,而且精度几乎没有降低。这意味着可以在 CPU、GPU、DSP 甚至MCU上处理CNN推理,准确度不受影响。
目前在行业内通常用TOPS(每秒万亿次运算)来衡量AI处理器的性能,也称之为“算力”。TOPS 的计算方式为:一个周期内可以完成的运算次数(一次乘积累加视为两次运算)x最大频率。这是很好的首次性能估算,因为大部分计算由对矩阵乘法的需求驱动,而矩阵乘法需要乘积累加运算。
按照这种计算方法,让我们来看下不同处理器类型的理想TOPS。具有DSP扩展的CPU可以每个时钟周期执行一次乘积累加 (MAC) 并以 2GHz的速度运行,其运算能力为:2GHz x 2次运算(包括乘积和累加)x 1 MAC/周期 = 4 GOPS 或 0.004 TOPS(1TOPS等于1000 GOPS)。以此类推,矢量DSP的理想TOPS为1.2,高端的NPU将达到255.6 TOPS。如表1中所示,从理想的算力能力上来看,神经处理单元 (NPU) 是获得最高计算能力的最佳选择。
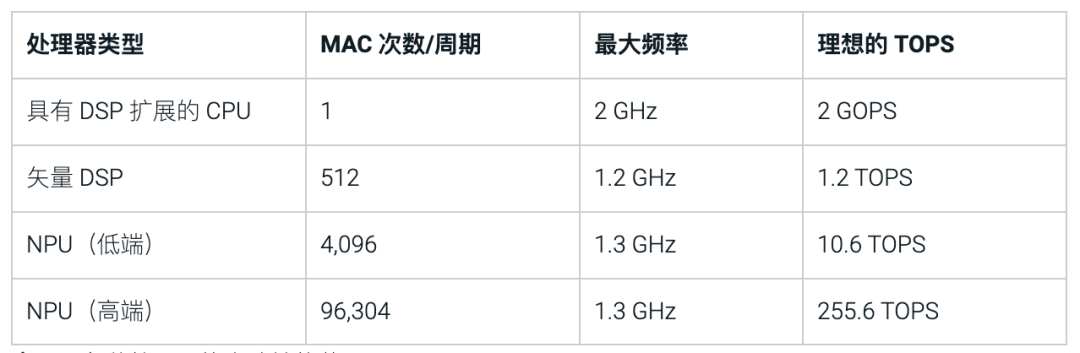
▲表1:各种处理器的大致性能范围
诚然,计算能力固然重要,但一些应用对实时性能的要求也很高。如在汽车应用中,当一辆汽车以 70 英里/小时的速度冲向行人,需要迅速决定是否要刹车。多摄像头配置、高分辨率、最低延迟,这些因素都对计算效率提出了更高要求,以帮助汽车做出生死攸关的决定。因此,我们需要更谨慎地选择用于处理AI推理的处理器。
GPU在AI计算中也可以提供高性能,但由于其功耗和面积成本很高,对于实时应用来说难以接受,所以并未在上表中列出。事实上,上表中所列的每种处理器都需要不同级别的功率和面积才能达到所需的运算能力。对于实时应用来说,功耗和面积(与成本和可制造性直接相关)几乎与性能同样重要。理论上来说,NPU经过设计和优化,是执行神经网络算法时性能、功耗和面积效率最高的处理器。
但是,并非每个AI应用都需要NPU提供的最高级别的神经网络性能。如下图1所示,不同的AI应用涵盖从几GOPS到数千TOPS的各种性能要求。当你的AI应用所需算力小于1 TOPS时,具有DSP扩展的CPU或者矢量DSP是比较理想的选择;而当算力要求高于1 TOPS时,NPU的 AI 性能效率、功耗效率和面积效率毋庸置疑。
NPU 的最佳效率来自每个周期可以完成的大量乘积,以及一些专用于其他神经网络运算(例如激活函数)的硬件。NPU 面临的挑战是如何实现最大硬件加速,从而最大限度地提高神经网络效率,还要保持一定程度的可编程性。虽然现在全硬件神经网络ASIC比可编程 NPU更高效,但AI技术发展迅速,AI SoC的生产周期很长,因此保持一定程度的可编程性至关重要。
而且,NPU是专用的神经处理器引擎,只能执行AI计算。如果将矢量DSP和NPU结合使用,利用矢量DSP对NPU进行支持,就可以提供最高性能和额外的可编程性。例如,在自动驾驶汽车中,需要利用NPU来寻找行人、识别街道标志、使用神经网络进行雷达处理,在这些多应用处理中,系统可利用矢量DSP来为NPU进行额外筛选、雷达或LiDAR处理以及预处理和后处理。
NPU+DSP的三种配置方式
图2显示了在 AI 应用中将NPU和矢量DSP结合使用的各种可能性。在图中所示的三种情况下,高分辨率图像帧位于DDR内存中,等待在下一帧到达之前得到处理。
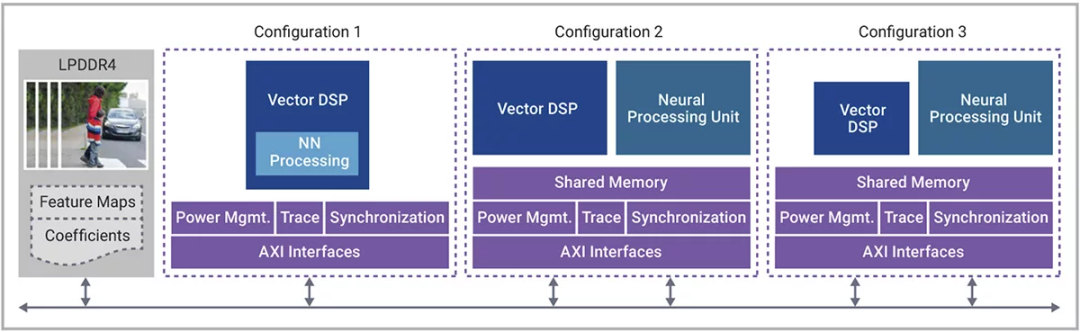
▲图2:矢量DSP和神经网络性能的不同组合
在第一种配置中(左侧),矢量 DSP本身既可用于DSP处理也可用于一部分AI处理,这属于运算能力低于 1 TOPS 的用例,这种配置需要大型DSP+小型AI。这种配置的具体示例是为永磁同步电机 (PMSM) 执行无传感器磁场定向控制 (FOC) 的矢量 DSP。基于 DSP 的电机控制通过 AI 处理实现扩展,AI 处理的作用是执行位置监控,并将相关信息反馈到控制回路。AI 模型的采样率和计算复杂性使其能够与矢量DSP的AI功能相适应。
在第二种配置中(中间),AI SoC 需要很高的矢量DSP性能和AI 性能,这种配置是大型 AI+大型 DSP。当矢量DSP处理高度依赖DSP的任务时,需要用NPU为AI密集型任务提供的神经网络加速作为补充。数码相机就是这种配置,矢量 DSP 可以对 NPU 执行视觉处理以及预处理和后处理支持,而 NPU 则专用于对高分辨率图像进行 CNN 或转换器处理(对象检测、语义分割、超分辨率等)。这些用例需要紧密集成的矢量 DSP 和 NPU 解决方案,而且可进行扩展以适应性能目标。
第三个配置是小型 DSP+大型 AI。所有的处理都集中在神经网络上,虽然这些神经网络通常可以在 NPU 中执行,但有一些更复杂的神经网络模型需要矢量 DSP 的支持来执行浮点运算,如Mask-RCNN 的 ROI 池化和 ROI 对齐,或 Deeplab v3 使用的非整数比例因子。即使 AI SoC 不需要任何额外的 DSP 处理,纳入一定程度的矢量 DSP 性能来支持 NPU 还是有好处的,这可以更好地适应未来的发展需求。
新思科技ARC EV7x能够实现
矢量DSP和NPU紧密耦合
虽然市场上有多种矢量DSP和NPU供选择,但对于第二种和第三种配置,最好选择包含紧密集成处理器的 AI 解决方案。一些神经网络加速器将矢量DSP嵌入到神经网络解决方案中,这样限制了矢量DSP用于外部编程。
而新思科技的ARC EV7x 视觉处理器是异构处理器,它将矢量DSP与可选的神经网络引擎紧密耦合。为了提高客户的灵活性和可编程性,ARC EV7x系列正在发展成为 ARC VPX 矢量 DSP 系列和 ARC NPX NPU 系列。VPX 和 NPX 是紧密耦合的 AI 解决方案。图 3 显示了这两种处理器的粗略框图及其互连方式。
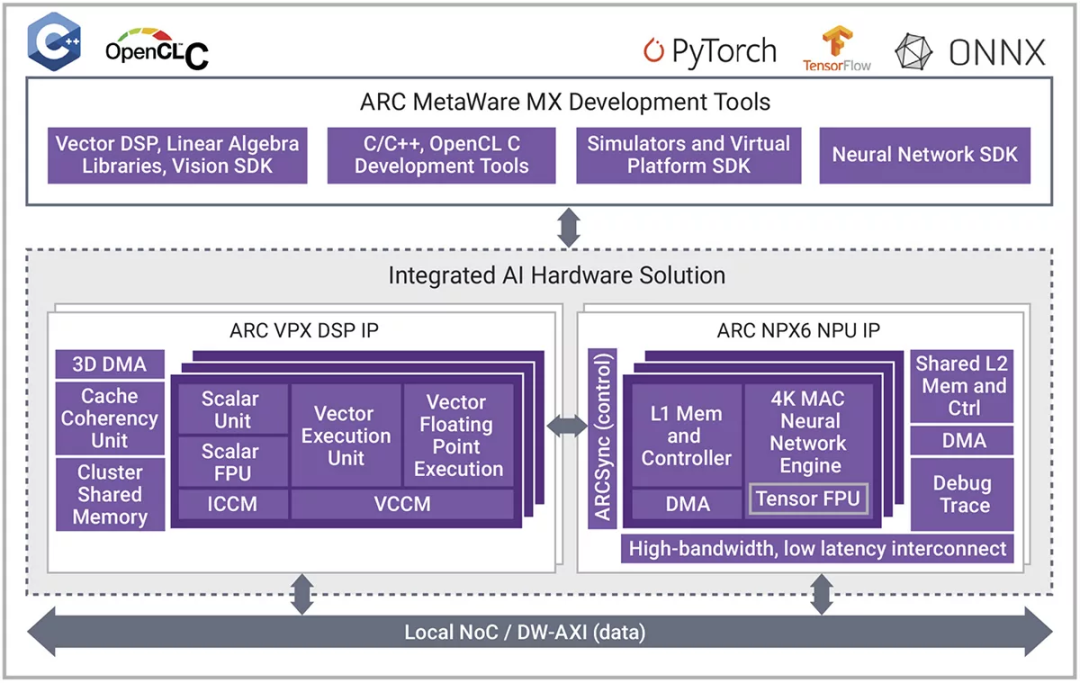
▲图3:新思科技 ARC VPX5 和 ARC NPX6 的紧密耦合型组合
ARC VPX DSP IP在基于超长指令字 (VLIW)/单指令多数据 (SIMD) 架构的并行 DSP 处理方面表现出色,并针对嵌入式工作负载的功耗、性能和面积 (PPA) 要求进行了优化。可将 VPX 系列配置为支持浮点和多种整数格式(包括用于 AI 推理的 INT8 运算)。VPX 系列在 128 位(VPX2、VPX2FS)、256 位(VPX3、VPX3FS)和 512 位(VPX5、VPX5FS)矢量字上运行,因此可提供多种性能,还可以从单核扩展到四核。这样可以每个周期提供 16 个 INT8 MAC 至 512 个 INT8 MAC(在四核 VPX5 上使用双 MAC 配置)。
ARC NPX NPU IP专用于 NN 处理,还针对实时应用的 PPA 要求进行了优化。该系列从每个周期 4096 个 MAC 的版本扩展到每个周期 96000 个 MAC 的版本,然后可以扩展到多个实例。NXP6 系列在单个 SoC 上的 AI 性能可从 1 TOPS 扩展到 1000 TOPS。它还针对 CNN 的最新神经网络模型和新兴的转换器模型类别进行了优化。
如图 3 所示,VPX 和 NPX 系列紧密集成。ARCsync 是额外的 RTL,可在处理器之间提供中断控制。数据通过外部 NOC 或 AXI 总线传递,这类总线通常已在 SoC 系统中存在。虽然两个处理器可以完全独立运行,但 VPX5 能够根据需要访问 NPX6 的 L2 内存。
通用软件开发工具链 ARC MetaWare MX 也支持 VPX5 和 NPX6 的紧密集成,该工具链支持 NXP 和 VPX 的任意组合。SoC 架构师可以使用这些可扩展处理器系列选择 DSP 性能和 AI 性能的正确组合,以最大限度地提高性能并减少面积开销。对于高度依赖 AI 的工作负载,“大型 AI,小型 DSP”配置的经验法则是,每 8000 或 16000 个 MAC 为 NPX 配备一个 VPX5(具体取决于模型和工作负载)。对于 NPX6-64K 配置,建议至少使用四个 VPX5 内核。
结语
诚然,对于特定任务(例如行人对象检测),神经网络处理已经取代了 DSP 处理,但矢量 DSP 的 SIMD 功能与 DSP 支持功能和 AI 支持功能相结合,可使其成为 AI 系统的重要组成部分。随着嵌入式应用对 AI 处理的需求持续增长,要实现灵活设计,建议的最佳做法是结合使用 NPU 和矢量 DSP,前者用于AI处理,后者用于提供对NPU支持和DSP处理,这样有助于为快速发展的AI提供具有前瞻性的AI SoC。
-
新思科技
+关注
关注
5文章
979浏览量
52988
原文标题:AI走入应用场景:底层算力如何建构?
文章出处:【微信号:Synopsys_CN,微信公众号:新思科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
GTC 2026引爆AI算力新浪潮,芯联集成如何为万亿AI算力注入能源动力

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值


国产AI芯片真能扛住“算力内卷”?海思昇腾的这波操作藏了多少细节?
什么是AI算力模组?

什么是AI算力模组?

睿海光电领航AI光模块:超快交付与全场景兼容赋能智算时代——以创新实力助力全球客户构建高效算力底座
算力之后看存力,英韧科技洞庭-N3X SSD推动AI和边缘计算存储升级

EASY-EAI携手Hailo,推出高性能、高算力的边缘AI硬件组合


腾视科技TS-NV-P100系列AI边缘算力盒子综合算力高达157TOPS:重新定义AI边缘算力,赋能千行百业智能化升级
AI驱动智慧交通:加速应用场景落地
算力革命:RoCE实测推理时延比InfiniBand低30%的底层逻辑



评论