 一文看懂AI算力集群
一文看懂AI算力集群

最近这几年,AI浪潮席卷全球,成为整个社会的关注焦点。大家在讨论AI的时候,经常会提到AI算力集群。AI的三要素,是算力、算法和数据。而AI算力集群,就是目前最主要的算力来源。它就像一个超级发电厂,可以给AI浪潮提供源源不断的动力。那么,AI算力集群,到底是由哪些东西组成的呢?它为什么能够提供澎湃的算力?它的内部结构又是怎样的呢?包括了哪些关键技术?接下来,小枣君就通过这篇文章,给大家做一个全面梳理。
什么是AI算力集群?
AI算力集群,顾名思义,就是能够为AI计算任务提供算力的集群系统。集群,英文是cluster,指的是一组相互独立的、通过高速网络互联的设备。
网上也有定义指出,AI算力集群,指的是“通过高速网络,将大量高性能计算节点(如GPU/TPU服务器)互联,从而形成的一种分布式计算系统。”此前小枣君给大家介绍AI智算的时候说过,所谓AI智算,无非就是训练和推理两大任务。训练的计算量大、难度高,对算力的要求也高。推理的计算量相对较小,难度相对较低,对算力的要求也低。无论是训练和推理,都涉及到大量的矩阵运算(如卷积、张量乘法)任务。这些计算天然可以分解为独立子任务进行并行处理。所以,擅长并行计算的GPU、NPU、TPU等芯片,就成为了AI计算的主要工具。这些芯片也被统称为AI芯片。AI芯片是提供AI算力的最基本单元。单个芯片是没办法工作的,需要集成在电路板上。于是,将AI芯片嵌入在手机主板上,或者直接集成到手机SoC主芯片上,就可以为手机提供AI算力。集成在物联网设备模组上,就可以为物联网设备(汽车、机械臂、AGV无人车、摄像头等)提供AI算力。这些是端侧算力。将AI芯片集成在基站、路由器、网关等设备里,就是边缘侧算力。这些设备体积小,AI芯片就1个,算力很弱,主要完成一些推理计算任务。想要完成更为复杂的训练任务,就需要一个能搭载更多AI芯片的硬件平台。将AI芯片做成AI算力板卡,然后在一个服务器里塞入多块AI算力板卡,就打造出了AI服务器。世上本没有AI服务器。普通服务器里多塞入几个AI算力板卡,就变成了AI服务器。一般来说,AI服务器是一机八卡。如果你硬要塞的话,有的最多也可以塞二十卡。但是,限于散热和功耗,想要塞入更多,就不太现实了。此时的AI服务器,算力又提升了一个数量级。完成推理任务,更加驾轻就熟。一些简单的训练任务(小模型),它也可以勉强胜任。今年崛起的DeepSeek大模型,因为在架构和算法上进行了优化,大幅降低了对算力的要求。所以,就有很多厂商,搞了那种单机架的计算设备(包括若干台AI服务器、存储、电源等),并将其命名为“一体机”,可以满足很多行业企业用户DeepSeek大模型私有化部署的需求,卖得热火朝天。不管是AI服务器还是一体机,AI算力仍然是有限的。针对真正的海量参数(千亿级、万亿级)大模型训练,仍然需要更强劲的AI算力。于是,就要打造包括更多AI芯片的系统,也就是真正的大规模AI算力集群。现在我们经常会听说所谓“万卡规模”、“十万卡规模”,意思就是说,要打造的目标AI算力集群,需要一万块、十万块AI算力板卡(AI芯片)。这该怎么办呢?答案很简单,就是Scale Up和Scale Out。
什么是Scale Up?
Scale,是扩展的意思。搞过云计算的同学,对这个词肯定不陌生。
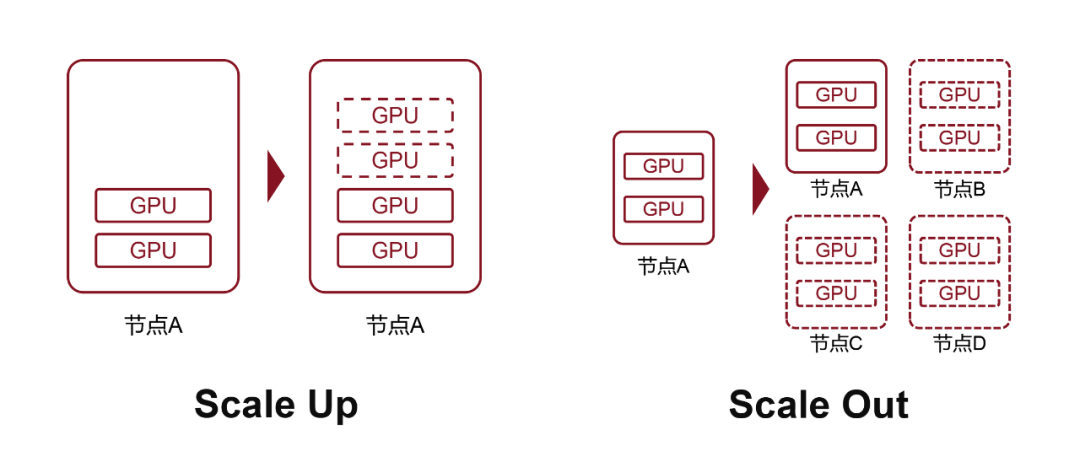
Scale Up,是向上扩展,也叫纵向扩展,增加单节点的资源数量。
Scale Out,是向外扩展,也叫横向扩展,增加节点的数量。
在云计算领域,还有和Scale Up对应的Scale Down(纵向缩减),以及和Scale Out对应的Scale In(横向缩减)。
前面提到的,在每台服务器里多塞几块AI算力板卡,这就是Scale Up。这时,一台服务器就是一个节点。
通过通信网络,将多台电脑(节点)连接起来,这就是Scale Out。
Scale Up和Scale Out最主要的区别,在于AI芯片之间的连接速率。
Scale Up是节点内部连接。它的连接速率更高,时延更低,性能更强劲。
以前,计算机内部元件之间的通信主要基于PCIe协议。这个协议诞生于上世纪80-90年代PC刚刚普及的时候。虽然协议后来也有升级,但升级速度缓慢,数据传输速率和时延根本无法满足要求需求。
于是,2014年,英伟达专门推出了NVLINK总线协议。NVLINK允许GPU之间以点对点方式进行通信,速度远高于PCIe,时延也低得多。
NVLINK原本只用于机器内部通信。2022年,英伟达将NVSwitch芯片独立出来,变成了NVLink交换机,用于连接服务器之间的GPU设备。
这意味着,节点已经不再仅限于1台服务器了,而是可以由多台服务器和网络设备共同组成。
这些设备处于同一个HBD(High Bandwidth Domain,超带宽域)。英伟达将这种以超大带宽互联16卡以上GPU-GPU的Scale Up系统,称为超节点。
历经多年的发展,NVLINK已经迭代到第五代。每块GPU拥有18个NVLink连接,Blackwell GPU的总带宽可达到1800GB/s,远远超过PCIe Gen6的总线带宽。
2024年3月,英伟达发布了NVL72,可以将36个Grace CPU和72个Blackwell GPU集成到一个液冷机柜中,实现总计720 Pflops的AI训练性能,或1440 Pflops的推理性能。
英伟达是AI计算领域毫无疑问的领军者。他们有最受欢迎的AI芯片(GPU)和软件生态(CUDA),也探索出了最有效的Scale Up实现方式。后来,随着AI的不断发展,越来越多的企业也开始推出AI芯片。因为NVLINK是私有协议,所以,这些推出AI芯片的企业,也要研究如何搭建自己的AI算力集群。英伟达海外的主要竞争对手之一,AMD公司,推出了UA LINK。国内的腾讯、阿里、中国移动等企业,也牵头推出了ETH-X、ALS、OISA等项目。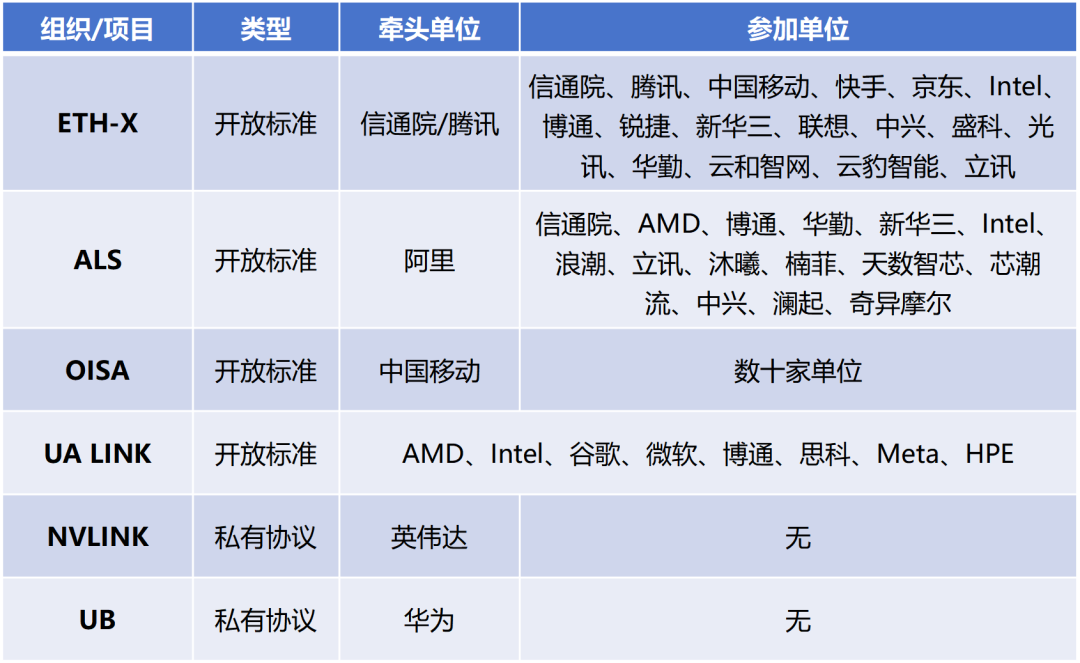 这些都是开放标准,成本比私有协议更低,也有利于降低行业门槛,帮助实现技术平权,符合互联网开放解耦的发展趋势。值得一提的是,这些标准基本上都是以以太网技术(ETH)为基础。因为以太网技术最成熟、最开放,拥有很好的产业链基础。
这些都是开放标准,成本比私有协议更低,也有利于降低行业门槛,帮助实现技术平权,符合互联网开放解耦的发展趋势。值得一提的是,这些标准基本上都是以以太网技术(ETH)为基础。因为以太网技术最成熟、最开放,拥有很好的产业链基础。
另一个非常值得关注的技术路线,就是华为的私有协议UB(Unified Bus)。
最近几年,华为一直在打造昇腾生态。昇腾是华为的AI芯片,目前发展到了昇腾910C。他们也需要自己的AI算力集群解决方案,最大程度地发挥910C的能量,也为市场推广铺平道路。
今年4月,华为高调发布CloudMatrix384超节点,集成了384张昇腾910C算力卡,可提供高达300 Pflops的密集BF16算力,接近达到英伟达GB200 NVL72系统的两倍。

华为CloudMatrix 384超节点(来自华为云生态大会)
CloudMatrix384,就采用了UB技术。准确来说,CloudMatrix384包括了三个不同的网络平面,分别是UB平面、RDMA平面和VPC平面。
三个平面互补,实现了CloudMatrix384极强的卡间通信能力,也实现了整个超节点的算力提升。限于篇幅,具体技术细节下次再单独介绍。
需要再说明一下,面对开放标准的竞争压力,英伟达前段时间公布了NVLink Fusion计划,向8家合作伙伴开放了其NVLink技术,以帮助他们构建通过将多个芯片连接在一起的定制AI系统。
但是,根据一些媒体的报道,其中一些关键的NVLink组件仍然是未开放的,英伟达还是没有那么爽快。
什么是Scale Out?
再来看看Scale Out。
Scale Out,其实就接近于我们传统意义上的数据通信网络了。把传统服务器连接起来的技术,包括胖树架构、叶脊网络架构那些,还有TCP/IP、以太网那些技术,都是Scale Out的基础。
当然了,AI智算对网络性能的要求很高,所以,传统技术也要升级,才能满足条件。
目前,Scale Out主要采用的通信网络技术,是Infiniband(IB)和RoCEv2。
这两个技术都是基于RDMA(远程直接内存访问)协议,拥有比传统以太网更高的速率、更低的时延,负载均衡能力也更强。
IB当年也是为了取代PCIe而推出的技术,后来起起伏伏,掌握这项技术的Mellanox(迈络思)公司被英伟达收购。IB也变成了英伟达的私有技术。这个技术性能是真好,但价格也是真贵。它是英伟达算力布局的重要组成部分。
RoCEv2,则是开放标准,是传统以太网融合RDMA的产物,也是产业界为了对抗IB一家独大所推出的产物。它的价格便宜,和IB的性能差距也在不断缩小。
比起Scale Up领域的多个标准,Scale Out目前标准相对集中,主要就是RoCEv2,路线非常清晰。毕竟,Scale Up是节点内,和芯片产品强相关。Scale Out是节点外,更强调兼容性。
前面我说了,Scale Up和Scale Out最主要的区别在于速率带宽。
IB和RoCEv2仅能提供Tbps级别的带宽。而Scale Up,能够实现数百个GPU间10Tbps带宽级别的互联。
在时延方面,Scale Up和Scale Out也有很大的差距。IB和RoCEv2的时延高达10微秒。而Scale Up对网络时延的要求极为严苛,需要达到百纳秒(100纳秒=0.1微秒)级别。
在AI训练过程中,包括多种并行计算方式,例如TP(张量并行)、 EP(专家并行)、PP(流水线并行)和DP(数据并行)。
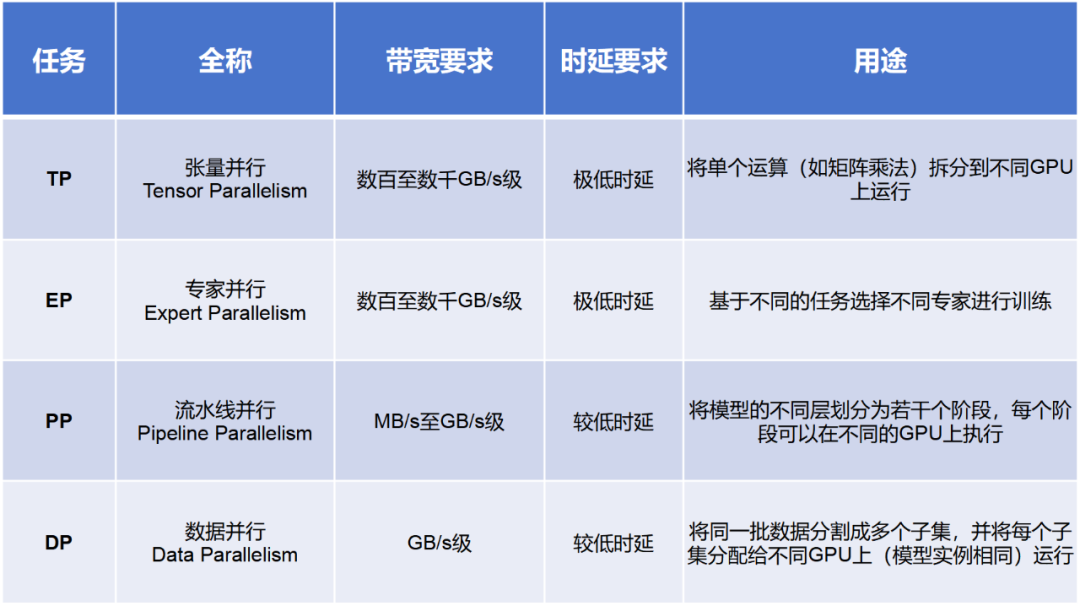
通常来说,PP和DP的通信量较小,一般交给Scale Out搞定。而TP和EP的通信量大,需要交给Scale Up(超节点内部)搞定。
超节点,作为Scale Up的当前最优解,通过内部高速总线互连,能够有效支撑并行计算任务,加速GPU之间的参数交换和数据同步,缩短大模型的训练周期。
超节点一般也都会支持内存语义能力,GPU之间可以直接读取对方的内存,这也是Scale Out不具备的。
站在组网和运维的角度来看,更大的Scale Up也有明显优势。
超节点的HBD(超带宽域)越大,Scale Up的GPU越多,Scale Out的组网就越简单,大幅降低组网复杂度。
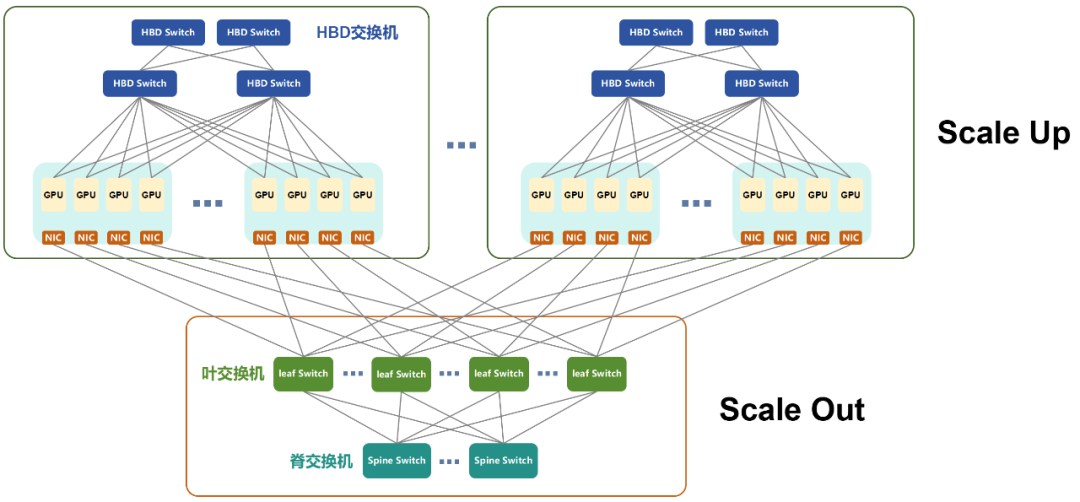
Scale Up & Scale Out组网示意图
Scale Up系统是一个高度集成的小型集群,内部总线已经连好。这也降低了网络部署的难度,缩短了部署周期。后期的运维,也会方便很多。
当然,Scale Up也不能无限大,也要考虑本身的成本因素。具体的规模,需要根据需求场景进行测算。
概括来说,Scale Up和Scale Out,就是性能和成本之间的平衡。随着时间的推移和技术的进步,以后肯定还会出现更大规模的超节点。Scale Up和Scale Out之间的边界,也会越来越模糊。
前面提到的ETH-X等开放Scale Up标准,都是基于以太网技术。从技术的角度来看,以太网具有最大交换芯片容量(单芯片51.2T已商用)、最高速Serdes技术(目前达到112Gbps),交换芯片时延也很低(200ns),完全可以满足Scale Up的性能要求。
Scale Out也是基于以太网。这不就大一统了么?
AI算力集群的发展趋势
最后,我再来说说AI算力集群的一些趋势动向。
目前看来,AI算力集群体现出这么几个趋势:
1、物理空间的异地化。
AI算力集群正在向万卡、十万卡方向发展。英伟达NVL72的1个机架有72颗芯片,华为CM384的16个机架有384颗芯片。华为基于CM384搞十万卡,需要432套(384×432=165888),那就是6912个机架。
对于单体数据中心来说,很难容纳下这么多机架。电力供应也会成为问题。
所以,现在业界在探索异地数据中心共同组成AI算力集群,协力完成AI训练任务。这个非常考验长距离、大带宽、低时延的DCI光通信技术,会加速空芯光纤等前沿技术的应用。
2、节点架构的定制化。
我们刚才介绍AI集群,都是在讨论如何把海量的AI芯片给“聚集起来”。其实,AI算力集群除了堆芯片数量之外,越来越看重架构的深度设计。
计算资源(GPU、NPU、CPU,甚至包括内存、硬盘)的池化,成为趋势。集群需要充分适配AI大模型的架构(例如MoE架构),提供定制性的设计,才能更好地完成计算任务。
换言之,单纯提供AI芯片是不够的,还要提供量体裁衣的设计。
3、运维能力的智能化。
大家都听说过,AI大模型训练容易出错。严重的时候,几个小时就错一次。错了就要重新算,非常耽误事,不仅拉长了训练周期,也增加了训练成本。
所以,企业在打造AI算力集群的时候,越来越关注系统的可靠性和稳定性。引入各种AI技术,对潜在故障进行预判,对亚健康设备或模块进行提前替换,成为一种趋势。
这些技术有利于降低故障率和中断率,增强系统稳定性,也等于是变相提升了算力。
4、算力的绿色化。AI智算需要消耗大量的算力,也会产生很高的能耗,所以目前各大厂商都在努力研究如何降低AI智算集群的能耗,提升绿色能源的使用比例,这也有利于AI智算的长远发展。我们国家的东数西算战略,其实也是出于这方面的目的。
好啦,以上就是关于AI算力集群的介绍。应该是非常全面且具体了,不知道大家都看懂了没?
文章来源于鲜枣课堂,作者小枣君
-
高速网络
+关注
关注
0文章
18浏览量
7091 -
AI算力
+关注
关注
1文章
169浏览量
10033
发布评论请先 登录
万卡集群解决大模型训算力需求,建设面临哪些挑战

DeepSeek推动AI算力需求:800G光模块的关键作用
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值


摩尔线程发布全功能GPU算力集群的异地算力调度方案

从千卡集群卡到万卡集群,燧原科技打造更好的AI算力底座

【一文看懂】什么是端侧算力?

热插拔算力集群

华为领衔,三剑客入局!十万卡智算集群落地,国产算力芯片强势崛起




评论